 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReducing Tool Hallucination via Reliability Alignment
Dec 05, 2024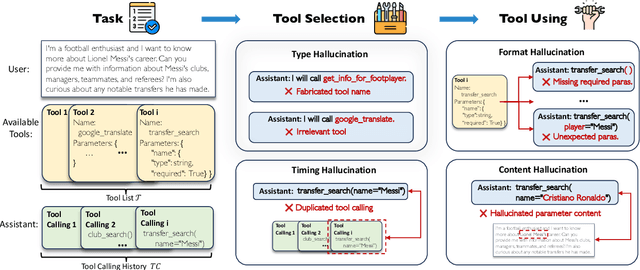
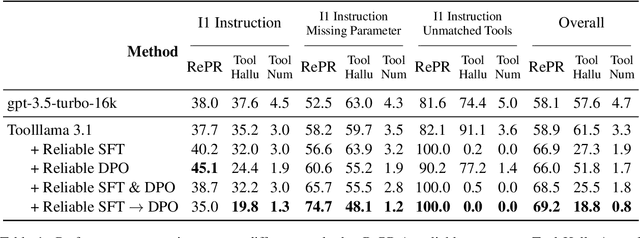
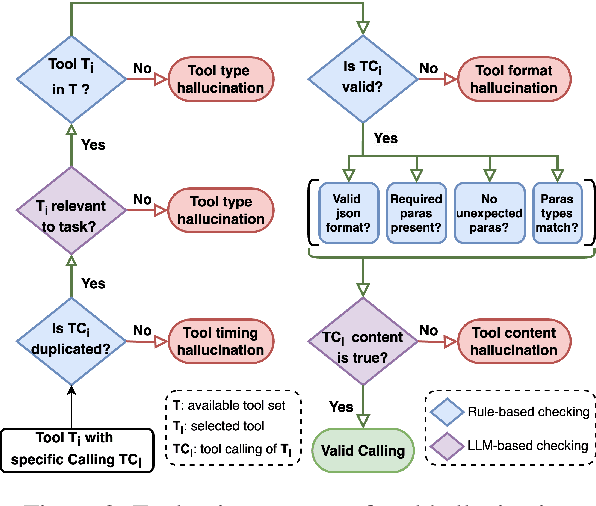
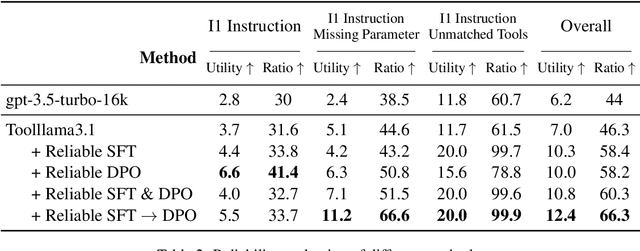
Large Language Models (LLMs) have extended their capabilities beyond language generation to interact with external systems through tool calling, offering powerful potential for real-world applications. However, the phenomenon of tool hallucinations, which occur when models improperly select or misuse tools, presents critical challenges that can lead to flawed task execution and increased operational costs. This paper investigates the concept of reliable tool calling and highlights the necessity of addressing tool hallucinations. We systematically categorize tool hallucinations into two main types: tool selection hallucination and tool usage hallucination. To mitigate these issues, we propose a reliability-focused alignment framework that enhances the model's ability to accurately assess tool relevance and usage. By proposing a suite of evaluation metrics and evaluating on StableToolBench, we further demonstrate the effectiveness of our framework in mitigating tool hallucination and improving the overall system reliability of LLM tool calling.
Compressing KV Cache for Long-Context LLM Inference with Inter-Layer Attention Similarity
Dec 03, 2024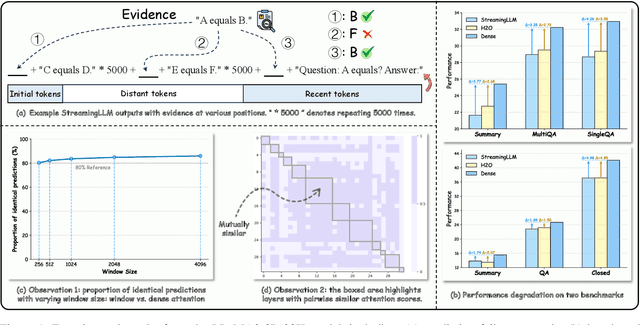



The increasing context window size in Large Language Models (LLMs), such as the GPT and LLaMA series, has improved their ability to tackle complex, long-text tasks, but at the cost of inference efficiency, particularly regarding memory and computational complexity. Existing methods, including selective token retention and window-based attention, improve efficiency but risk discarding important tokens needed for future text generation. In this paper, we propose an approach that enhances LLM efficiency without token loss by reducing the memory and computational load of less important tokens, rather than discarding them.We address two challenges: 1) investigating the distribution of important tokens in the context, discovering recent tokens are more important than distant tokens in context, and 2) optimizing resources for distant tokens by sharing attention scores across layers. The experiments show that our method saves $35\%$ KV cache without compromising the performance.
