 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHierarchical Multimodal Pre-training for Visually Rich Webpage Understanding
Paper and Code
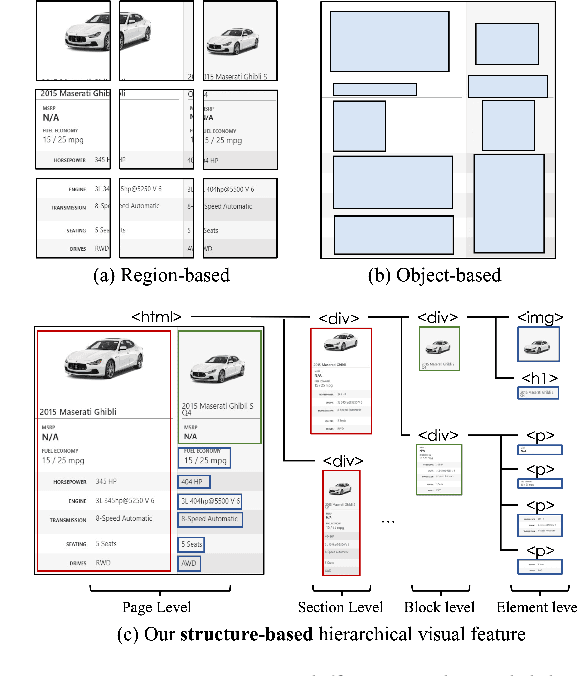
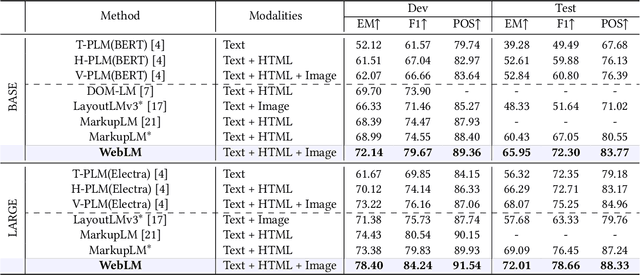
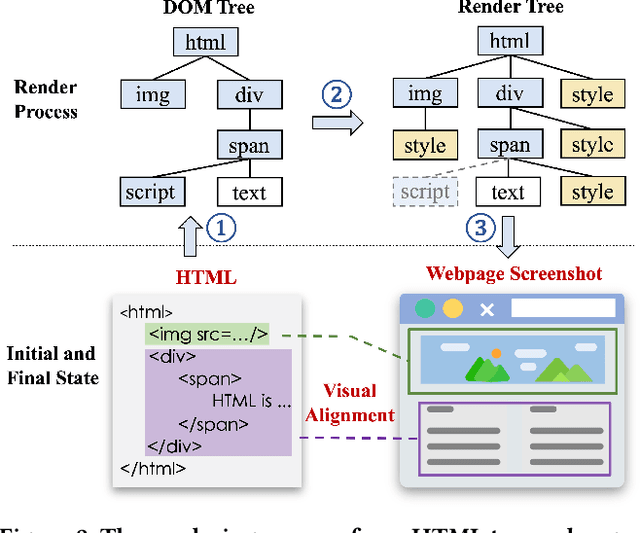
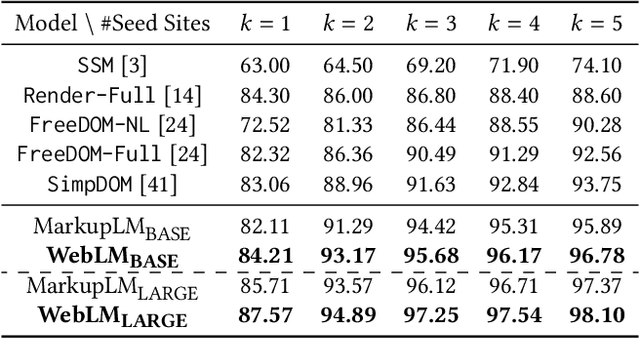
The growing prevalence of visually rich documents, such as webpages and scanned/digital-born documents (images, PDFs, etc.), has led to increased interest in automatic document understanding and information extraction across academia and industry. Although various document modalities, including image, text, layout, and structure, facilitate human information retrieval, the interconnected nature of these modalities presents challenges for neural networks. In this paper, we introduce WebLM, a multimodal pre-training network designed to address the limitations of solely modeling text and structure modalities of HTML in webpages. Instead of processing document images as unified natural images, WebLM integrates the hierarchical structure of document images to enhance the understanding of markup-language-based documents. Additionally, we propose several pre-training tasks to model the interaction among text, structure, and image modalities effectively. Empirical results demonstrate that the pre-trained WebLM significantly surpasses previous state-of-the-art pre-trained models across several webpage understanding tasks. The pre-trained models and code are available at https://github.com/X-LANCE/weblm.