 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Structured Text Recognition with Regular Expression Biasing
Nov 10, 2021
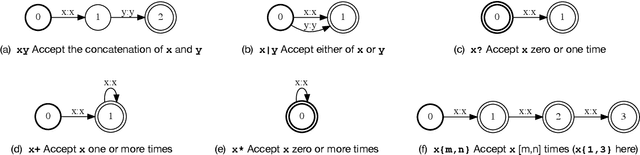
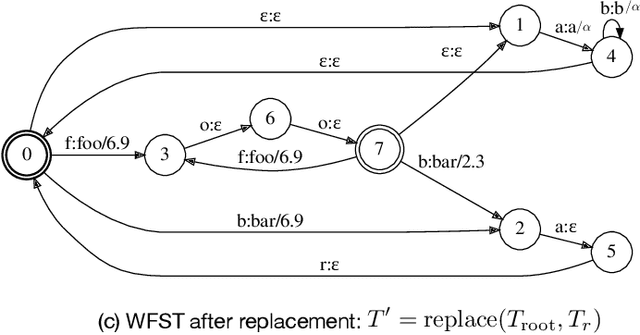

We study the problem of recognizing structured text, i.e. text that follows certain formats, and propose to improve the recognition accuracy of structured text by specifying regular expressions (regexes) for biasing. A biased recognizer recognizes text that matches the specified regexes with significantly improved accuracy, at the cost of a generally small degradation on other text. The biasing is realized by modeling regexes as a Weighted Finite-State Transducer (WFST) and injecting it into the decoder via dynamic replacement. A single hyperparameter controls the biasing strength. The method is useful for recognizing text lines with known formats or containing words from a domain vocabulary. Examples include driver license numbers, drug names in prescriptions, etc. We demonstrate the efficacy of regex biasing on datasets of printed and handwritten structured text and measures its side effects.
Progressive and Aligned Pose Attention Transfer for Person Image Generation
Mar 22, 2021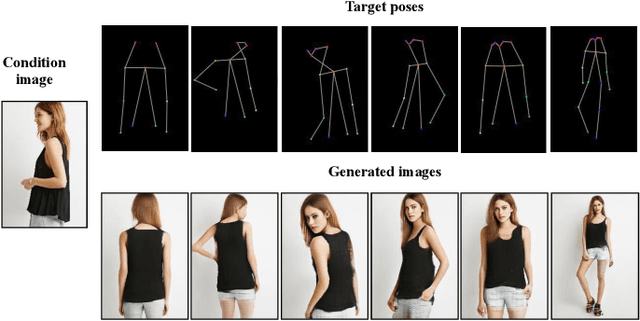
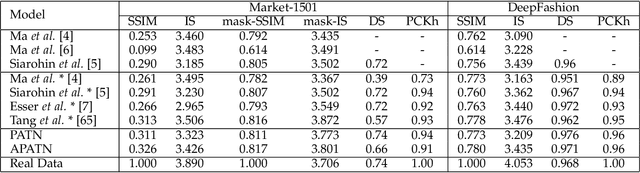
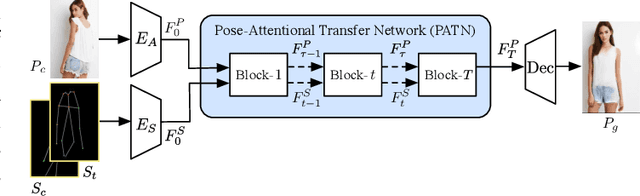
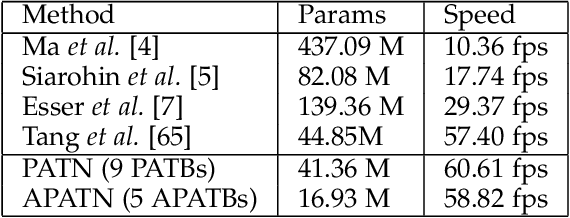
This paper proposes a new generative adversarial network for pose transfer, i.e., transferring the pose of a given person to a target pose. We design a progressive generator which comprises a sequence of transfer blocks. Each block performs an intermediate transfer step by modeling the relationship between the condition and the target poses with attention mechanism. Two types of blocks are introduced, namely Pose-Attentional Transfer Block (PATB) and Aligned Pose-Attentional Transfer Bloc ~(APATB). Compared with previous works, our model generates more photorealistic person images that retain better appearance consistency and shape consistency compared with input images. We verify the efficacy of the model on the Market-1501 and DeepFashion datasets, using quantitative and qualitative measures. Furthermore, we show that our method can be used for data augmentation for the person re-identification task, alleviating the issue of data insufficiency. Code and pretrained models are available at https://github.com/tengteng95/Pose-Transfer.git.
