 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpenCUA: Open Foundations for Computer-Use Agents
Aug 12, 2025Vision-language models have demonstrated impressive capabilities as computer-use agents (CUAs) capable of automating diverse computer tasks. As their commercial potential grows, critical details of the most capable CUA systems remain closed. As these agents will increasingly mediate digital interactions and execute consequential decisions on our behalf, the research community needs access to open CUA frameworks to study their capabilities, limitations, and risks. To bridge this gap, we propose OpenCUA, a comprehensive open-source framework for scaling CUA data and foundation models. Our framework consists of: (1) an annotation infrastructure that seamlessly captures human computer-use demonstrations; (2) AgentNet, the first large-scale computer-use task dataset spanning 3 operating systems and 200+ applications and websites; (3) a scalable pipeline that transforms demonstrations into state-action pairs with reflective long Chain-of-Thought reasoning that sustain robust performance gains as data scales. Our end-to-end agent models demonstrate strong performance across CUA benchmarks. In particular, OpenCUA-32B achieves an average success rate of 34.8% on OSWorld-Verified, establishing a new state-of-the-art (SOTA) among open-source models and surpassing OpenAI CUA (GPT-4o). Further analysis confirms that our approach generalizes well across domains and benefits significantly from increased test-time computation. We release our annotation tool, datasets, code, and models to build open foundations for further CUA research.
Scaling Computer-Use Grounding via User Interface Decomposition and Synthesis
May 19, 2025Graphical user interface (GUI) grounding, the ability to map natural language instructions to specific actions on graphical user interfaces, remains a critical bottleneck in computer use agent development. Current benchmarks oversimplify grounding tasks as short referring expressions, failing to capture the complexity of real-world interactions that require software commonsense, layout understanding, and fine-grained manipulation capabilities. To address these limitations, we introduce OSWorld-G, a comprehensive benchmark comprising 564 finely annotated samples across diverse task types including text matching, element recognition, layout understanding, and precise manipulation. Additionally, we synthesize and release the largest computer use grounding dataset Jedi, which contains 4 million examples through multi-perspective decoupling of tasks. Our multi-scale models trained on Jedi demonstrate its effectiveness by outperforming existing approaches on ScreenSpot-v2, ScreenSpot-Pro, and our OSWorld-G. Furthermore, we demonstrate that improved grounding with Jedi directly enhances agentic capabilities of general foundation models on complex computer tasks, improving from 5% to 27% on OSWorld. Through detailed ablation studies, we identify key factors contributing to grounding performance and verify that combining specialized data for different interface elements enables compositional generalization to novel interfaces. All benchmark, data, checkpoints, and code are open-sourced and available at https://osworld-grounding.github.io.
Qwen2.5-VL Technical Report
Feb 19, 2025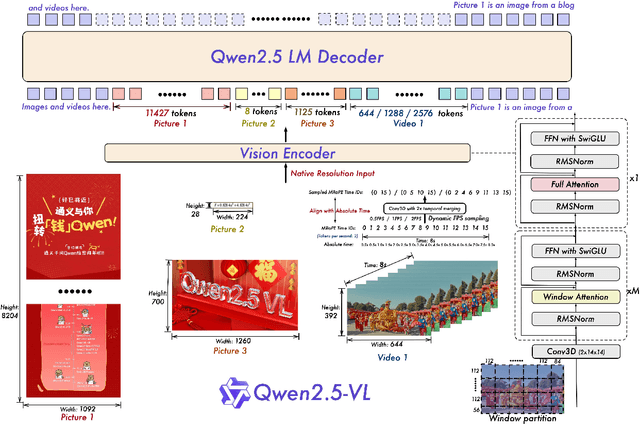
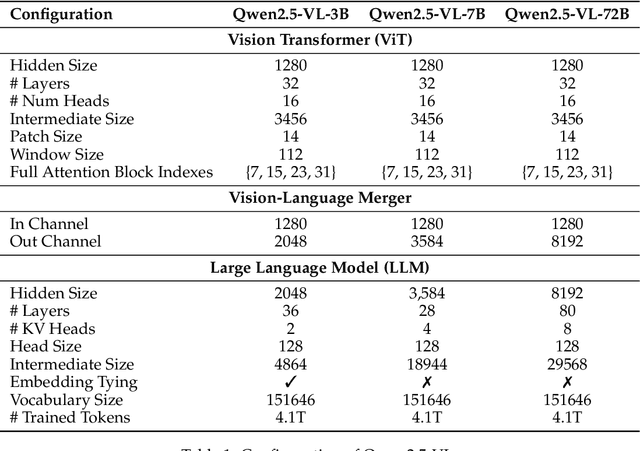
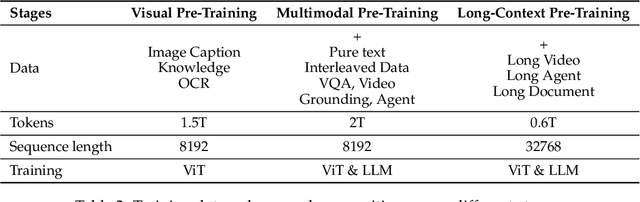
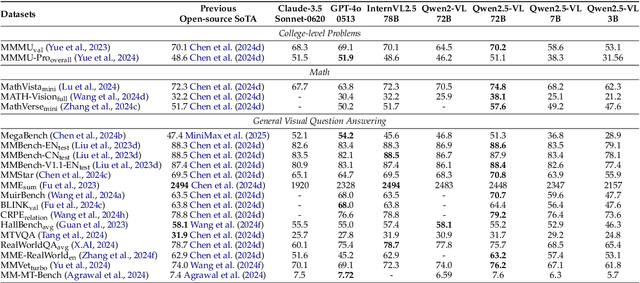
We introduce Qwen2.5-VL, the latest flagship model of Qwen vision-language series, which demonstrates significant advancements in both foundational capabilities and innovative functionalities. Qwen2.5-VL achieves a major leap forward in understanding and interacting with the world through enhanced visual recognition, precise object localization, robust document parsing, and long-video comprehension. A standout feature of Qwen2.5-VL is its ability to localize objects using bounding boxes or points accurately. It provides robust structured data extraction from invoices, forms, and tables, as well as detailed analysis of charts, diagrams, and layouts. To handle complex inputs, Qwen2.5-VL introduces dynamic resolution