SciDFM: A Large Language Model with Mixture-of-Experts for Science
Sep 27, 2024



Recently, there has been a significant upsurge of interest in leveraging large language models (LLMs) to assist scientific discovery. However, most LLMs only focus on general science, while they lack domain-specific knowledge, such as chemical molecules and amino acid sequences. To bridge these gaps, we introduce SciDFM, a mixture-of-experts LLM, which is trained from scratch and is able to conduct college-level scientific reasoning and understand molecules and amino acid sequences. We collect a large-scale training corpus containing numerous scientific papers and books from different disciplines as well as data from domain-specific databases. We further fine-tune the pre-trained model on lots of instruction data to improve performances on downstream benchmarks. From experiment results, we show that SciDFM achieves strong performance on general scientific benchmarks such as SciEval and SciQ, and it reaches a SOTA performance on domain-specific benchmarks among models of similar size. We further analyze the expert layers and show that the results of expert selection vary with data from different disciplines. To benefit the broader research community, we open-source SciDFM at https://huggingface.co/OpenDFM/SciDFM-MoE-A5.6B-v1.0.
Evolving Subnetwork Training for Large Language Models
Jun 11, 2024



Large language models have ushered in a new era of artificial intelligence research. However, their substantial training costs hinder further development and widespread adoption. In this paper, inspired by the redundancy in the parameters of large language models, we propose a novel training paradigm: Evolving Subnetwork Training (EST). EST samples subnetworks from the layers of the large language model and from commonly used modules within each layer, Multi-Head Attention (MHA) and Multi-Layer Perceptron (MLP). By gradually increasing the size of the subnetworks during the training process, EST can save the cost of training. We apply EST to train GPT2 model and TinyLlama model, resulting in 26.7\% FLOPs saving for GPT2 and 25.0\% for TinyLlama without an increase in loss on the pre-training dataset. Moreover, EST leads to performance improvements in downstream tasks, indicating that it benefits generalization. Additionally, we provide intuitive theoretical studies based on training dynamics and Dropout theory to ensure the feasibility of EST. Our code is available at https://github.com/OpenDFM/EST.
Sparsity-Accelerated Training for Large Language Models
Jun 03, 2024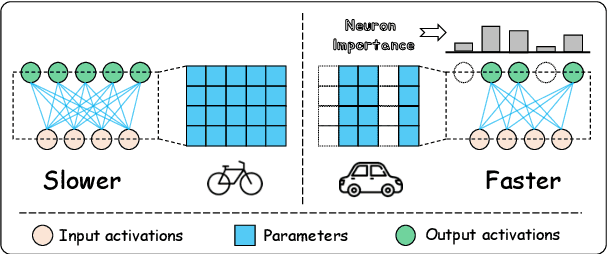
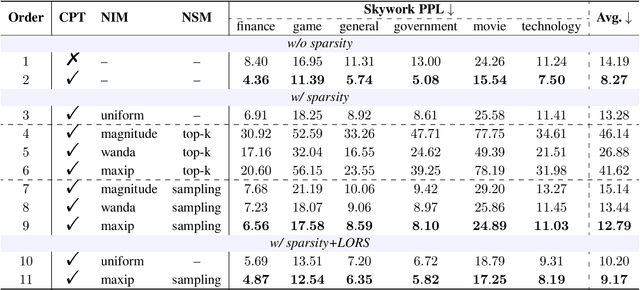
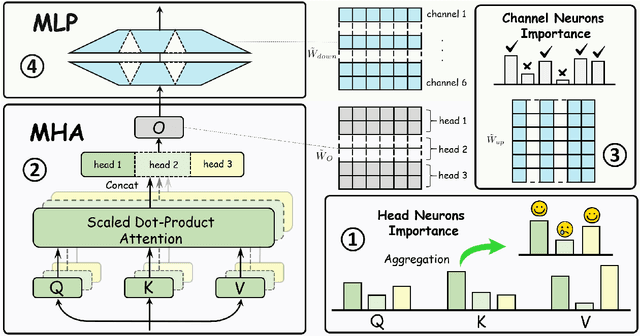
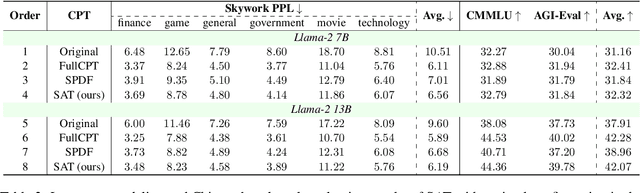
Large language models (LLMs) have demonstrated proficiency across various natural language processing (NLP) tasks but often require additional training, such as continual pre-training and supervised fine-tuning. However, the costs associated with this, primarily due to their large parameter count, remain high. This paper proposes leveraging \emph{sparsity} in pre-trained LLMs to expedite this training process. By observing sparsity in activated neurons during forward iterations, we identify the potential for computational speed-ups by excluding inactive neurons. We address associated challenges by extending existing neuron importance evaluation metrics and introducing a ladder omission rate scheduler. Our experiments on Llama-2 demonstrate that Sparsity-Accelerated Training (SAT) achieves comparable or superior performance to standard training while significantly accelerating the process. Specifically, SAT achieves a $45\%$ throughput improvement in continual pre-training and saves $38\%$ training time in supervised fine-tuning in practice. It offers a simple, hardware-agnostic, and easily deployable framework for additional LLM training. Our code is available at https://github.com/OpenDFM/SAT.