ICDAR 2019 Robust Reading Challenge on Reading Chinese Text on Signboard
Dec 20, 2019


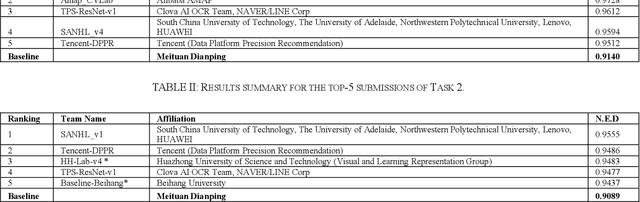
Chinese scene text reading is one of the most challenging problems in computer vision and has attracted great interest. Different from English text, Chinese has more than 6000 commonly used characters and Chinesecharacters can be arranged in various layouts with numerous fonts. The Chinese signboards in street view are a good choice for Chinese scene text images since they have different backgrounds, fonts and layouts. We organized a competition called ICDAR2019-ReCTS, which mainly focuses on reading Chinese text on signboard. This report presents the final results of the competition. A large-scale dataset of 25,000 annotated signboard images, in which all the text lines and characters are annotated with locations and transcriptions, were released. Four tasks, namely character recognition, text line recognition, text line detection and end-to-end recognition were set up. Besides, considering the Chinese text ambiguity issue, we proposed a multi ground truth (multi-GT) evaluation method to make evaluation fairer. The competition started on March 1, 2019 and ended on April 30, 2019. 262 submissions from 46 teams are received. Most of the participants come from universities, research institutes, and tech companies in China. There are also some participants from the United States, Australia, Singapore, and Korea. 21 teams submit results for Task 1, 23 teams submit results for Task 2, 24 teams submit results for Task 3, and 13 teams submit results for Task 4. The official website for the competition is http://rrc.cvc.uab.es/?ch=12.
Progressive Pose Attention Transfer for Person Image Generation
May 13, 2019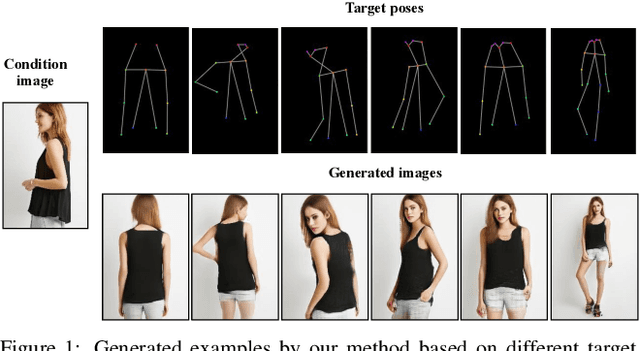
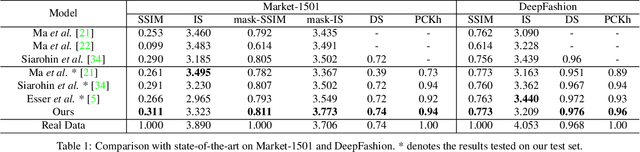
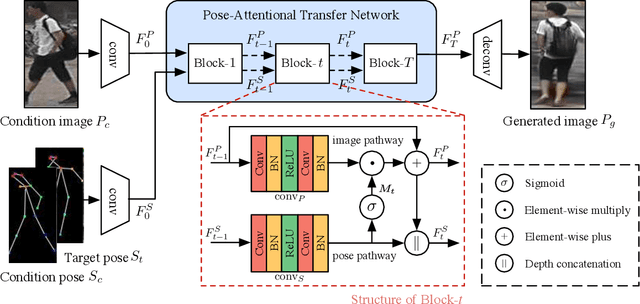
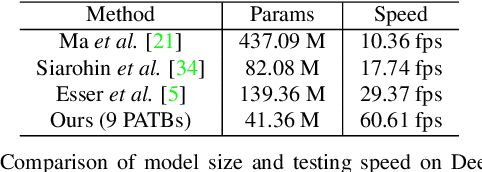
This paper proposes a new generative adversarial network for pose transfer, i.e., transferring the pose of a given person to a target pose. The generator of the network comprises a sequence of Pose-Attentional Transfer Blocks that each transfers certain regions it attends to, generating the person image progressively. Compared with those in previous works, our generated person images possess better appearance consistency and shape consistency with the input images, thus significantly more realistic-looking. The efficacy and efficiency of the proposed network are validated both qualitatively and quantitatively on Market-1501 and DeepFashion. Furthermore, the proposed architecture can generate training images for person re-identification, alleviating data insufficiency. Codes and models are available at: https://github.com/tengteng95/Pose-Transfer.git.