processing and absolute time encoding, enabling it to process images of varying sizes and videos of extended durations (up to hours) with second-level event localization. This allows the model to natively perceive spatial scales and temporal dynamics without relying on traditional normalization techniques. By training a native dynamic-resolution Vision Transformer (ViT) from scratch and incorporating Window Attention, we reduce computational overhead while maintaining native resolution. As a result, Qwen2.5-VL excels not only in static image and document understanding but also as an interactive visual agent capable of reasoning, tool usage, and task execution in real-world scenarios such as operating computers and mobile devices. Qwen2.5-VL is available in three sizes, addressing diverse use cases from edge AI to high-performance computing. The flagship Qwen2.5-VL-72B model matches state-of-the-art models like GPT-4o and Claude 3.5 Sonnet, particularly excelling in document and diagram understanding. Additionally, Qwen2.5-VL maintains robust linguistic performance, preserving the core language competencies of the Qwen2.5 LLM.
AgentTrek: Agent Trajectory Synthesis via Guiding Replay with Web Tutorials
Dec 12, 2024Graphical User Interface (GUI) agents hold great potential for automating complex tasks across diverse digital environments, from web applications to desktop software. However, the development of such agents is hindered by the lack of high-quality, multi-step trajectory data required for effective training. Existing approaches rely on expensive and labor-intensive human annotation, making them unsustainable at scale. To address this challenge, we propose AgentTrek, a scalable data synthesis pipeline that generates high-quality GUI agent trajectories by leveraging web tutorials. Our method automatically gathers tutorial-like texts from the internet, transforms them into task goals with step-by-step instructions, and employs a visual-language model agent to simulate their execution in a real digital environment. A VLM-based evaluator ensures the correctness of the generated trajectories. We demonstrate that training GUI agents with these synthesized trajectories significantly improves their grounding and planning performance over the current models. Moreover, our approach is more cost-efficient compared to traditional human annotation methods. This work underscores the potential of guided replay with web tutorials as a viable strategy for large-scale GUI agent training, paving the way for more capable and autonomous digital agents.
Aguvis: Unified Pure Vision Agents for Autonomous GUI Interaction
Dec 05, 2024



Graphical User Interfaces (GUIs) are critical to human-computer interaction, yet automating GUI tasks remains challenging due to the complexity and variability of visual environments. Existing approaches often rely on textual representations of GUIs, which introduce limitations in generalization, efficiency, and scalability. In this paper, we introduce Aguvis, a unified pure vision-based framework for autonomous GUI agents that operates across various platforms. Our approach leverages image-based observations, and grounding instructions in natural language to visual elements, and employs a consistent action space to ensure cross-platform generalization. To address the limitations of previous work, we integrate explicit planning and reasoning within the model, enhancing its ability to autonomously navigate and interact with complex digital environments. We construct a large-scale dataset of GUI agent trajectories, incorporating multimodal reasoning and grounding, and employ a two-stage training pipeline that first focuses on general GUI grounding, followed by planning and reasoning. Through comprehensive experiments, we demonstrate that Aguvis surpasses previous state-of-the-art methods in both offline and real-world online scenarios, achieving, to our knowledge, the first fully autonomous pure vision GUI agent capable of performing tasks independently without collaboration with external closed-source models. We open-sourced all datasets, models, and training recipes to facilitate future research at https://aguvis-project.github.io/.