A BiRGAT Model for Multi-intent Spoken Language Understanding with Hierarchical Semantic Frames
Feb 28, 2024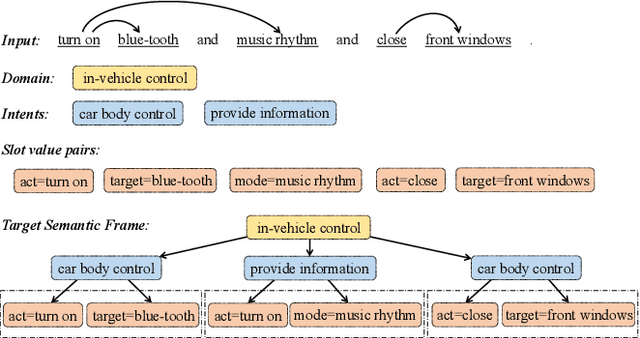
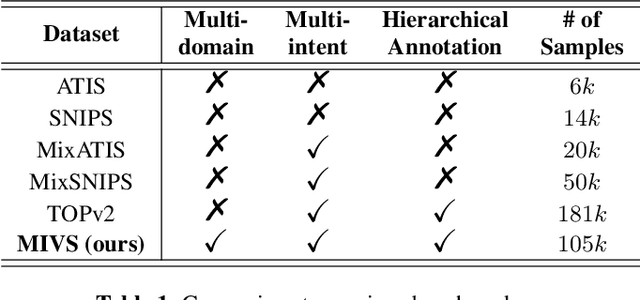
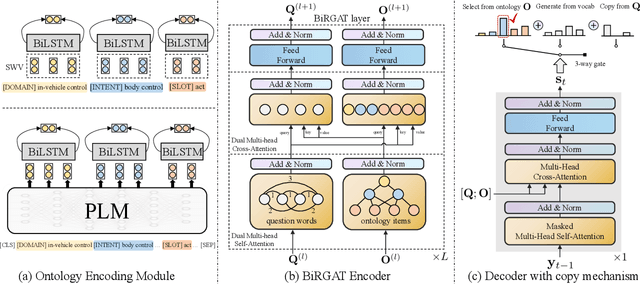
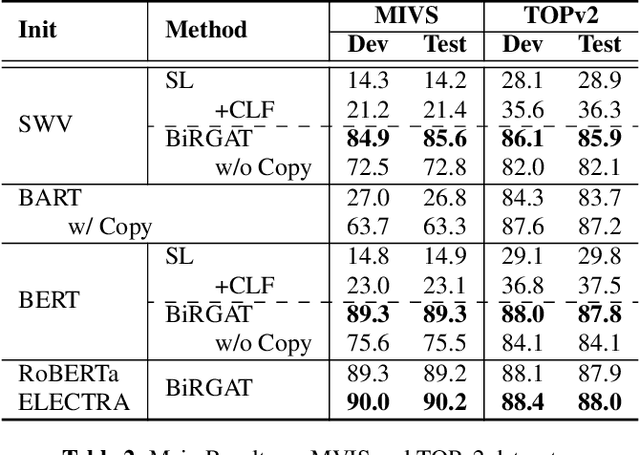
Previous work on spoken language understanding (SLU) mainly focuses on single-intent settings, where each input utterance merely contains one user intent. This configuration significantly limits the surface form of user utterances and the capacity of output semantics. In this work, we first propose a Multi-Intent dataset which is collected from a realistic in-Vehicle dialogue System, called MIVS. The target semantic frame is organized in a 3-layer hierarchical structure to tackle the alignment and assignment problems in multi-intent cases. Accordingly, we devise a BiRGAT model to encode the hierarchy of ontology items, the backbone of which is a dual relational graph attention network. Coupled with the 3-way pointer-generator decoder, our method outperforms traditional sequence labeling and classification-based schemes by a large margin.
