 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReFocus: Visual Editing as a Chain of Thought for Structured Image Understanding
Jan 09, 2025



Structured image understanding, such as interpreting tables and charts, requires strategically refocusing across various structures and texts within an image, forming a reasoning sequence to arrive at the final answer. However, current multimodal large language models (LLMs) lack this multihop selective attention capability. In this work, we introduce ReFocus, a simple yet effective framework that equips multimodal LLMs with the ability to generate "visual thoughts" by performing visual editing on the input image through code, shifting and refining their visual focuses. Specifically, ReFocus enables multimodal LLMs to generate Python codes to call tools and modify the input image, sequentially drawing boxes, highlighting sections, and masking out areas, thereby enhancing the visual reasoning process. We experiment upon a wide range of structured image understanding tasks involving tables and charts. ReFocus largely improves performance on all tasks over GPT-4o without visual editing, yielding an average gain of 11.0% on table tasks and 6.8% on chart tasks. We present an in-depth analysis of the effects of different visual edits, and reasons why ReFocus can improve the performance without introducing additional information. Further, we collect a 14k training set using ReFocus, and prove that such visual chain-of-thought with intermediate information offers a better supervision than standard VQA data, reaching a 8.0% average gain over the same model trained with QA pairs and 2.6% over CoT.
From Characters to Words: Hierarchical Pre-trained Language Model for Open-vocabulary Language Understanding
May 23, 2023Current state-of-the-art models for natural language understanding require a preprocessing step to convert raw text into discrete tokens. This process known as tokenization relies on a pre-built vocabulary of words or sub-word morphemes. This fixed vocabulary limits the model's robustness to spelling errors and its capacity to adapt to new domains. In this work, we introduce a novel open-vocabulary language model that adopts a hierarchical two-level approach: one at the word level and another at the sequence level. Concretely, we design an intra-word module that uses a shallow Transformer architecture to learn word representations from their characters, and a deep inter-word Transformer module that contextualizes each word representation by attending to the entire word sequence. Our model thus directly operates on character sequences with explicit awareness of word boundaries, but without biased sub-word or word-level vocabulary. Experiments on various downstream tasks show that our method outperforms strong baselines. We also demonstrate that our hierarchical model is robust to textual corruption and domain shift.
Diffusion-based Document Layout Generation
Mar 19, 2023We develop a diffusion-based approach for various document layout sequence generation. Layout sequences specify the contents of a document design in an explicit format. Our novel diffusion-based approach works in the sequence domain rather than the image domain in order to permit more complex and realistic layouts. We also introduce a new metric, Document Earth Mover's Distance (Doc-EMD). By considering similarity between heterogeneous categories document designs, we handle the shortcomings of prior document metrics that only evaluate the same category of layouts. Our empirical analysis shows that our diffusion-based approach is comparable to or outperforming other previous methods for layout generation across various document datasets. Moreover, our metric is capable of differentiating documents better than previous metrics for specific cases.
