 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMUSIC: Learning Muscle-Driven Dexterous Hand Control
Apr 26, 2026We present a data-driven approach for physics-based, muscle-driven dexterous control that enables musculoskeletal hands to perform precise piano playing for novel pieces of music outside the reference dataset. Our approach combines high-frequency muscle-level control with low-frequency latent-space coordination in a hierarchical architecture. At the low level, general single-hand policies are trained via reinforcement learning to generate dynamic muscle-tendon activations while tracking trajectories from a large reference motion dataset. The resulting tracking policies are then distilled into variational autoencoder (VAE) models, yielding smooth and structured latent spaces that abstract away low-level muscle dynamics. For the high level, we train piece-specific policies to operate in this latent space, coordinating bimanual motions based on specific goals, denoted by note events extracted from given musical scores, to synthesize performances beyond the reference data. In addition, we present an enhanced musculoskeletal hand model that supports fine control of fingers for accurate low-level motion tracking and diverse high-level motion synthesis. We evaluate the control pipeline of our approach on a diverse piano repertoire spanning multiple musical styles and technical demands. Results demonstrate that our approach can synthesize coordinated bimanual motions with accurate key presses, and achieve the state-of-the-art performance of piano playing in physics-based dexterous control. We also show that our musculoskeletal hand model demonstrates superior biomechanical stability and tracking precision compared to the existing model, and validate that our musculoskeletal hand model and muscle-driven controller can generate physiologically plausible activation patterns that align with human electromyography (EMG) recordings.
AtomicVLA: Unlocking the Potential of Atomic Skill Learning in Robots
Mar 08, 2026Recent advances in Visual-Language-Action (VLA) models have shown promising potential for robotic manipulation tasks. However, real-world robotic tasks often involve long-horizon, multi-step problem-solving and require generalization for continual skill acquisition, extending beyond single actions or skills. These challenges present significant barriers for existing VLA models, which use monolithic action decoders trained on aggregated data, resulting in poor scalability. To address these challenges, we propose AtomicVLA, a unified planning-and-execution framework that jointly generates task-level plans, atomic skill abstractions, and fine-grained actions. AtomicVLA constructs a scalable atomic skill library through a Skill-Guided Mixture-of-Experts (SG-MoE), where each expert specializes in mastering generic yet precise atomic skills. Furthermore, we introduce a flexible routing encoder that automatically assigns dedicated atomic experts to new skills, enabling continual learning. We validate our approach through extensive experiments. In simulation, AtomicVLA outperforms $π_{0}$ by 2.4\% on LIBERO, 10\% on LIBERO-LONG, and outperforms $π_{0}$ and $π_{0.5}$ by 0.22 and 0.25 in average task length on CALVIN. Additionally, our AtomicVLA consistently surpasses baselines by 18.3\% and 21\% in real-world long-horizon tasks and continual learning. These results highlight the effectiveness of atomic skill abstraction and dynamic expert composition for long-horizon and lifelong robotic tasks. The project page is \href{https://zhanglk9.github.io/atomicvla-web/}{here}.
KrwEmd: Revising the Imperfect-Recall Abstraction from Forgetting Everything
Nov 15, 2025Excessive abstraction is a critical challenge in hand abstraction-a task specific to games like Texas hold'em-when solving large-scale imperfect-information games, as it impairs AI performance. This issue arises from extreme implementations of imperfect-recall abstraction, which entirely discard historical information. This paper presents KrwEmd, the first practical algorithm designed to address this problem. We first introduce the k-recall winrate feature, which not only qualitatively distinguishes signal observation infosets by leveraging both future and, crucially, historical game information, but also quantitatively captures their similarity. We then develop the KrwEmd algorithm, which clusters signal observation infosets using earth mover's distance to measure discrepancies between their features. Experimental results demonstrate that KrwEmd significantly improves AI gameplay performance compared to existing algorithms.
No-Regret Strategy Solving in Imperfect-Information Games via Pre-Trained Embedding
Nov 15, 2025High-quality information set abstraction remains a core challenge in solving large-scale imperfect-information extensive-form games (IIEFGs)-such as no-limit Texas Hold'em-where the finite nature of spatial resources hinders strategy solving over the full game. State-of-the-art AI methods rely on pre-trained discrete clustering for abstraction, yet their hard classification irreversibly loses critical information: specifically, the quantifiable subtle differences between information sets-vital for strategy solving-thereby compromising the quality of such solving. Inspired by the word embedding paradigm in natural language processing, this paper proposes the Embedding CFR algorithm, a novel approach for solving strategies in IIEFGs within an embedding space. The algorithm pre-trains and embeds features of isolated information sets into an interconnected low-dimensional continuous space, where the resulting vectors more precisely capture both the distinctions and connections between information sets. Embedding CFR presents a strategy-solving process driven by regret accumulation and strategy updates within this embedding space, with accompanying theoretical analysis verifying its capacity to reduce cumulative regret. Experiments on poker show that with the same spatial overhead, Embedding CFR achieves significantly faster exploitability convergence compared to cluster-based abstraction algorithms, confirming its effectiveness. Furthermore, to our knowledge, it is the first algorithm in poker AI that pre-trains information set abstractions through low-dimensional embedding for strategy solving.
