 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReFocus: Visual Editing as a Chain of Thought for Structured Image Understanding
Jan 09, 2025



Structured image understanding, such as interpreting tables and charts, requires strategically refocusing across various structures and texts within an image, forming a reasoning sequence to arrive at the final answer. However, current multimodal large language models (LLMs) lack this multihop selective attention capability. In this work, we introduce ReFocus, a simple yet effective framework that equips multimodal LLMs with the ability to generate "visual thoughts" by performing visual editing on the input image through code, shifting and refining their visual focuses. Specifically, ReFocus enables multimodal LLMs to generate Python codes to call tools and modify the input image, sequentially drawing boxes, highlighting sections, and masking out areas, thereby enhancing the visual reasoning process. We experiment upon a wide range of structured image understanding tasks involving tables and charts. ReFocus largely improves performance on all tasks over GPT-4o without visual editing, yielding an average gain of 11.0% on table tasks and 6.8% on chart tasks. We present an in-depth analysis of the effects of different visual edits, and reasons why ReFocus can improve the performance without introducing additional information. Further, we collect a 14k training set using ReFocus, and prove that such visual chain-of-thought with intermediate information offers a better supervision than standard VQA data, reaching a 8.0% average gain over the same model trained with QA pairs and 2.6% over CoT.
Kosmos-2.5: A Multimodal Literate Model
Sep 20, 2023



We present Kosmos-2.5, a multimodal literate model for machine reading of text-intensive images. Pre-trained on large-scale text-intensive images, Kosmos-2.5 excels in two distinct yet cooperative transcription tasks: (1) generating spatially-aware text blocks, where each block of text is assigned its spatial coordinates within the image, and (2) producing structured text output that captures styles and structures into the markdown format. This unified multimodal literate capability is achieved through a shared Transformer architecture, task-specific prompts, and flexible text representations. We evaluate Kosmos-2.5 on end-to-end document-level text recognition and image-to-markdown text generation. Furthermore, the model can be readily adapted for any text-intensive image understanding task with different prompts through supervised fine-tuning, making it a general-purpose tool for real-world applications involving text-rich images. This work also paves the way for the future scaling of multimodal large language models.
From Characters to Words: Hierarchical Pre-trained Language Model for Open-vocabulary Language Understanding
May 23, 2023Current state-of-the-art models for natural language understanding require a preprocessing step to convert raw text into discrete tokens. This process known as tokenization relies on a pre-built vocabulary of words or sub-word morphemes. This fixed vocabulary limits the model's robustness to spelling errors and its capacity to adapt to new domains. In this work, we introduce a novel open-vocabulary language model that adopts a hierarchical two-level approach: one at the word level and another at the sequence level. Concretely, we design an intra-word module that uses a shallow Transformer architecture to learn word representations from their characters, and a deep inter-word Transformer module that contextualizes each word representation by attending to the entire word sequence. Our model thus directly operates on character sequences with explicit awareness of word boundaries, but without biased sub-word or word-level vocabulary. Experiments on various downstream tasks show that our method outperforms strong baselines. We also demonstrate that our hierarchical model is robust to textual corruption and domain shift.
Diffusion-based Document Layout Generation
Mar 19, 2023We develop a diffusion-based approach for various document layout sequence generation. Layout sequences specify the contents of a document design in an explicit format. Our novel diffusion-based approach works in the sequence domain rather than the image domain in order to permit more complex and realistic layouts. We also introduce a new metric, Document Earth Mover's Distance (Doc-EMD). By considering similarity between heterogeneous categories document designs, we handle the shortcomings of prior document metrics that only evaluate the same category of layouts. Our empirical analysis shows that our diffusion-based approach is comparable to or outperforming other previous methods for layout generation across various document datasets. Moreover, our metric is capable of differentiating documents better than previous metrics for specific cases.
Unifying Vision, Text, and Layout for Universal Document Processing
Dec 20, 2022



We propose Universal Document Processing (UDOP), a foundation Document AI model which unifies text, image, and layout modalities together with varied task formats, including document understanding and generation. UDOP leverages the spatial correlation between textual content and document image to model image, text, and layout modalities with one uniform representation. With a novel Vision-Text-Layout Transformer, UDOP unifies pretraining and multi-domain downstream tasks into a prompt-based sequence generation scheme. UDOP is pretrained on both large-scale unlabeled document corpora using innovative self-supervised objectives and diverse labeled data. UDOP also learns to generate document images from text and layout modalities via masked image reconstruction. To the best of our knowledge, this is the first time in the field of document AI that one model simultaneously achieves high-quality neural document editing and content customization. Our method sets the state-of-the-art on 9 Document AI tasks, e.g., document understanding and QA, across diverse data domains like finance reports, academic papers, and websites. UDOP ranks first on the leaderboard of the Document Understanding Benchmark (DUE).