ICDAR2017 Competition on Reading Chinese Text in the Wild (RCTW-17)
Sep 26, 2018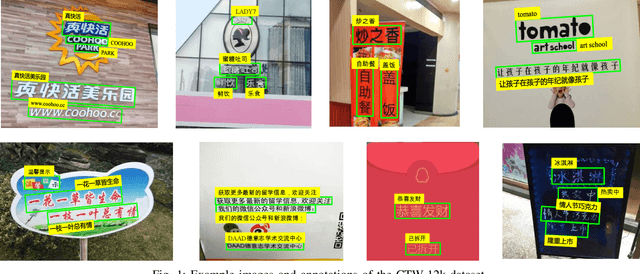
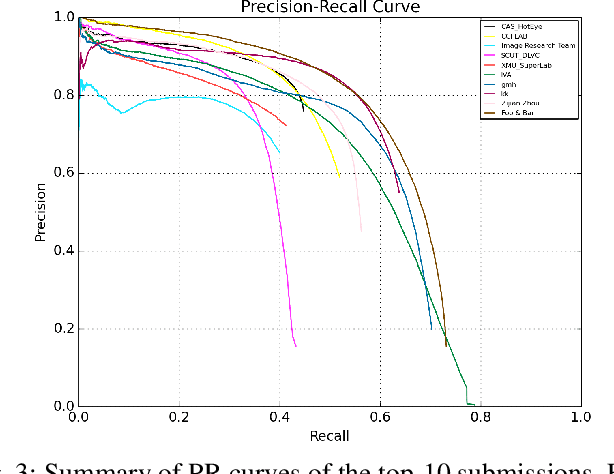
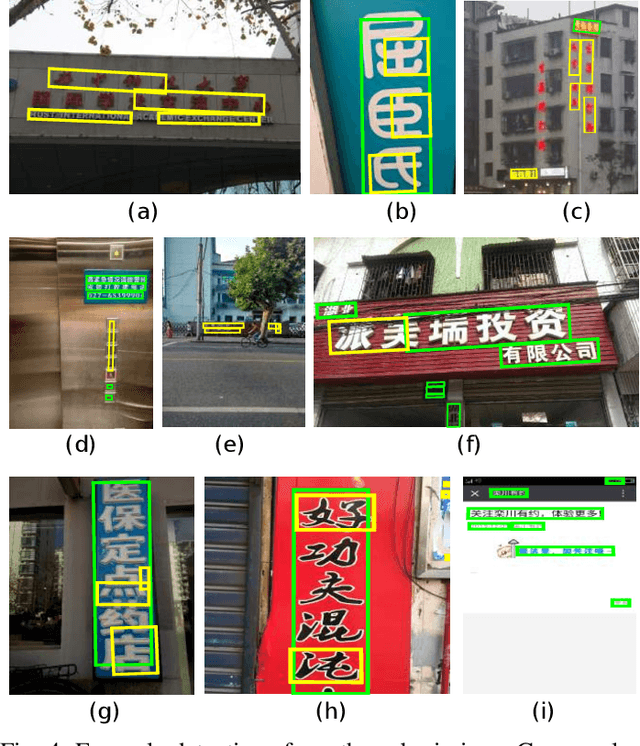
Chinese is the most widely used language in the world. Algorithms that read Chinese text in natural images facilitate applications of various kinds. Despite the large potential value, datasets and competitions in the past primarily focus on English, which bares very different characteristics than Chinese. This report introduces RCTW, a new competition that focuses on Chinese text reading. The competition features a large-scale dataset with 12,263 annotated images. Two tasks, namely text localization and end-to-end recognition, are set up. The competition took place from January 20 to May 31, 2017. 23 valid submissions were received from 19 teams. This report includes dataset description, task definitions, evaluation protocols, and results summaries and analysis. Through this competition, we call for more future research on the Chinese text reading problem. The official website for the competition is http://rctw.vlrlab.net
TextBoxes++: A Single-Shot Oriented Scene Text Detector
Apr 27, 2018

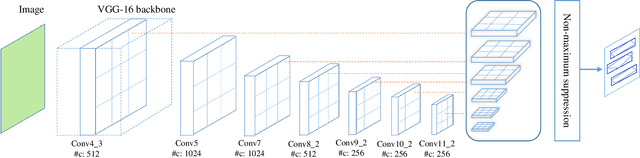
Scene text detection is an important step of scene text recognition system and also a challenging problem. Different from general object detection, the main challenges of scene text detection lie on arbitrary orientations, small sizes, and significantly variant aspect ratios of text in natural images. In this paper, we present an end-to-end trainable fast scene text detector, named TextBoxes++, which detects arbitrary-oriented scene text with both high accuracy and efficiency in a single network forward pass. No post-processing other than an efficient non-maximum suppression is involved. We have evaluated the proposed TextBoxes++ on four public datasets. In all experiments, TextBoxes++ outperforms competing methods in terms of