ChemDFM: Dialogue Foundation Model for Chemistry
Jan 26, 2024



Large language models (LLMs) have established great success in the general domain of natural language processing. Their emerging task generalization and free-form dialogue capabilities can greatly help to design Chemical General Intelligence (CGI) to assist real-world research in chemistry. However, the existence of specialized language and knowledge in the field of chemistry, such as the highly informative SMILES notation, hinders the performance of general-domain LLMs in chemistry. To this end, we develop ChemDFM, the first LLM towards CGI. ChemDFM-13B is trained on 34B tokens from chemical literature, textbooks, and instructions as well as various data from the general domain. Therefore, it can store, understand, and reason over chemical knowledge and languages while still possessing advanced free-form language comprehension capabilities. Extensive quantitative evaluation shows that ChemDFM can significantly outperform the representative open-sourced LLMs. Moreover, ChemDFM can also surpass GPT-4 on a great portion of chemical tasks, despite the significant size difference. Further qualitative evaluations demonstrate the efficiency and effectiveness of ChemDFM in real-world research scenarios. We will open-source the ChemDFM model soon.
On the Structural Generalization in Text-to-SQL
Jan 21, 2023



Exploring the generalization of a text-to-SQL parser is essential for a system to automatically adapt the real-world databases. Previous works provided investigations focusing on lexical diversity, including the influence of the synonym and perturbations in both natural language questions and databases. However, research on the structure variety of database schema~(DS) is deficient. Specifically, confronted with the same input question, the target SQL is probably represented in different ways when the DS comes to a different structure. In this work, we provide in-deep discussions about the structural generalization of text-to-SQL tasks. We observe that current datasets are too templated to study structural generalization. To collect eligible test data, we propose a framework to generate novel text-to-SQL data via automatic and synchronous (DS, SQL) pair altering. In the experiments, significant performance reduction when evaluating well-trained text-to-SQL models on the synthetic samples demonstrates the limitation of current research regarding structural generalization. According to comprehensive analysis, we suggest the practical reason is the overfitting of (NL, SQL) patterns.
OPAL: Ontology-Aware Pretrained Language Model for End-to-End Task-Oriented Dialogue
Sep 10, 2022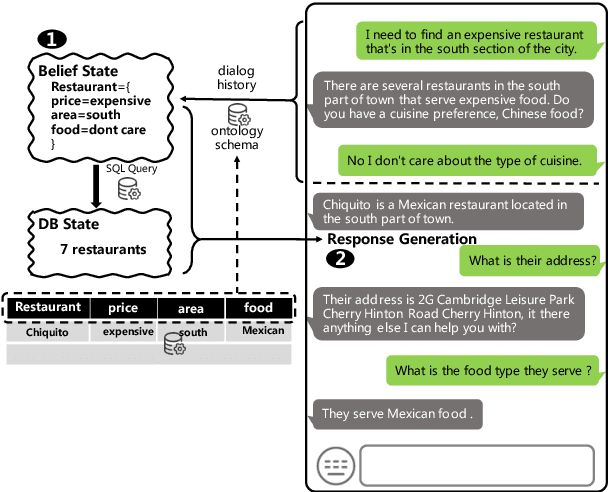

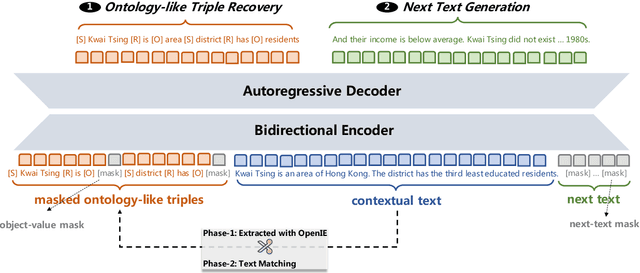

This paper presents an ontology-aware pretrained language model (OPAL) for end-to-end task-oriented dialogue (TOD). Unlike chit-chat dialogue models, task-oriented dialogue models fulfill at least two task-specific modules: dialogue state tracker (DST) and response generator (RG). The dialogue state consists of the domain-slot-value triples, which are regarded as the user's constraints to search the domain-related databases. The large-scale task-oriented dialogue data with the annotated structured dialogue state usually are inaccessible. It prevents the development of the pretrained language model for the task-oriented dialogue. We propose a simple yet effective pretraining method to alleviate this problem, which consists of two pretraining phases. The first phase is to pretrain on large-scale contextual text data, where the structured information of the text is extracted by the information extracting tool. To bridge the gap between the pretraining method and downstream tasks, we design two pretraining tasks: ontology-like triple recovery and next-text generation, which simulates the DST and RG, respectively. The second phase is to fine-tune the pretrained model on the TOD data. The experimental results show that our proposed method achieves an exciting boost and get competitive performance even without any TOD data on CamRest676 and MultiWOZ benchmarks.
