 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReFocus: Visual Editing as a Chain of Thought for Structured Image Understanding
Jan 09, 2025



Structured image understanding, such as interpreting tables and charts, requires strategically refocusing across various structures and texts within an image, forming a reasoning sequence to arrive at the final answer. However, current multimodal large language models (LLMs) lack this multihop selective attention capability. In this work, we introduce ReFocus, a simple yet effective framework that equips multimodal LLMs with the ability to generate "visual thoughts" by performing visual editing on the input image through code, shifting and refining their visual focuses. Specifically, ReFocus enables multimodal LLMs to generate Python codes to call tools and modify the input image, sequentially drawing boxes, highlighting sections, and masking out areas, thereby enhancing the visual reasoning process. We experiment upon a wide range of structured image understanding tasks involving tables and charts. ReFocus largely improves performance on all tasks over GPT-4o without visual editing, yielding an average gain of 11.0% on table tasks and 6.8% on chart tasks. We present an in-depth analysis of the effects of different visual edits, and reasons why ReFocus can improve the performance without introducing additional information. Further, we collect a 14k training set using ReFocus, and prove that such visual chain-of-thought with intermediate information offers a better supervision than standard VQA data, reaching a 8.0% average gain over the same model trained with QA pairs and 2.6% over CoT.
Diffusion-based Document Layout Generation
Mar 19, 2023We develop a diffusion-based approach for various document layout sequence generation. Layout sequences specify the contents of a document design in an explicit format. Our novel diffusion-based approach works in the sequence domain rather than the image domain in order to permit more complex and realistic layouts. We also introduce a new metric, Document Earth Mover's Distance (Doc-EMD). By considering similarity between heterogeneous categories document designs, we handle the shortcomings of prior document metrics that only evaluate the same category of layouts. Our empirical analysis shows that our diffusion-based approach is comparable to or outperforming other previous methods for layout generation across various document datasets. Moreover, our metric is capable of differentiating documents better than previous metrics for specific cases.
A Compositional Textual Model for Recognition of Imperfect Word Images
Nov 27, 2018
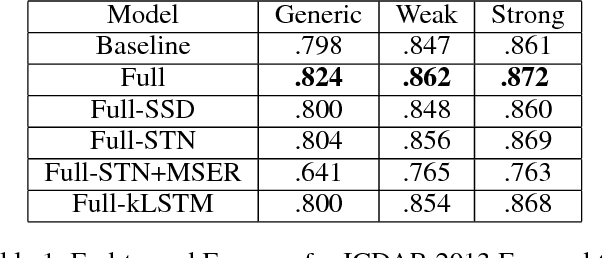
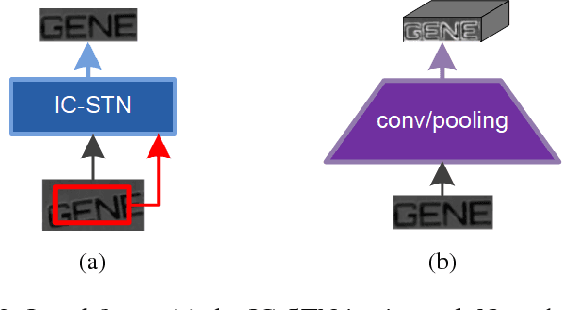
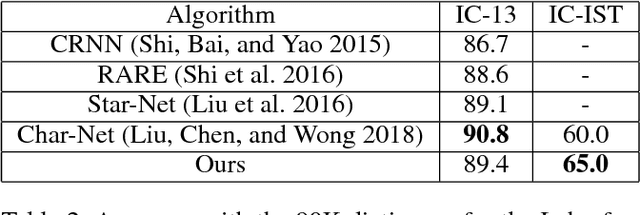
Printed text recognition is an important problem for industrial OCR systems. Printed text is constructed in a standard procedural fashion in most settings. We develop a mathematical model for this process that can be applied to the backward inference problem of text recognition from an image. Through ablation experiments we show that this model is realistic and that a multi-task objective setting can help to stabilize estimation of its free parameters, enabling use of conventional deep learning methods. Furthermore, by directly modeling the geometric perturbations of text synthesis we show that our model can help recover missing characters from incomplete text regions, the bane of multicomponent OCR systems, enabling recognition even when the detection returns incomplete information.
A Grassmannian Graph Approach to Affine Invariant Feature Matching
Feb 04, 2016
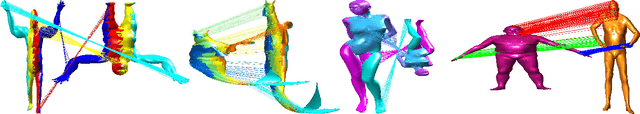
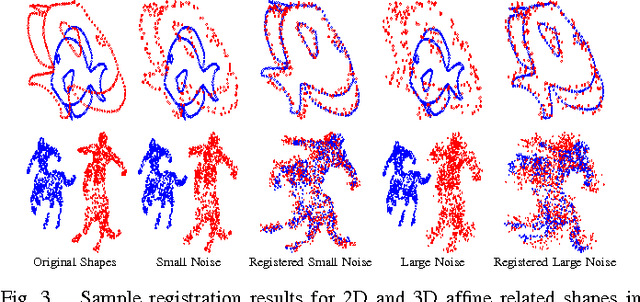

In this work, we present a novel and practical approach to address one of the longstanding problems in computer vision: 2D and 3D affine invariant feature matching. Our Grassmannian Graph (GrassGraph) framework employs a two stage procedure that is capable of robustly recovering correspondences between two unorganized, affinely related feature (point) sets. The first stage maps the feature sets to an affine invariant Grassmannian representation, where the features are mapped into the same subspace. It turns out that coordinate representations extracted from the Grassmannian differ by an arbitrary orthonormal matrix. In the second stage, by approximating the Laplace-Beltrami operator (LBO) on these coordinates, this extra orthonormal factor is nullified, providing true affine-invariant coordinates which we then utilize to recover correspondences via simple nearest neighbor relations. The resulting GrassGraph algorithm is empirically shown to work well in non-ideal scenarios with noise, outliers, and occlusions. Our validation benchmarks use an unprecedented 440,000+ experimental trials performed on 2D and 3D datasets, with a variety of parameter settings and competing methods. State-of-the-art performance in the majority of these extensive evaluations confirm the utility of our method.
Gradient density estimation in arbitrary finite dimensions using the method of stationary phase
Sep 04, 2014We prove that the density function of the gradient of a sufficiently smooth function $S : \Omega \subset \mathbb{R}^d \rightarrow \mathbb{R}$, obtained via a random variable transformation of a uniformly distributed random variable, is increasingly closely approximated by the normalized power spectrum of $\phi=\exp\left(\frac{iS}{\tau}\right)$ as the free parameter $\tau \rightarrow 0$. The result is shown using the stationary phase approximation and standard integration techniques and requires proper ordering of limits. We highlight a relationship with the well-known characteristic function approach to density estimation, and detail why our result is distinct from this approach.