Understanding Long Documents with Different Position-Aware Attentions
Aug 17, 2022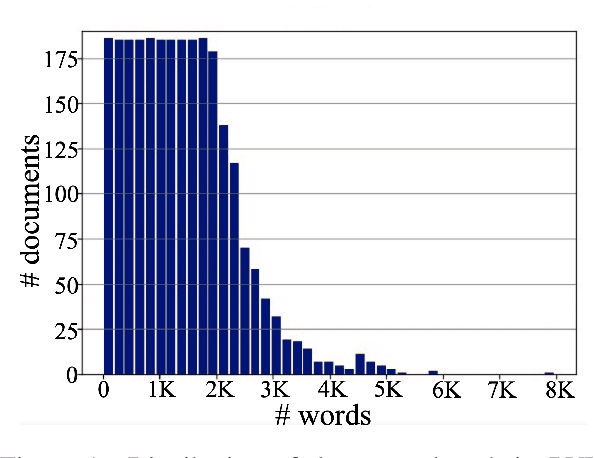
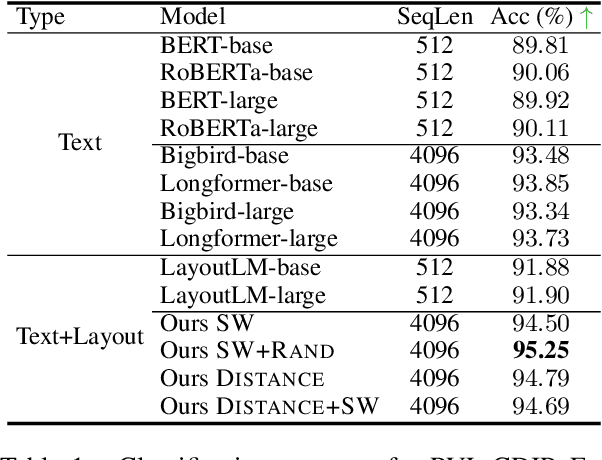
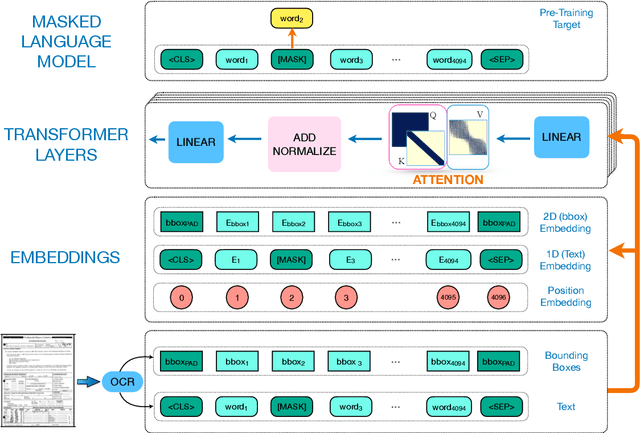
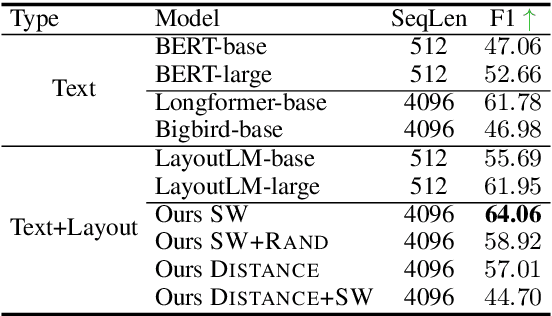
Despite several successes in document understanding, the practical task for long document understanding is largely under-explored due to several challenges in computation and how to efficiently absorb long multimodal input. Most current transformer-based approaches only deal with short documents and employ solely textual information for attention due to its prohibitive computation and memory limit. To address those issues in long document understanding, we explore different approaches in handling 1D and new 2D position-aware attention with essentially shortened context. Experimental results show that our proposed models have advantages for this task based on various evaluation metrics. Furthermore, our model makes changes only to the attention and thus can be easily adapted to any transformer-based architecture.
Improving Structured Text Recognition with Regular Expression Biasing
Nov 10, 2021
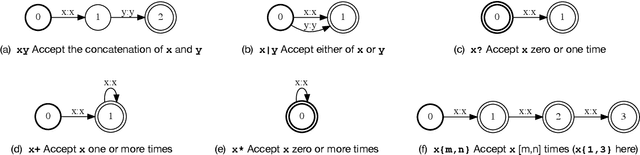
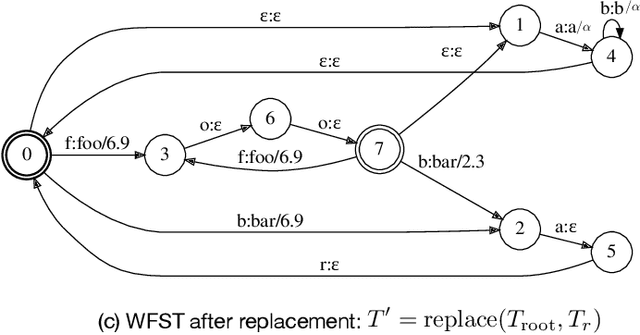

We study the problem of recognizing structured text, i.e. text that follows certain formats, and propose to improve the recognition accuracy of structured text by specifying regular expressions (regexes) for biasing. A biased recognizer recognizes text that matches the specified regexes with significantly improved accuracy, at the cost of a generally small degradation on other text. The biasing is realized by modeling regexes as a Weighted Finite-State Transducer (WFST) and injecting it into the decoder via dynamic replacement. A single hyperparameter controls the biasing strength. The method is useful for recognizing text lines with known formats or containing words from a domain vocabulary. Examples include driver license numbers, drug names in prescriptions, etc. We demonstrate the efficacy of regex biasing on datasets of printed and handwritten structured text and measures its side effects.