OSWorld: Benchmarking Multimodal Agents for Open-Ended Tasks in Real Computer Environments
Apr 11, 2024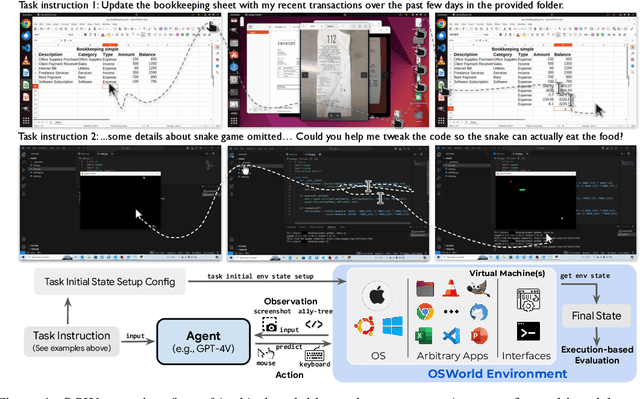

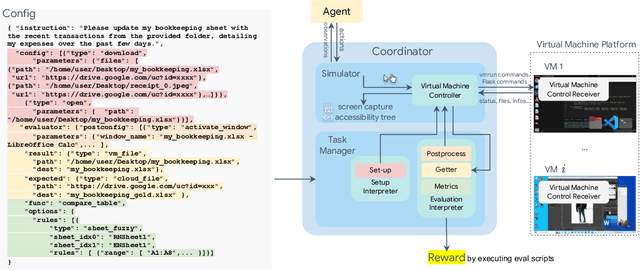

Autonomous agents that accomplish complex computer tasks with minimal human interventions have the potential to transform human-computer interaction, significantly enhancing accessibility and productivity. However, existing benchmarks either lack an interactive environment or are limited to environments specific to certain applications or domains, failing to reflect the diverse and complex nature of real-world computer use, thereby limiting the scope of tasks and agent scalability. To address this issue, we introduce OSWorld, the first-of-its-kind scalable, real computer environment for multimodal agents, supporting task setup, execution-based evaluation, and interactive learning across various operating systems such as Ubuntu, Windows, and macOS. OSWorld can serve as a unified, integrated computer environment for assessing open-ended computer tasks that involve arbitrary applications. Building upon OSWorld, we create a benchmark of 369 computer tasks involving real web and desktop apps in open domains, OS file I/O, and workflows spanning multiple applications. Each task example is derived from real-world computer use cases and includes a detailed initial state setup configuration and a custom execution-based evaluation script for reliable, reproducible evaluation. Extensive evaluation of state-of-the-art LLM/VLM-based agents on OSWorld reveals significant deficiencies in their ability to serve as computer assistants. While humans can accomplish over 72.36% of the tasks, the best model achieves only 12.24% success, primarily struggling with GUI grounding and operational knowledge. Comprehensive analysis using OSWorld provides valuable insights for developing multimodal generalist agents that were not possible with previous benchmarks. Our code, environment, baseline models, and data are publicly available at https://os-world.github.io.
OpenAgents: An Open Platform for Language Agents in the Wild
Oct 16, 2023



Language agents show potential in being capable of utilizing natural language for varied and intricate tasks in diverse environments, particularly when built upon large language models (LLMs). Current language agent frameworks aim to facilitate the construction of proof-of-concept language agents while neglecting the non-expert user access to agents and paying little attention to application-level designs. We present OpenAgents, an open platform for using and hosting language agents in the wild of everyday life. OpenAgents includes three agents: (1) Data Agent for data analysis with Python/SQL and data tools; (2) Plugins Agent with 200+ daily API tools; (3) Web Agent for autonomous web browsing. OpenAgents enables general users to interact with agent functionalities through a web user interface optimized for swift responses and common failures while offering developers and researchers a seamless deployment experience on local setups, providing a foundation for crafting innovative language agents and facilitating real-world evaluations. We elucidate the challenges and opportunities, aspiring to set a foundation for future research and development of real-world language agents.
