 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeICDAR2017 Competition on Reading Chinese Text in the Wild (RCTW-17)
Paper and Code
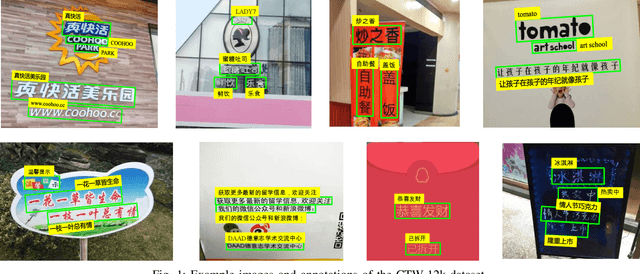
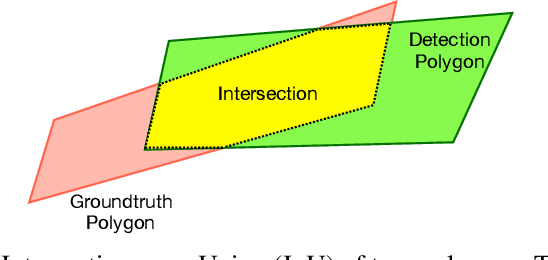
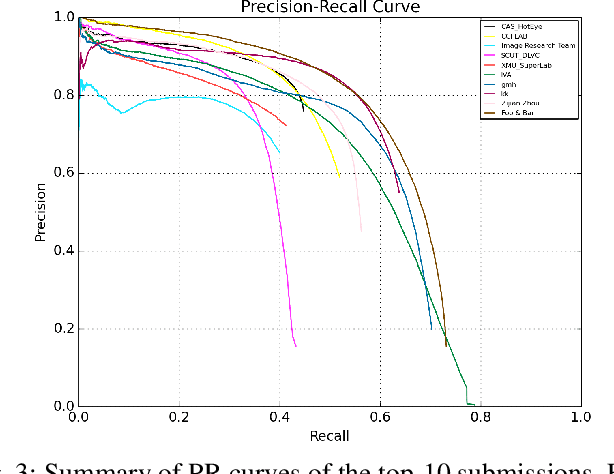
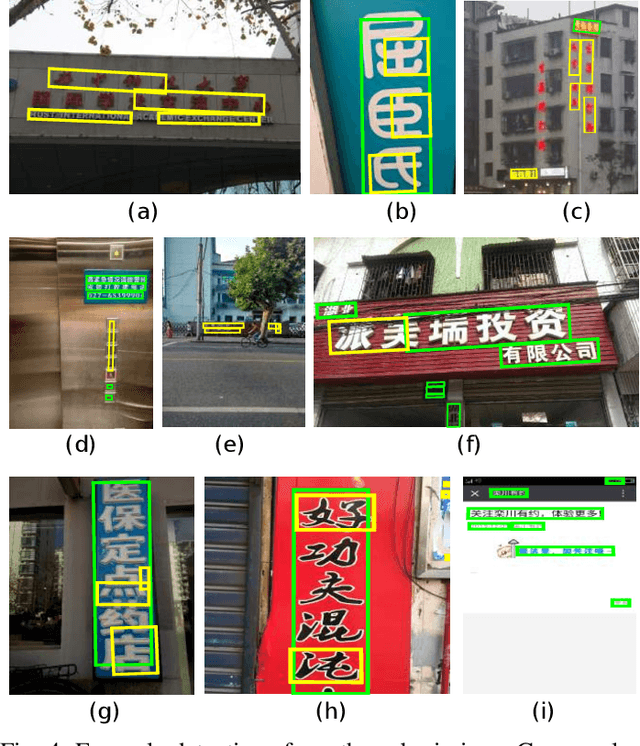
Chinese is the most widely used language in the world. Algorithms that read Chinese text in natural images facilitate applications of various kinds. Despite the large potential value, datasets and competitions in the past primarily focus on English, which bares very different characteristics than Chinese. This report introduces RCTW, a new competition that focuses on Chinese text reading. The competition features a large-scale dataset with 12,263 annotated images. Two tasks, namely text localization and end-to-end recognition, are set up. The competition took place from January 20 to May 31, 2017. 23 valid submissions were received from 19 teams. This report includes dataset description, task definitions, evaluation protocols, and results summaries and analysis. Through this competition, we call for more future research on the Chinese text reading problem. The official website for the competition is http://rctw.vlrlab.net