TrOCR: Transformer-based Optical Character Recognition with Pre-trained Models
Sep 25, 2021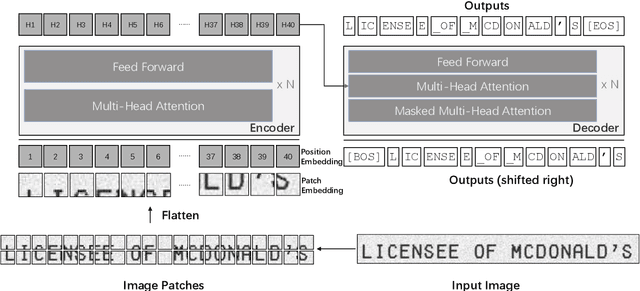

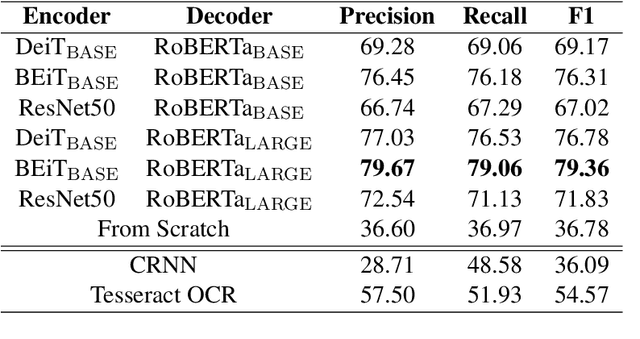
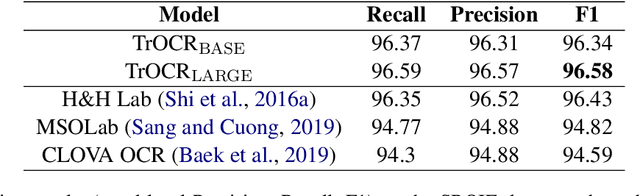
Text recognition is a long-standing research problem for document digitalization. Existing approaches for text recognition are usually built based on CNN for image understanding and RNN for char-level text generation. In addition, another language model is usually needed to improve the overall accuracy as a post-processing step. In this paper, we propose an end-to-end text recognition approach with pre-trained image Transformer and text Transformer models, namely TrOCR, which leverages the Transformer architecture for both image understanding and wordpiece-level text generation. The TrOCR model is simple but effective, and can be pre-trained with large-scale synthetic data and fine-tuned with human-labeled datasets. Experiments show that the TrOCR model outperforms the current state-of-the-art models on both printed and handwritten text recognition tasks. The code and models will be publicly available at https://aka.ms/TrOCR.
