 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQwen3-Coder-Next Technical Report
Feb 28, 2026We present Qwen3-Coder-Next, an open-weight language model specialized for coding agents. Qwen3-Coder-Next is an 80-billion-parameter model that activates only 3 billion parameters during inference, enabling strong coding capability with efficient inference. In this work, we explore how far strong training recipes can push the capability limits of models with small parameter footprints. To achieve this, we perform agentic training through large-scale synthesis of verifiable coding tasks paired with executable environments, allowing learning directly from environment feedback via mid-training and reinforcement learning. Across agent-centric benchmarks including SWE-Bench and Terminal-Bench, Qwen3-Coder-Next achieves competitive performance relative to its active parameter count. We release both base and instruction-tuned open-weight versions to support research and real-world coding agent development.
SWE-Universe: Scale Real-World Verifiable Environments to Millions
Feb 02, 2026We propose SWE-Universe, a scalable and efficient framework for automatically constructing real-world software engineering (SWE) verifiable environments from GitHub pull requests (PRs). To overcome the prevalent challenges of automatic building, such as low production yield, weak verifiers, and prohibitive cost, our framework utilizes a building agent powered by an efficient custom-trained model. This agent employs iterative self-verification and in-loop hacking detection to ensure the reliable generation of high-fidelity, verifiable tasks. Using this method, we scale the number of real-world multilingual SWE environments to a million scale (807,693). We demonstrate the profound value of our environments through large-scale agentic mid-training and reinforcement learning. Finally, we applied this technique to Qwen3-Max-Thinking and achieved a score of 75.3% on SWE-Bench Verified. Our work provides both a critical resource and a robust methodology to advance the next generation of coding agents.
OpenCUA: Open Foundations for Computer-Use Agents
Aug 12, 2025Vision-language models have demonstrated impressive capabilities as computer-use agents (CUAs) capable of automating diverse computer tasks. As their commercial potential grows, critical details of the most capable CUA systems remain closed. As these agents will increasingly mediate digital interactions and execute consequential decisions on our behalf, the research community needs access to open CUA frameworks to study their capabilities, limitations, and risks. To bridge this gap, we propose OpenCUA, a comprehensive open-source framework for scaling CUA data and foundation models. Our framework consists of: (1) an annotation infrastructure that seamlessly captures human computer-use demonstrations; (2) AgentNet, the first large-scale computer-use task dataset spanning 3 operating systems and 200+ applications and websites; (3) a scalable pipeline that transforms demonstrations into state-action pairs with reflective long Chain-of-Thought reasoning that sustain robust performance gains as data scales. Our end-to-end agent models demonstrate strong performance across CUA benchmarks. In particular, OpenCUA-32B achieves an average success rate of 34.8% on OSWorld-Verified, establishing a new state-of-the-art (SOTA) among open-source models and surpassing OpenAI CUA (GPT-4o). Further analysis confirms that our approach generalizes well across domains and benefits significantly from increased test-time computation. We release our annotation tool, datasets, code, and models to build open foundations for further CUA research.
NeuSym-RAG: Hybrid Neural Symbolic Retrieval with Multiview Structuring for PDF Question Answering
May 26, 2025The increasing number of academic papers poses significant challenges for researchers to efficiently acquire key details. While retrieval augmented generation (RAG) shows great promise in large language model (LLM) based automated question answering, previous works often isolate neural and symbolic retrieval despite their complementary strengths. Moreover, conventional single-view chunking neglects the rich structure and layout of PDFs, e.g., sections and tables. In this work, we propose NeuSym-RAG, a hybrid neural symbolic retrieval framework which combines both paradigms in an interactive process. By leveraging multi-view chunking and schema-based parsing, NeuSym-RAG organizes semi-structured PDF content into both the relational database and vectorstore, enabling LLM agents to iteratively gather context until sufficient to generate answers. Experiments on three full PDF-based QA datasets, including a self-annotated one AIRQA-REAL, show that NeuSym-RAG stably defeats both the vector-based RAG and various structured baselines, highlighting its capacity to unify both retrieval schemes and utilize multiple views. Code and data are publicly available at https://github.com/X-LANCE/NeuSym-RAG.