text localization accuracy and runtime. More specifically, TextBoxes++ achieves an f-measure of 0.817 at 11.6fps for 1024*1024 ICDAR 2015 Incidental text images, and an f-measure of 0.5591 at 19.8fps for 768*768 COCO-Text images. Furthermore, combined with a text recognizer, TextBoxes++ significantly outperforms the state-of-the-art approaches for word spotting and end-to-end text recognition tasks on popular benchmarks. Code is available at: https://github.com/MhLiao/TextBoxes_plusplus
* 15 pages
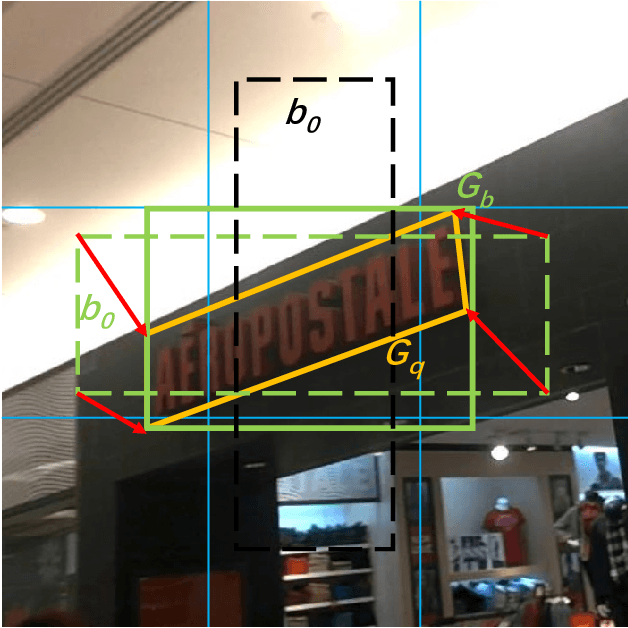
Rotation-Sensitive Regression for Oriented Scene Text Detection
Mar 14, 2018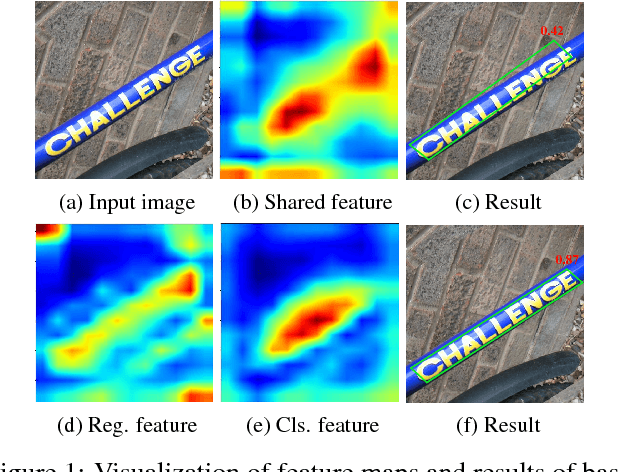
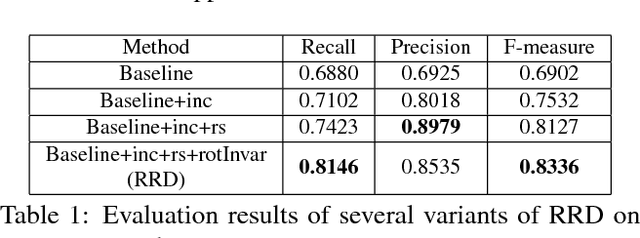

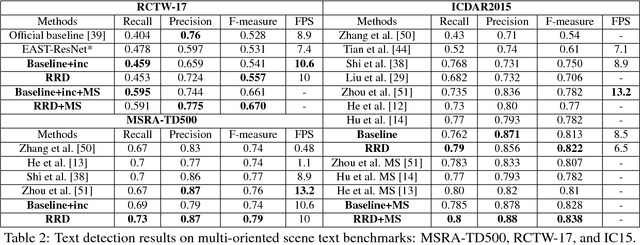
Text in natural images is of arbitrary orientations, requiring detection in terms of oriented bounding boxes. Normally, a multi-oriented text detector often involves two key tasks: 1) text presence detection, which is a classification problem disregarding text orientation; 2) oriented bounding box regression, which concerns about text orientation. Previous methods rely on shared features for both tasks, resulting in degraded performance due to the incompatibility of the two tasks. To address this issue, we propose to perform classification and regression on features of different characteristics, extracted by two network branches of different designs. Concretely, the regression branch extracts rotation-sensitive features by actively rotating the convolutional filters, while the classification branch extracts rotation-invariant features by pooling the rotation-sensitive features. The proposed method named Rotation-sensitive Regression Detector (RRD) achieves state-of-the-art performance on three oriented scene text benchmark datasets, including ICDAR 2015, MSRA-TD500, RCTW-17 and COCO-Text. Furthermore, RRD achieves a significant improvement on a ship collection dataset, demonstrating its generality on oriented object detection.