LayoutXLM: Multimodal Pre-training for Multilingual Visually-rich Document Understanding
Apr 18, 2021
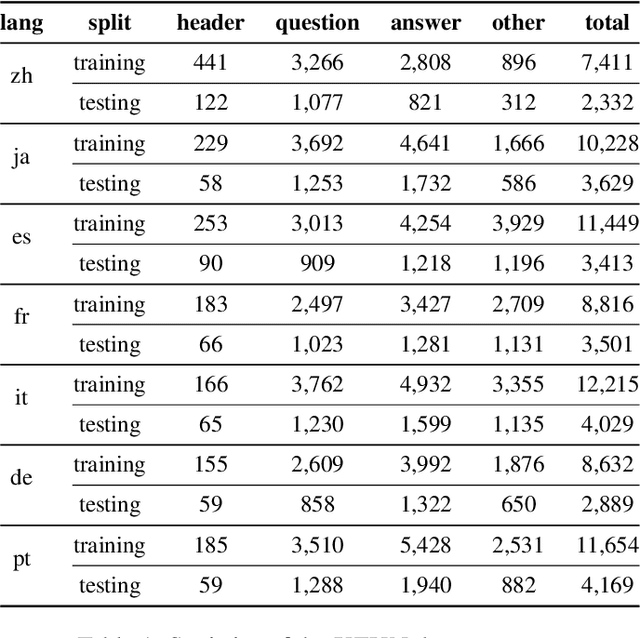
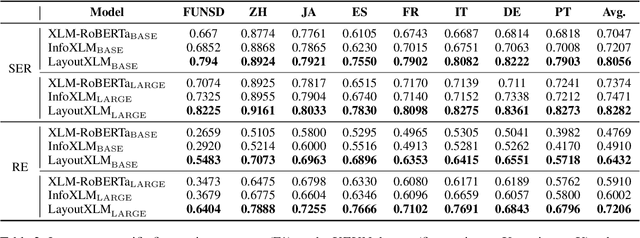
Multimodal pre-training with text, layout, and image has achieved SOTA performance for visually-rich document understanding tasks recently, which demonstrates the great potential for joint learning across different modalities. In this paper, we present LayoutXLM, a multimodal pre-trained model for multilingual document understanding, which aims to bridge the language barriers for visually-rich document understanding. To accurately evaluate LayoutXLM, we also introduce a multilingual form understanding benchmark dataset named XFUN, which includes form understanding samples in 7 languages (Chinese, Japanese, Spanish, French, Italian, German, Portuguese), and key-value pairs are manually labeled for each language. Experiment results show that the LayoutXLM model has significantly outperformed the existing SOTA cross-lingual pre-trained models on the XFUN dataset. The pre-trained LayoutXLM model and the XFUN dataset will be publicly available at https://aka.ms/layoutxlm.
LayoutLMv2: Multi-modal Pre-training for Visually-Rich Document Understanding
Dec 29, 2020
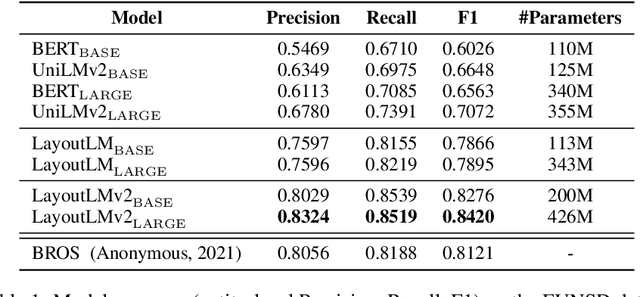
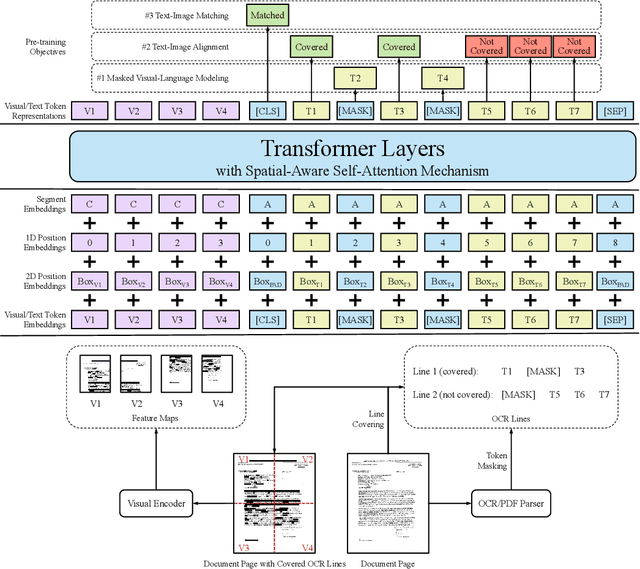
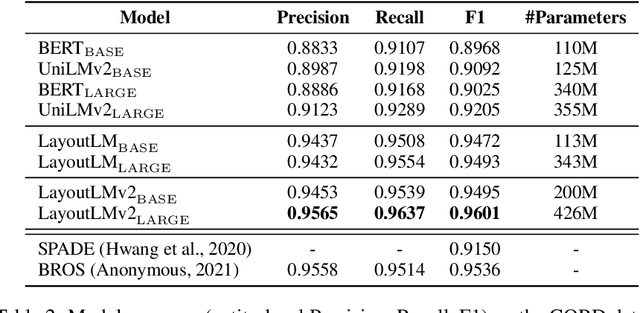
Pre-training of text and layout has proved effective in a variety of visually-rich document understanding tasks due to its effective model architecture and the advantage of large-scale unlabeled scanned/digital-born documents. In this paper, we present \textbf{LayoutLMv2} by pre-training text, layout and image in a multi-modal framework, where new model architectures and pre-training tasks are leveraged. Specifically, LayoutLMv2 not only uses the existing masked visual-language