XDoc: Unified Pre-training for Cross-Format Document Understanding
Oct 06, 2022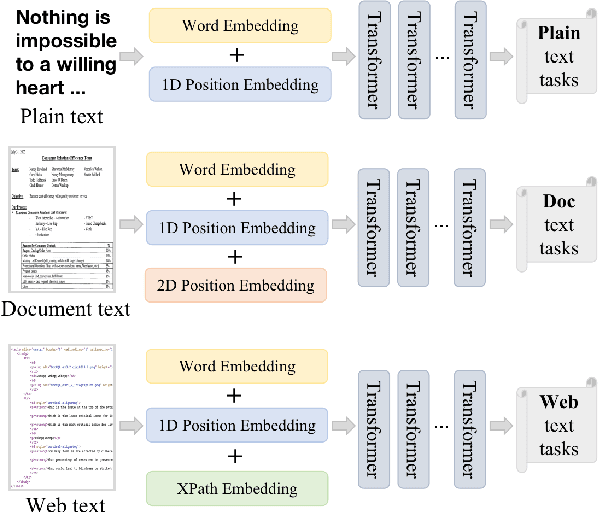
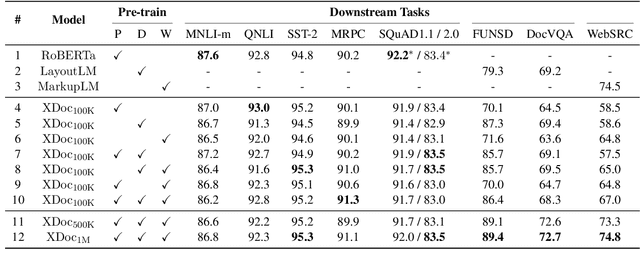
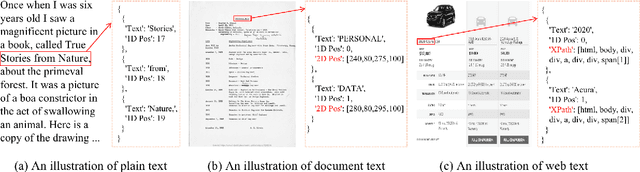

The surge of pre-training has witnessed the rapid development of document understanding recently. Pre-training and fine-tuning framework has been effectively used to tackle texts in various formats, including plain texts, document texts, and web texts. Despite achieving promising performance, existing pre-trained models usually target one specific document format at one time, making it difficult to combine knowledge from multiple document formats. To address this, we propose XDoc, a unified pre-trained model which deals with different document formats in a single model. For parameter efficiency, we share backbone parameters for different formats such as the word embedding layer and the Transformer layers. Meanwhile, we introduce adaptive layers with lightweight parameters to enhance the distinction across different formats. Experimental results have demonstrated that with only 36.7% parameters, XDoc achieves comparable or even better performance on a variety of downstream tasks compared with the individual pre-trained models, which is cost effective for real-world deployment. The code and pre-trained models will be publicly available at \url{https://aka.ms/xdoc}.
Understanding Long Documents with Different Position-Aware Attentions
Aug 17, 2022
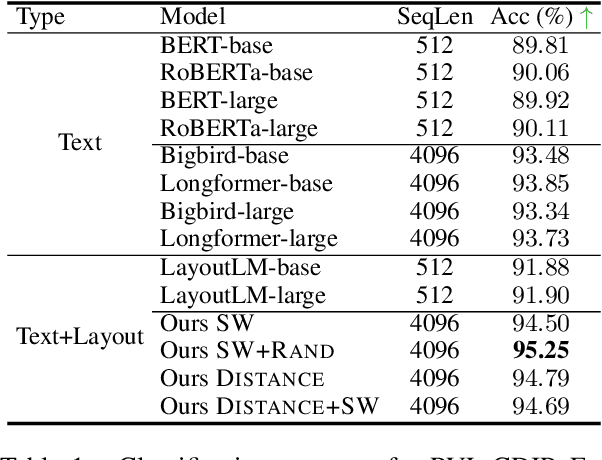
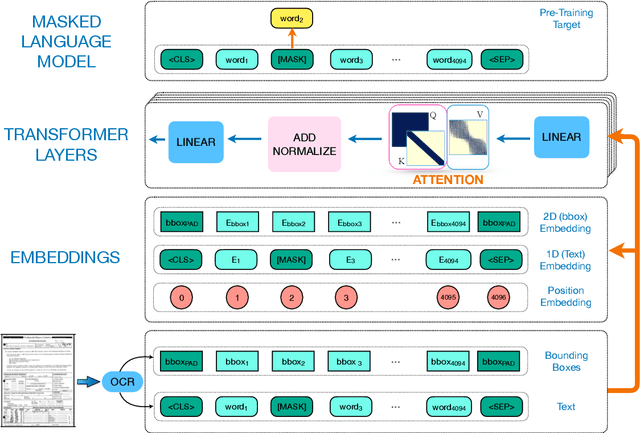
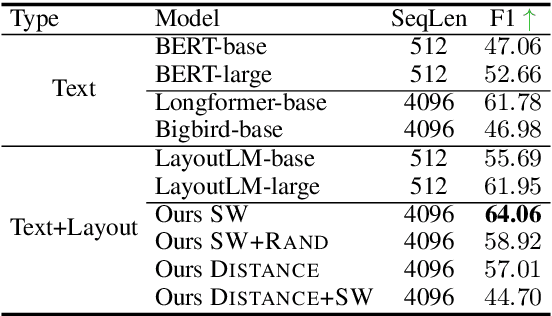