Detecting Oriented Text in Natural Images by Linking Segments
Apr 13, 2017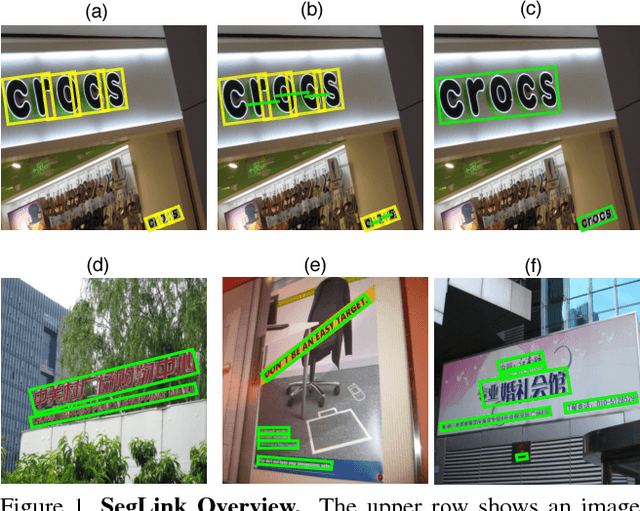
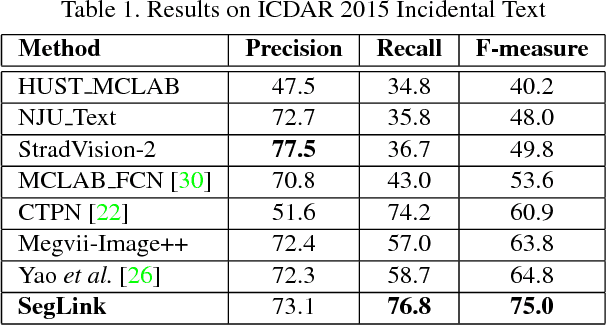
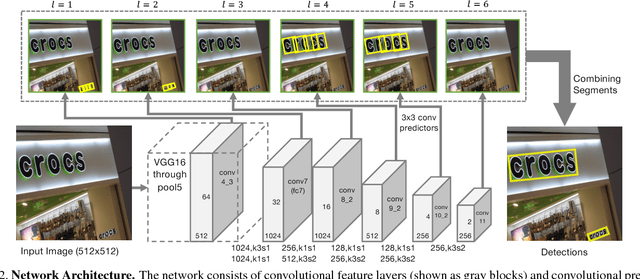
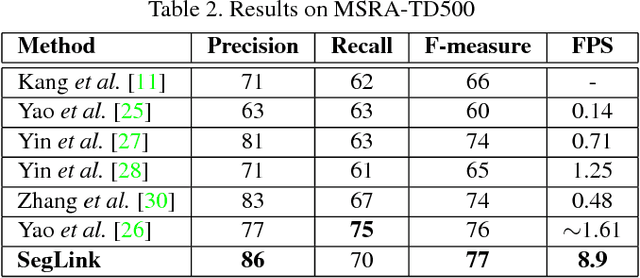
Most state-of-the-art text detection methods are specific to horizontal Latin text and are not fast enough for real-time applications. We introduce Segment Linking (SegLink), an oriented text detection method. The main idea is to decompose text into two locally detectable elements, namely segments and links. A segment is an oriented box covering a part of a word or text line; A link connects two adjacent segments, indicating that they belong to the same word or text line. Both elements are detected densely at multiple scales by an end-to-end trained, fully-convolutional neural network. Final detections are produced by combining segments connected by links. Compared with previous methods, SegLink improves along the dimensions of accuracy, speed, and ease of training. It achieves an f-measure of 75.0% on the standard ICDAR 2015 Incidental (Challenge 4) benchmark, outperforming the previous best by a large margin. It runs at over 20 FPS on 512x512 images. Moreover, without modification, SegLink is able to detect long lines of non-Latin text, such as Chinese.