modeling task but also the new text-image alignment and text-image matching tasks in the pre-training stage, where cross-modality interaction is better learned. Meanwhile, it also integrates a spatial-aware self-attention mechanism into the Transformer architecture, so that the model can fully understand the relative positional relationship among different text blocks. Experiment results show that LayoutLMv2 outperforms strong baselines and achieves new state-of-the-art results on a wide variety of downstream visually-rich document understanding tasks, including FUNSD (0.7895 -> 0.8420), CORD (0.9493 -> 0.9601), SROIE (0.9524 -> 0.9781), Kleister-NDA (0.834 -> 0.852), RVL-CDIP (0.9443 -> 0.9564), and DocVQA (0.7295 -> 0.8672).
TAP: Text-Aware Pre-training for Text-VQA and Text-Caption
Dec 08, 2020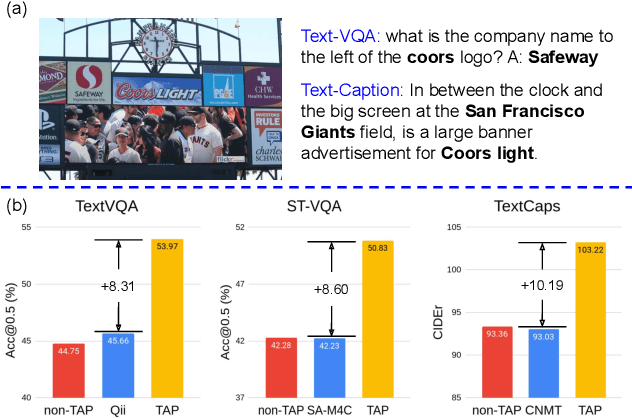
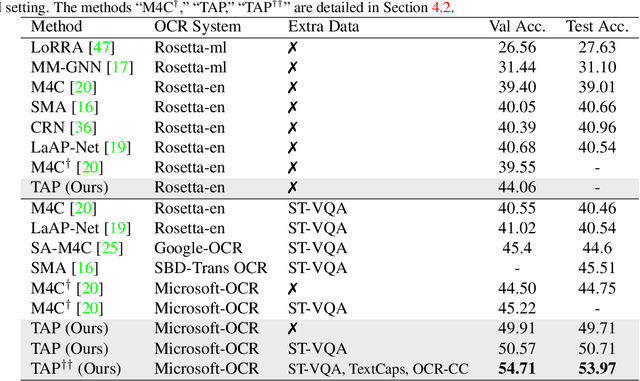
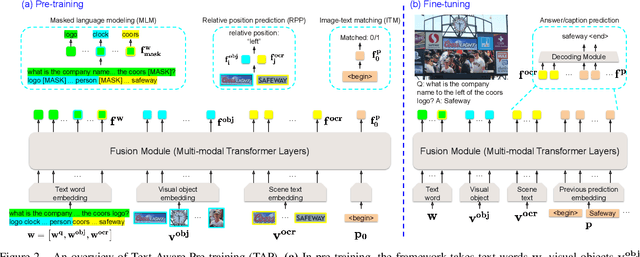
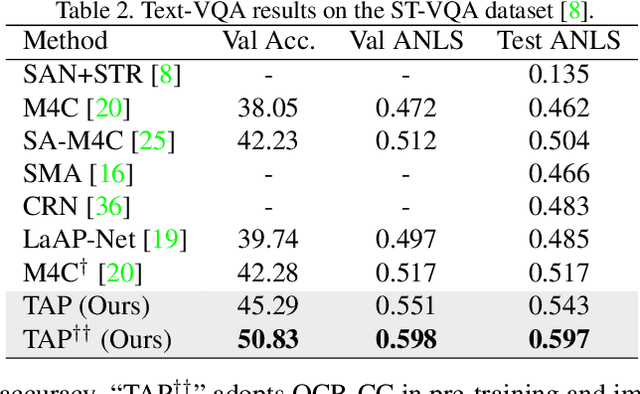
In this paper, we propose Text-Aware Pre-training (TAP) for Text-VQA and Text-Caption tasks. These two tasks aim at reading and understanding scene text in images for question answering and image caption generation, respectively. In contrast to the conventional vision-language pre-training that fails to capture scene text and its relationship with the visual and text modalities, TAP explicitly incorporates scene text (generated from OCR engines) in pre-training. With three pre-training tasks, including masked language modeling (MLM), image-text (contrastive) matching (ITM), and relative (spatial) position prediction (RPP), TAP effectively helps the model learn a better aligned representation among the three modalities: text word, visual object, and scene text. Due to this aligned representation learning, even pre-trained on the same downstream task dataset, TAP already