Retargeting Matters: General Motion Retargeting for Humanoid Motion Tracking
Oct 02, 2025Humanoid motion tracking policies are central to building teleoperation pipelines and hierarchical controllers, yet they face a fundamental challenge: the embodiment gap between humans and humanoid robots. Current approaches address this gap by retargeting human motion data to humanoid embodiments and then training reinforcement learning (RL) policies to imitate these reference trajectories. However, artifacts introduced during retargeting, such as foot sliding, self-penetration, and physically infeasible motion are often left in the reference trajectories for the RL policy to correct. While prior work has demonstrated motion tracking abilities, they often require extensive reward engineering and domain randomization to succeed. In this paper, we systematically evaluate how retargeting quality affects policy performance when excessive reward tuning is suppressed. To address issues that we identify with existing retargeting methods, we propose a new retargeting method, General Motion Retargeting (GMR). We evaluate GMR alongside two open-source retargeters, PHC and ProtoMotions, as well as with a high-quality closed-source dataset from Unitree. Using BeyondMimic for policy training, we isolate retargeting effects without reward tuning. Our experiments on a diverse subset of the LAFAN1 dataset reveal that while most motions can be tracked, artifacts in retargeted data significantly reduce policy robustness, particularly for dynamic or long sequences. GMR consistently outperforms existing open-source methods in both tracking performance and faithfulness to the source motion, achieving perceptual fidelity and policy success rates close to the closed-source baseline. Website: https://jaraujo98.github.io/retargeting_matters. Code: https://github.com/YanjieZe/GMR.
Learning to Ball: Composing Policies for Long-Horizon Basketball Moves
Sep 26, 2025

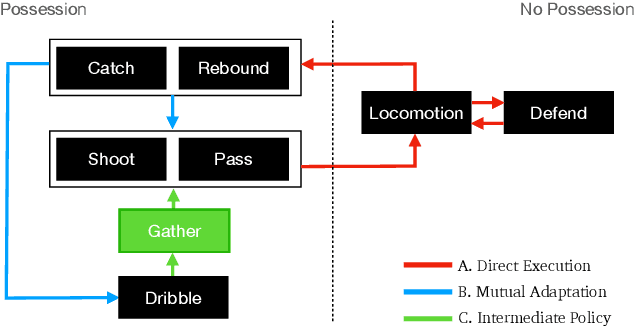

Learning a control policy for a multi-phase, long-horizon task, such as basketball maneuvers, remains challenging for reinforcement learning approaches due to the need for seamless policy composition and transitions between skills. A long-horizon task typically consists of distinct subtasks with well-defined goals, separated by transitional subtasks with unclear goals but critical to the success of the entire task. Existing methods like the mixture of experts and skill chaining struggle with tasks where individual policies do not share significant commonly explored states or lack well-defined initial and terminal states between different phases. In this paper, we introduce a novel policy integration framework to enable the composition of drastically different motor skills in multi-phase long-horizon tasks with ill-defined intermediate states. Based on that, we further introduce a high-level soft router to enable seamless and robust transitions between the subtasks. We evaluate our framework on a set of fundamental basketball skills and challenging transitions. Policies trained by our approach can effectively control the simulated character to interact with the ball and accomplish the long-horizon task specified by real-time user commands, without relying on ball trajectory references.