TextBoxes: A Fast Text Detector with a Single Deep Neural Network
Nov 21, 2016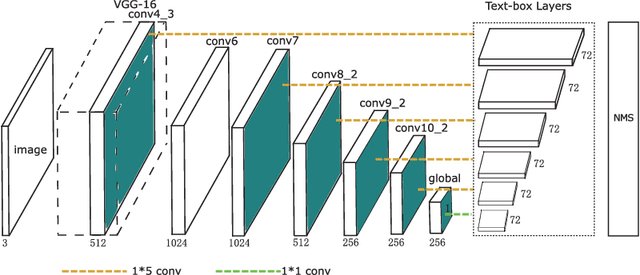
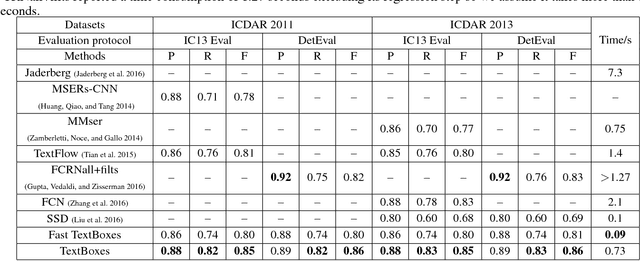
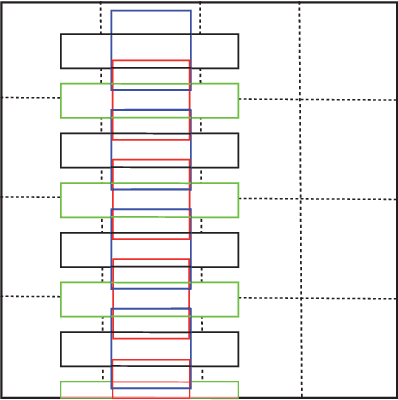
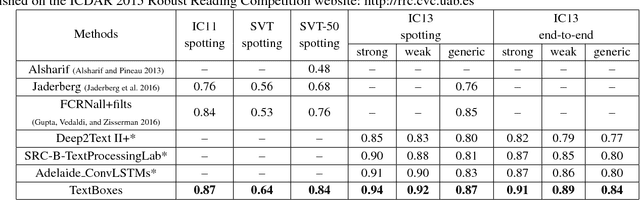
This paper presents an end-to-end trainable fast scene text detector, named TextBoxes, which detects scene text with both high accuracy and efficiency in a single network forward pass, involving no post-process except for a standard non-maximum suppression. TextBoxes outperforms competing methods in terms of text localization accuracy and is much faster, taking only 0.09s per image in a fast implementation. Furthermore, combined with a text recognizer, TextBoxes significantly outperforms state-of-the-art approaches on word spotting and end-to-end text recognition tasks.
AID: A Benchmark Dataset for Performance Evaluation of Aerial Scene Classification
Aug 18, 2016



Aerial scene classification, which aims to automatically label an aerial image with a specific semantic category, is a fundamental problem for understanding high-resolution remote sensing imagery. In recent years, it has become an active task in remote sensing area and numerous algorithms have been proposed for this task, including many machine learning and data-driven approaches. However, the existing datasets for aerial scene classification like UC-Merced dataset and WHU-RS19 are with relatively small sizes, and the results on them are already saturated. This largely limits the development of scene classification algorithms. This paper describes the Aerial Image Dataset (AID): a large-scale dataset for aerial scene classification. The goal of AID is to advance the state-of-the-arts in scene classification of remote sensing images. For creating AID, we collect and annotate more than ten thousands aerial scene images. In addition, a comprehensive review of the existing aerial scene classification techniques as well as recent widely-used deep learning methods is given. Finally, we provide a performance analysis of typical aerial scene classification and deep learning approaches on AID, which can be served as the baseline results on this benchmark.