boosts the absolute accuracy on the TextVQA dataset by +5.4%, compared with a non-TAP baseline. To further improve the performance, we build a large-scale dataset based on the Conceptual Caption dataset, named OCR-CC, which contains 1.4 million scene text-related image-text pairs. Pre-trained on this OCR-CC dataset, our approach outperforms the state of the art by large margins on multiple tasks, i.e., +8.3% accuracy on TextVQA, +8.6% accuracy on ST-VQA, and +10.2 CIDEr score on TextCaps.
RePr: Improved Training of Convolutional Filters
Nov 26, 2018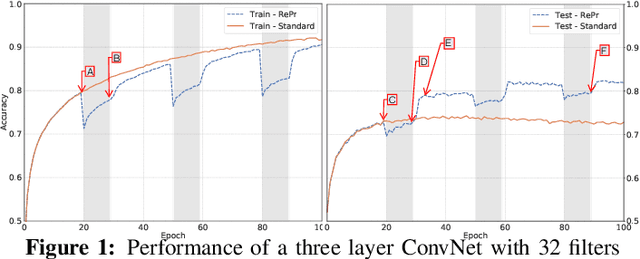
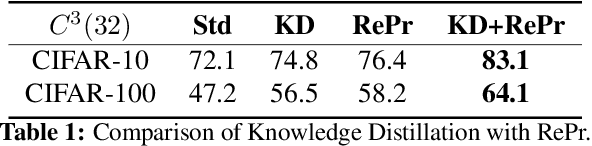

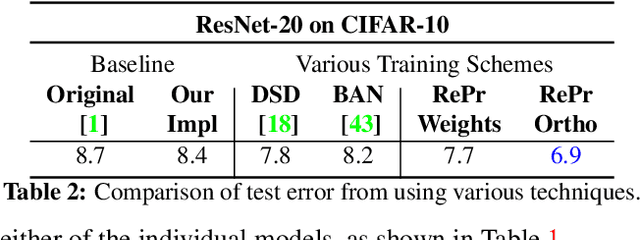
A well-trained Convolutional Neural Network can easily be pruned without significant loss of performance. This is because of unnecessary overlap in the features captured by the network's filters. Innovations in network architecture such as skip/dense connections and Inception units have mitigated this problem to some extent, but these improvements come with increased computation and memory requirements at run-time. We attempt to address this problem from another angle - not by changing the network structure but by altering the training method. We show that by temporarily pruning and then restoring a subset of the model's filters, and repeating this process cyclically, overlap in the learned features is reduced, producing improved generalization. We show that the existing model-pruning criteria are not optimal for selecting filters to prune in this context and introduce inter-filter orthogonality as the ranking criteria to determine under-expressive filters. Our method is applicable both to vanilla convolutional networks and more complex modern architectures, and improves the performance across a variety of tasks, especially when applied to smaller networks.