DialogZoo: Large-Scale Dialog-Oriented Task Learning
May 25, 2022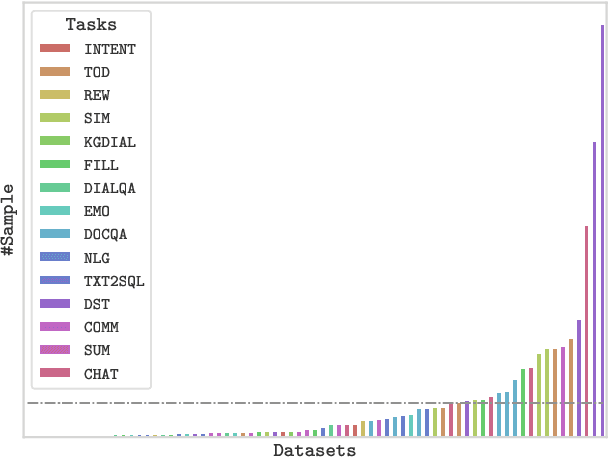
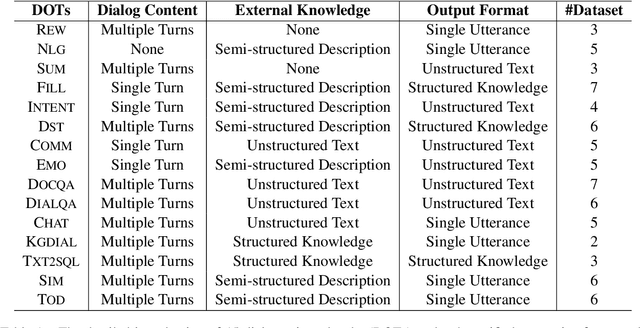
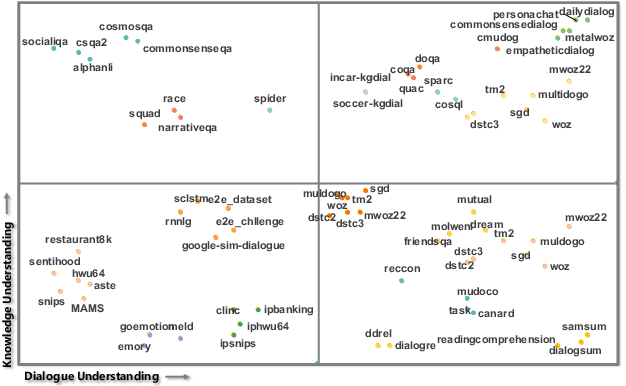
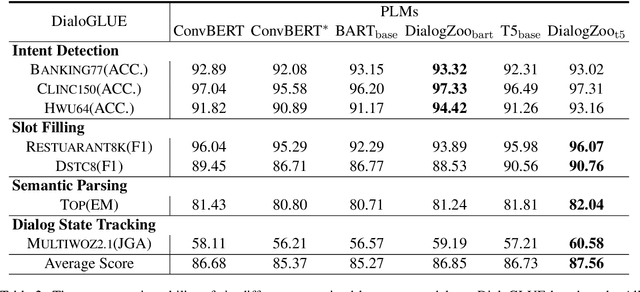
Building unified conversational agents has been a long-standing goal of the dialogue research community. Most previous works only focus on a subset of various dialogue tasks. In this work, we aim to build a unified foundation model which can solve massive diverse dialogue tasks. To achieve this goal, we first collect a large-scale well-labeled dialogue dataset from 73 publicly available datasets. In addition to this dataset, we further propose two dialogue-oriented self-supervised tasks, and finally use the mixture of supervised and self-supervised datasets to train our foundation model. The supervised examples make the model learn task-specific skills, while the self-supervised examples make the model learn more general skills. We evaluate our model on various downstream dialogue tasks. The experimental results show that our method not only improves the ability of dialogue generation and knowledge distillation, but also the representation ability of models.