ProgRM: Build Better GUI Agents with Progress Rewards
May 23, 2025LLM-based (Large Language Model) GUI (Graphical User Interface) agents can potentially reshape our daily lives significantly. However, current LLM-based GUI agents suffer from the scarcity of high-quality training data owing to the difficulties of trajectory collection and reward annotation. Existing works have been exploring LLMs to collect trajectories for imitation learning or to offer reward signals for online RL training. However, the Outcome Reward Model (ORM) used in existing works cannot provide finegrained feedback and can over-penalize the valuable steps in finally failed trajectories. To this end, we propose Progress Reward Model (ProgRM) to provide dense informative intermediate rewards by predicting a task completion progress for each step in online training. To handle the challenge of progress reward label annotation, we further design an efficient LCS-based (Longest Common Subsequence) self-annotation algorithm to discover the key steps in trajectories and assign progress labels accordingly. ProgRM is evaluated with extensive experiments and analyses. Actors trained with ProgRM outperform leading proprietary LLMs and ORM-trained actors, illustrating the effectiveness of ProgRM. The codes for experiments will be made publicly available upon acceptance.
Reducing Tool Hallucination via Reliability Alignment
Dec 05, 2024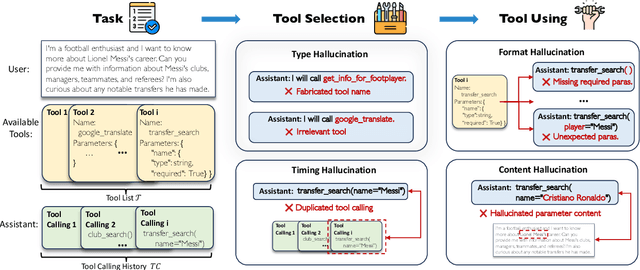
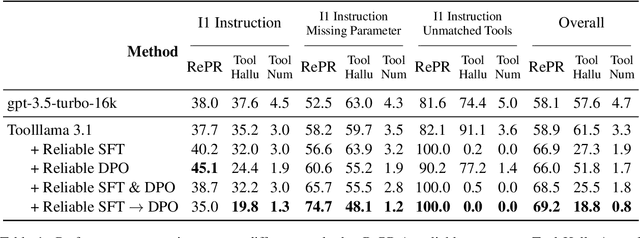
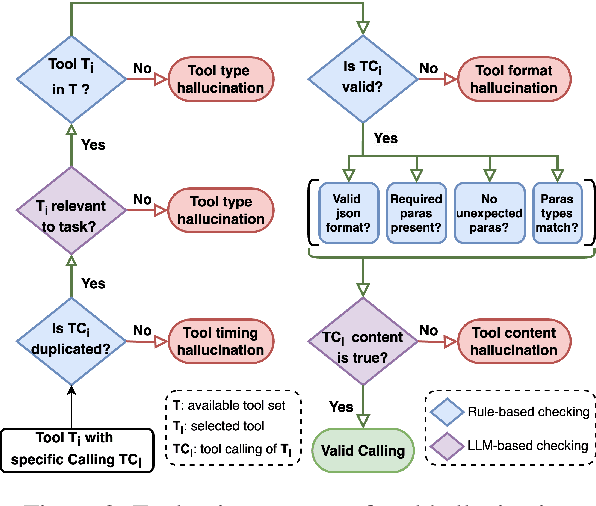
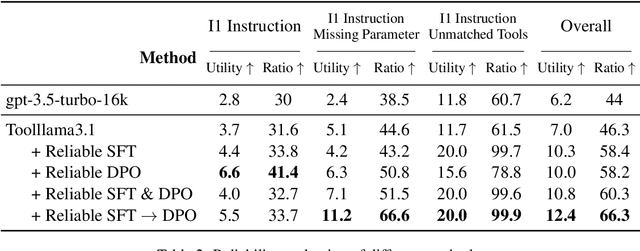
Large Language Models (LLMs) have extended their capabilities beyond language generation to interact with external systems through tool calling, offering powerful potential for real-world applications. However, the phenomenon of tool hallucinations, which occur when models improperly select or misuse tools, presents critical challenges that can lead to flawed task execution and increased operational costs. This paper investigates the concept of reliable tool calling and highlights the necessity of addressing tool hallucinations. We systematically categorize tool hallucinations into two main types: tool selection hallucination and tool usage hallucination. To mitigate these issues, we propose a reliability-focused alignment framework that enhances the model's ability to accurately assess tool relevance and usage. By proposing a suite of evaluation metrics and evaluating on StableToolBench, we further demonstrate the effectiveness of our framework in mitigating tool hallucination and improving the overall system reliability of LLM tool calling.