Despite several successes in document understanding, the practical task for long document understanding is largely under-explored due to several challenges in computation and how to efficiently absorb long multimodal input. Most current transformer-based approaches only deal with short documents and employ solely textual information for attention due to its prohibitive computation and memory limit. To address those issues in long document understanding, we explore different approaches in handling 1D and new 2D position-aware attention with essentially shortened context. Experimental results show that our proposed models have advantages for this task based on various evaluation metrics. Furthermore, our model makes changes only to the attention and thus can be easily adapted to any transformer-based architecture.
DiT: Self-supervised Pre-training for Document Image Transformer
Apr 12, 2022
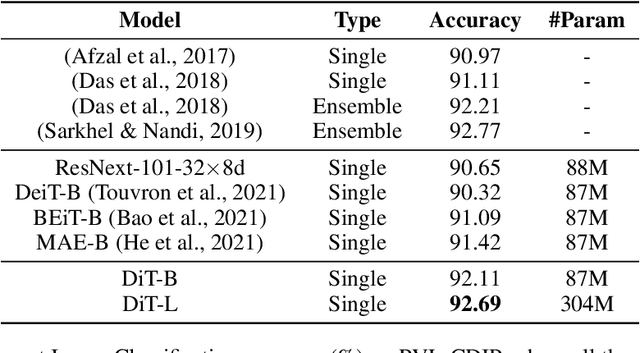
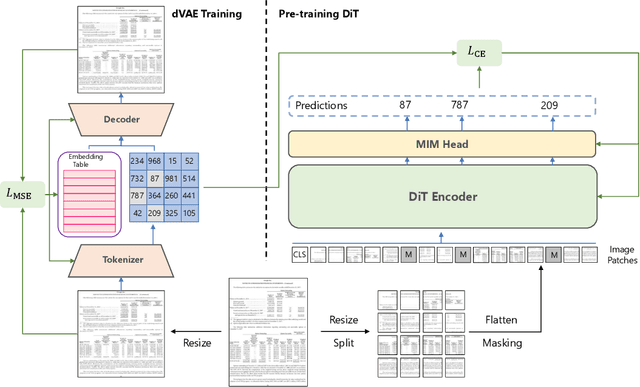
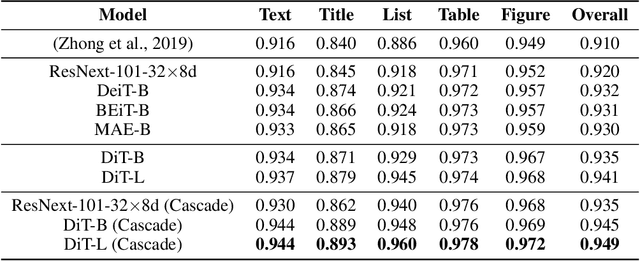
Image Transformer has recently achieved significant progress for natural image understanding, either using supervised (ViT, DeiT, etc.) or self-supervised (BEiT, MAE, etc.) pre-training techniques. In this paper, we propose DiT, a self-supervised pre-trained Document Image Transformer model using large-scale unlabeled text images for Document AI tasks, which is essential since no supervised counterparts ever exist due to the lack of human labeled document images. We leverage DiT as the backbone network in a variety of vision-based Document AI tasks, including document image classification, document layout analysis, table detection as well as text detection for OCR. Experiment results have illustrated that the self-supervised pre-trained DiT model achieves new state-of-the-art results on these downstream tasks, e.g. document image classification (91.11 $\rightarrow$ 92.69), document layout analysis (91.0 $\rightarrow$ 94.9), table detection (94.23 $\rightarrow$ 96.55) and text detection for OCR (93.07 $\rightarrow$ 94.29). The code and pre-trained models are publicly available at \url{https://aka.ms/msdit}.