Lemur: Harmonizing Natural Language and Code for Language Agents
Oct 10, 2023We introduce Lemur and Lemur-Chat, openly accessible language models optimized for both natural language and coding capabilities to serve as the backbone of versatile language agents. The evolution from language chat models to functional language agents demands that models not only master human interaction, reasoning, and planning but also ensure grounding in the relevant environments. This calls for a harmonious blend of language and coding capabilities in the models. Lemur and Lemur-Chat are proposed to address this necessity, demonstrating balanced proficiencies in both domains, unlike existing open-source models that tend to specialize in either. Through meticulous pre-training using a code-intensive corpus and instruction fine-tuning on text and code data, our models achieve state-of-the-art averaged performance across diverse text and coding benchmarks among open-source models. Comprehensive experiments demonstrate Lemur's superiority over existing open-source models and its proficiency across various agent tasks involving human communication, tool usage, and interaction under fully- and partially- observable environments. The harmonization between natural and programming languages enables Lemur-Chat to significantly narrow the gap with proprietary models on agent abilities, providing key insights into developing advanced open-source agents adept at reasoning, planning, and operating seamlessly across environments. https://github.com/OpenLemur/Lemur
In-Context Learning with Many Demonstration Examples
Feb 09, 2023Large pre-training language models (PLMs) have shown promising in-context learning abilities. However, due to the backbone transformer architecture, existing PLMs are bottlenecked by the memory and computational cost when scaling up to a large context size, leaving instruction tuning and in-context learning of many demonstration examples, as well as long-range language modeling under-explored. In this study, we propose a long-range language model EVALM based on an efficient transformer mechanism. EVALM is trained with 8k tokens per batch line and can test up to 256k-lengthed contexts with extrapolation, 128 times to the limit of existing PLMs (e.g. GPT3). Based on EVALM, we scale up the size of examples efficiently in both instruction tuning and in-context learning to explore the boundary of the benefits from more annotated data. Experimental results on a diverse set of tasks show that EVALM achieves 4.1% higher accuracy on average, and the average length of achieving the best accuracy score over tasks is around 12k. We find that in-context learning can achieve higher performance with more demonstrations under many-shot instruction tuning (8k), and further extending the length of instructions (16k) can further improve the upper bound of scaling in-context learning.
DiT: Self-supervised Pre-training for Document Image Transformer
Apr 12, 2022
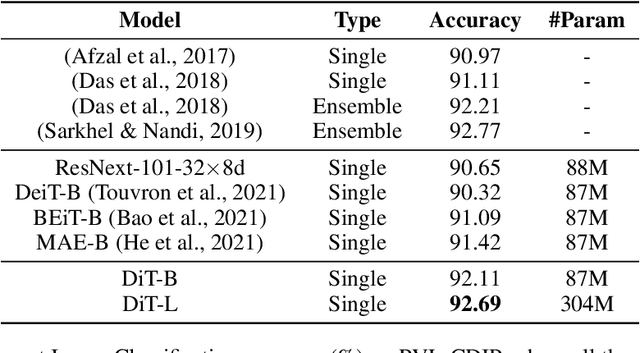
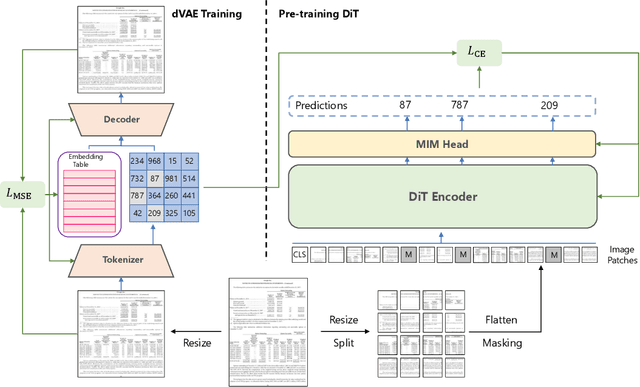
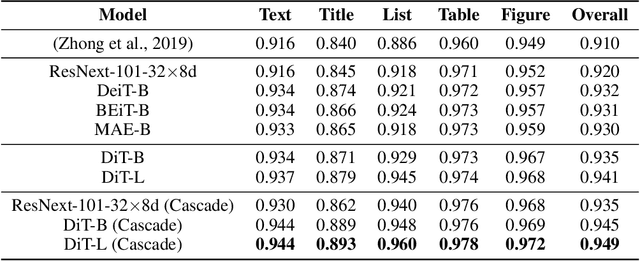
Image Transformer has recently achieved significant progress for natural image understanding, either using supervised (ViT, DeiT, etc.) or self-supervised (BEiT, MAE, etc.) pre-training techniques. In this paper, we propose DiT, a self-supervised pre-trained Document Image Transformer model using large-scale unlabeled text images for Document AI tasks, which is essential since no supervised counterparts ever exist due to the lack of human labeled document images. We leverage DiT as the backbone network in a variety of vision-based Document AI tasks, including document image classification, document layout analysis, table detection as well as text detection for OCR. Experiment results have illustrated that the self-supervised pre-trained DiT model achieves new state-of-the-art results on these downstream tasks, e.g. document image classification (91.11 $\rightarrow$ 92.69), document layout analysis (91.0 $\rightarrow$ 94.9), table detection (94.23 $\rightarrow$ 96.55) and text detection for OCR (93.07 $\rightarrow$ 94.29). The code and pre-trained models are publicly available at \url{https://aka.ms/msdit}.