 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiT: Self-supervised Pre-training for Document Image Transformer
Paper and Code
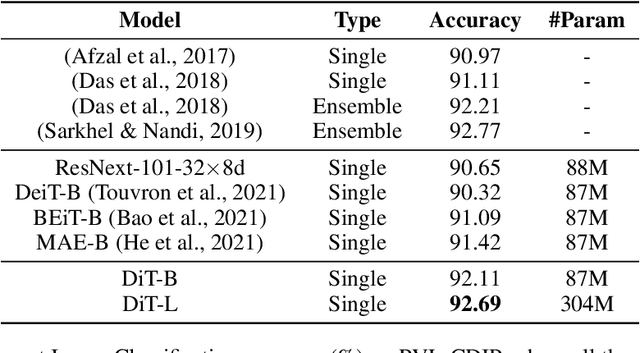
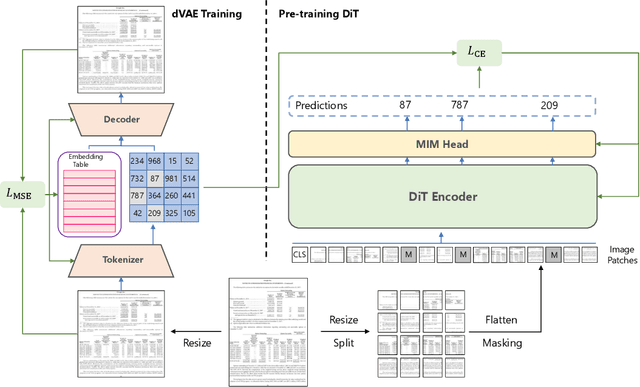
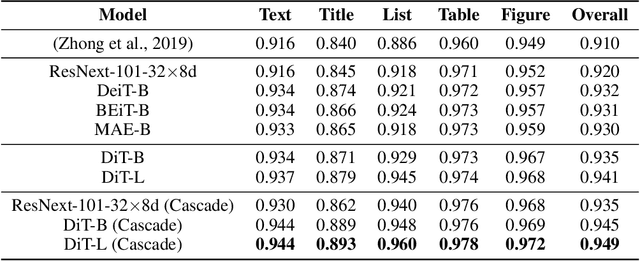
Image Transformer has recently achieved significant progress for natural image understanding, either using supervised (ViT, DeiT, etc.) or self-supervised (BEiT, MAE, etc.) pre-training techniques. In this paper, we propose DiT, a self-supervised pre-trained Document Image Transformer model using large-scale unlabeled text images for Document AI tasks, which is essential since no supervised counterparts ever exist due to the lack of human labeled document images. We leverage DiT as the backbone network in a variety of vision-based Document AI tasks, including document image classification, document layout analysis, table detection as well as text detection for OCR. Experiment results have illustrated that the self-supervised pre-trained DiT model achieves new state-of-the-art results on these downstream tasks, e.g. document image classification (91.11 $\rightarrow$ 92.69), document layout analysis (91.0 $\rightarrow$ 94.9), table detection (94.23 $\rightarrow$ 96.55) and text detection for OCR (93.07 $\rightarrow$ 94.29). The code and pre-trained models are publicly available at \url{https://aka.ms/msdit}.