Improving Structured Text Recognition with Regular Expression Biasing
Nov 10, 2021
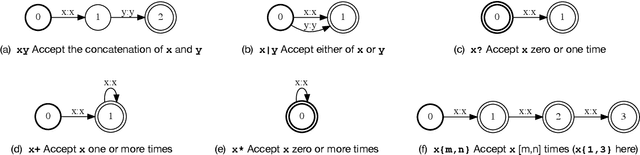
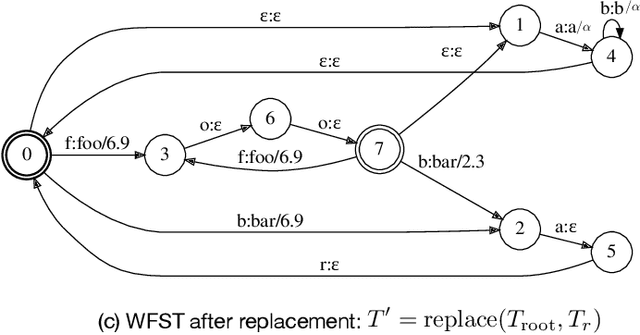

We study the problem of recognizing structured text, i.e. text that follows certain formats, and propose to improve the recognition accuracy of structured text by specifying regular expressions (regexes) for biasing. A biased recognizer recognizes text that matches the specified regexes with significantly improved accuracy, at the cost of a generally small degradation on other text. The biasing is realized by modeling regexes as a Weighted Finite-State Transducer (WFST) and injecting it into the decoder via dynamic replacement. A single hyperparameter controls the biasing strength. The method is useful for recognizing text lines with known formats or containing words from a domain vocabulary. Examples include driver license numbers, drug names in prescriptions, etc. We demonstrate the efficacy of regex biasing on datasets of printed and handwritten structured text and measures its side effects.
TrOCR: Transformer-based Optical Character Recognition with Pre-trained Models
Sep 25, 2021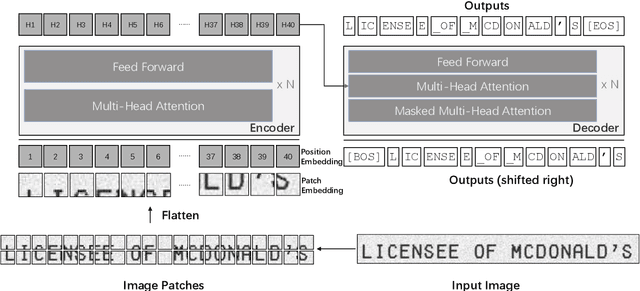

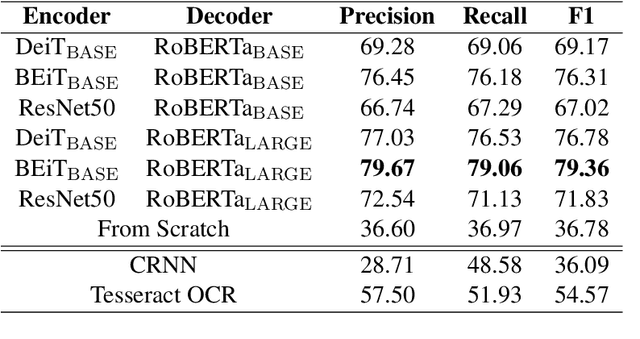
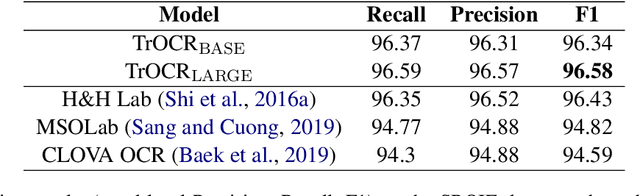
Text recognition is a long-standing research problem for document digitalization. Existing approaches for text recognition are usually built based on CNN for image understanding and RNN for char-level text generation. In addition, another language model is usually needed to improve the overall accuracy as a post-processing step. In this paper, we propose an end-to-end text recognition approach with pre-trained image Transformer and text Transformer models, namely TrOCR, which leverages the Transformer architecture for both image understanding and wordpiece-level text generation. The TrOCR model is simple but effective, and can be pre-trained with large-scale synthetic data and fine-tuned with human-labeled datasets. Experiments show that the TrOCR model outperforms the current state-of-the-art models on both printed and handwritten text recognition tasks. The code and models will be publicly available at https://aka.ms/TrOCR.