Spider 2.0: Evaluating Language Models on Real-World Enterprise Text-to-SQL Workflows
Nov 12, 2024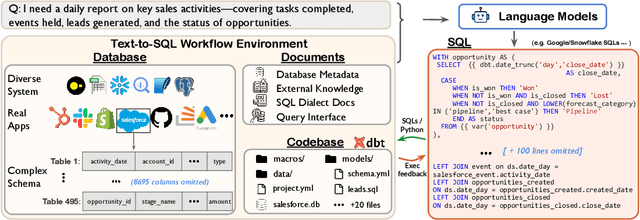


Real-world enterprise text-to-SQL workflows often involve complex cloud or local data across various database systems, multiple SQL queries in various dialects, and diverse operations from data transformation to analytics. We introduce Spider 2.0, an evaluation framework comprising 632 real-world text-to-SQL workflow problems derived from enterprise-level database use cases. The databases in Spider 2.0 are sourced from real data applications, often containing over 1,000 columns and stored in local or cloud database systems such as BigQuery and Snowflake. We show that solving problems in Spider 2.0 frequently requires understanding and searching through database metadata, dialect documentation, and even project-level codebases. This challenge calls for models to interact with complex SQL workflow environments, process extremely long contexts, perform intricate reasoning, and generate multiple SQL queries with diverse operations, often exceeding 100 lines, which goes far beyond traditional text-to-SQL challenges. Our evaluations indicate that based on o1-preview, our code agent framework successfully solves only 17.0% of the tasks, compared with 91.2% on Spider 1.0 and 73.0% on BIRD. Our results on Spider 2.0 show that while language models have demonstrated remarkable performance in code generation -- especially in prior text-to-SQL benchmarks -- they require significant improvement in order to achieve adequate performance for real-world enterprise usage. Progress on Spider 2.0 represents crucial steps towards developing intelligent, autonomous, code agents for real-world enterprise settings. Our code, baseline models, and data are available at https://spider2-sql.github.io.
Spider2-V: How Far Are Multimodal Agents From Automating Data Science and Engineering Workflows?
Jul 15, 2024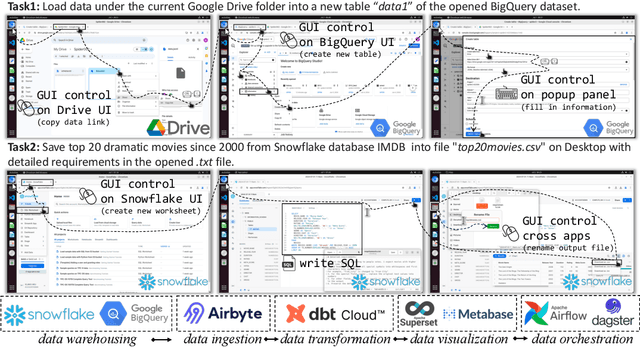
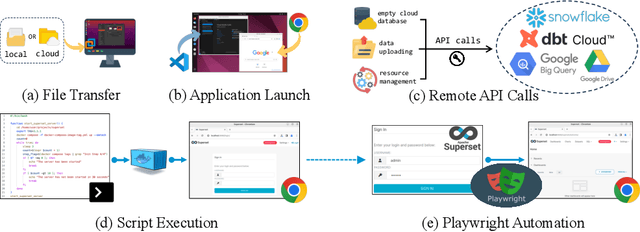
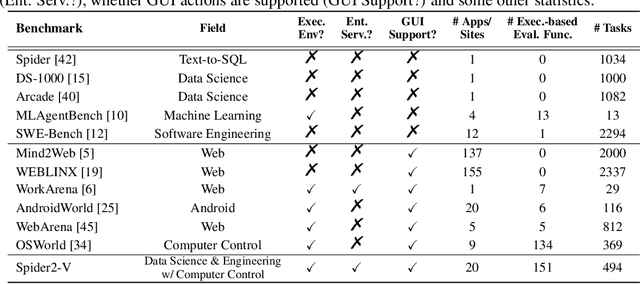
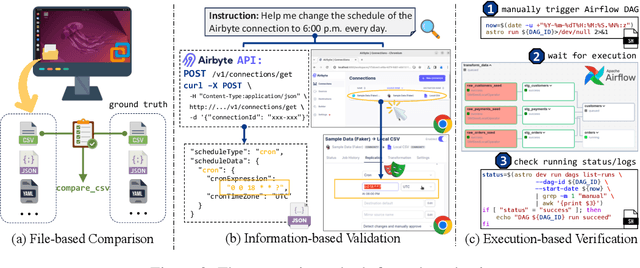
Data science and engineering workflows often span multiple stages, from warehousing to orchestration, using tools like BigQuery, dbt, and Airbyte. As vision language models (VLMs) advance in multimodal understanding and code generation, VLM-based agents could potentially automate these workflows by generating SQL queries, Python code, and GUI operations. This automation can improve the productivity of experts while democratizing access to large-scale data analysis. In this paper, we introduce Spider2-V, the first multimodal agent benchmark focusing on professional data science and engineering workflows, featuring 494 real-world tasks in authentic computer environments and incorporating 20 enterprise-level professional applications. These tasks, derived from real-world use cases, evaluate the ability of a multimodal agent to perform data-related tasks by writing code and managing the GUI in enterprise data software systems. To balance realistic simulation with evaluation simplicity, we devote significant effort to developing automatic configurations for task setup and carefully crafting evaluation metrics for each task. Furthermore, we supplement multimodal agents with comprehensive documents of these enterprise data software systems. Our empirical evaluation reveals that existing state-of-the-art LLM/VLM-based agents do not reliably automate full data workflows (14.0% success). Even with step-by-step guidance, these agents still underperform in tasks that require fine-grained, knowledge-intensive GUI actions (16.2%) and involve remote cloud-hosted workspaces (10.6%). We hope that Spider2-V paves the way for autonomous multimodal agents to transform the automation of data science and engineering workflow. Our code and data are available at https://spider2-v.github.io.
CoE-SQL: In-Context Learning for Multi-Turn Text-to-SQL with Chain-of-Editions
May 04, 2024Recently, Large Language Models (LLMs) have been demonstrated to possess impressive capabilities in a variety of domains and tasks. We investigate the issue of prompt design in the multi-turn text-to-SQL task and attempt to enhance the LLMs' reasoning capacity when generating SQL queries. In the conversational context, the current SQL query can be modified from the preceding SQL query with only a few operations due to the context dependency. We introduce our method called CoE-SQL which can prompt LLMs to generate the SQL query based on the previously generated SQL query with an edition chain. We also conduct extensive ablation studies to determine the optimal configuration of our approach. Our approach outperforms different in-context learning baselines stably and achieves state-of-the-art performances on two benchmarks SParC and CoSQL using LLMs, which is also competitive to the SOTA fine-tuned models.
OSWorld: Benchmarking Multimodal Agents for Open-Ended Tasks in Real Computer Environments
Apr 11, 2024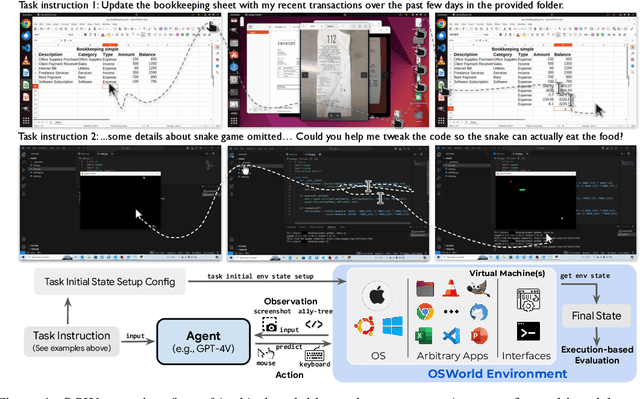

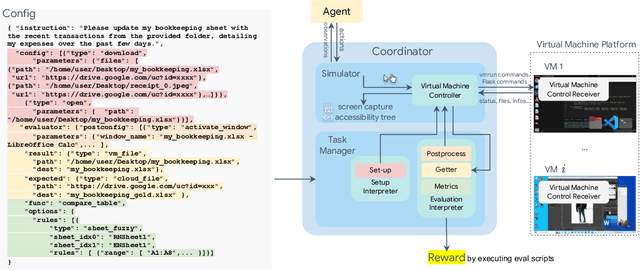

Autonomous agents that accomplish complex computer tasks with minimal human interventions have the potential to transform human-computer interaction, significantly enhancing accessibility and productivity. However, existing benchmarks either lack an interactive environment or are limited to environments specific to certain applications or domains, failing to reflect the diverse and complex nature of real-world computer use, thereby limiting the scope of tasks and agent scalability. To address this issue, we introduce OSWorld, the first-of-its-kind scalable, real computer environment for multimodal agents, supporting task setup, execution-based evaluation, and interactive learning across various operating systems such as Ubuntu, Windows, and macOS. OSWorld can serve as a unified, integrated computer environment for assessing open-ended computer tasks that involve arbitrary applications. Building upon OSWorld, we create a benchmark of 369 computer tasks involving real web and desktop apps in open domains, OS file I/O, and workflows spanning multiple applications. Each task example is derived from real-world computer use cases and includes a detailed initial state setup configuration and a custom execution-based evaluation script for reliable, reproducible evaluation. Extensive evaluation of state-of-the-art LLM/VLM-based agents on OSWorld reveals significant deficiencies in their ability to serve as computer assistants. While humans can accomplish over 72.36% of the tasks, the best model achieves only 12.24% success, primarily struggling with GUI grounding and operational knowledge. Comprehensive analysis using OSWorld provides valuable insights for developing multimodal generalist agents that were not possible with previous benchmarks. Our code, environment, baseline models, and data are publicly available at https://os-world.github.io.