* ACM Transactions on Graphics (Proceedings of SIGGRAPH Asia 2025). Website: http://pei-xu.github.io/basketball. Video: https://youtu.be/2RBFIjjmR2I. Code: https://github.com/xupei0610/basketball
WGSR-Bench: Wargame-based Game-theoretic Strategic Reasoning Benchmark for Large Language Models
Jun 12, 2025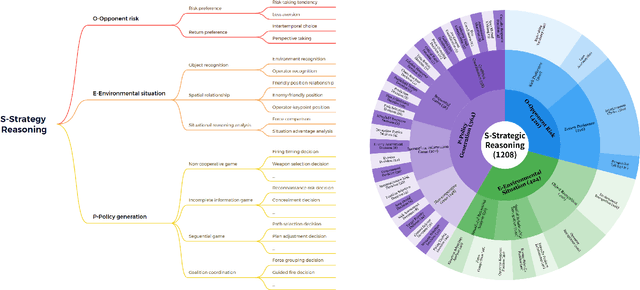
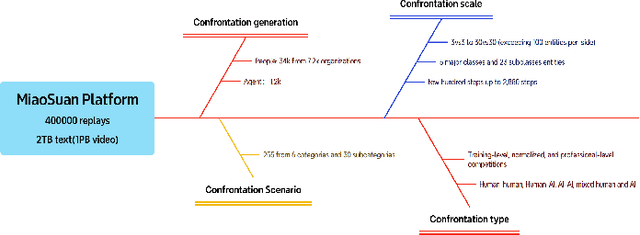
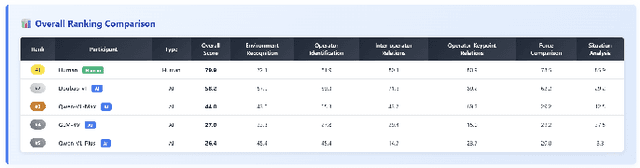
Recent breakthroughs in Large Language Models (LLMs) have led to a qualitative leap in artificial intelligence' s performance on reasoning tasks, particularly demonstrating remarkable capabilities in mathematical, symbolic, and commonsense reasoning. However, as a critical component of advanced human cognition, strategic reasoning, i.e., the ability to assess multi-agent behaviors in dynamic environments, formulate action plans, and adapt strategies, has yet to be systematically evaluated or modeled. To address this gap, this paper introduces WGSR-Bench, the first strategy reasoning benchmark for LLMs using wargame as its evaluation environment. Wargame, a quintessential high-complexity strategic scenario, integrates environmental uncertainty, adversarial dynamics, and non-unique strategic choices, making it an effective testbed for assessing LLMs' capabilities in multi-agent decision-making, intent inference, and counterfactual reasoning. WGSR-Bench designs test samples around three core tasks, i.e., Environmental situation awareness, Opponent risk modeling and Policy generation, which serve as the core S-POE architecture, to systematically assess main abilities of strategic reasoning. Finally, an LLM-based wargame agent is designed to integrate these parts for a comprehensive strategy reasoning assessment. With WGSR-Bench, we hope to assess the strengths and limitations of state-of-the-art LLMs in game-theoretic strategic reasoning and to advance research in large model-driven strategic intelligence.
FürElise: Capturing and Physically Synthesizing Hand Motions of Piano Performance
Oct 08, 2024Piano playing requires agile, precise, and coordinated hand control that stretches the limits of dexterity. Hand motion models with the sophistication to accurately recreate piano playing have a wide range of applications in character animation, embodied AI, biomechanics, and VR/AR. In this paper, we construct a first-of-its-kind large-scale dataset that contains approximately 10 hours of 3D hand motion and audio from 15 elite-level pianists playing 153 pieces of classical music. To capture natural performances, we designed a markerless setup in which motions are reconstructed from multi-view videos using state-of-the-art pose estimation models. The motion data is further refined via inverse kinematics using the high-resolution MIDI key-pressing data obtained from sensors in a specialized Yamaha Disklavier piano. Leveraging the collected dataset, we developed a pipeline that can synthesize physically-plausible hand motions for musical scores outside of the dataset. Our approach employs a combination of imitation learning and reinforcement learning to obtain policies for physics-based bimanual control involving the interaction between hands and piano keys. To solve the sampling efficiency problem with the large motion dataset, we use a diffusion model to generate natural reference motions, which provide high-level trajectory and fingering (finger order and placement) information. However, the generated reference motion alone does not provide sufficient accuracy for piano performance modeling. We then further augmented the data by using musical similarity to retrieve similar motions from the captured dataset to boost the precision of the RL policy. With the proposed method, our model generates natural, dexterous motions that generalize to music from outside the training dataset.
AdaptNet: Policy Adaptation for Physics-Based Character Control
Oct 09, 2023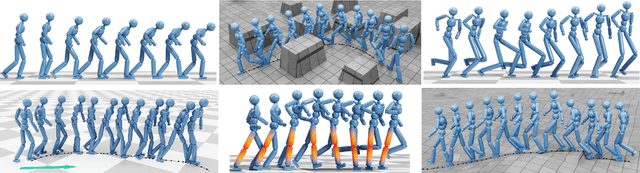
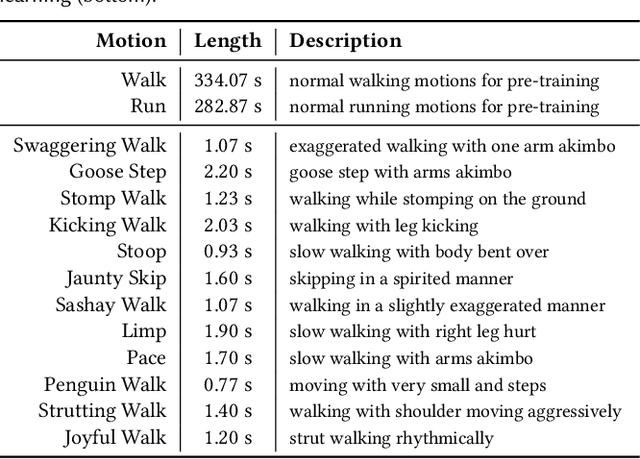
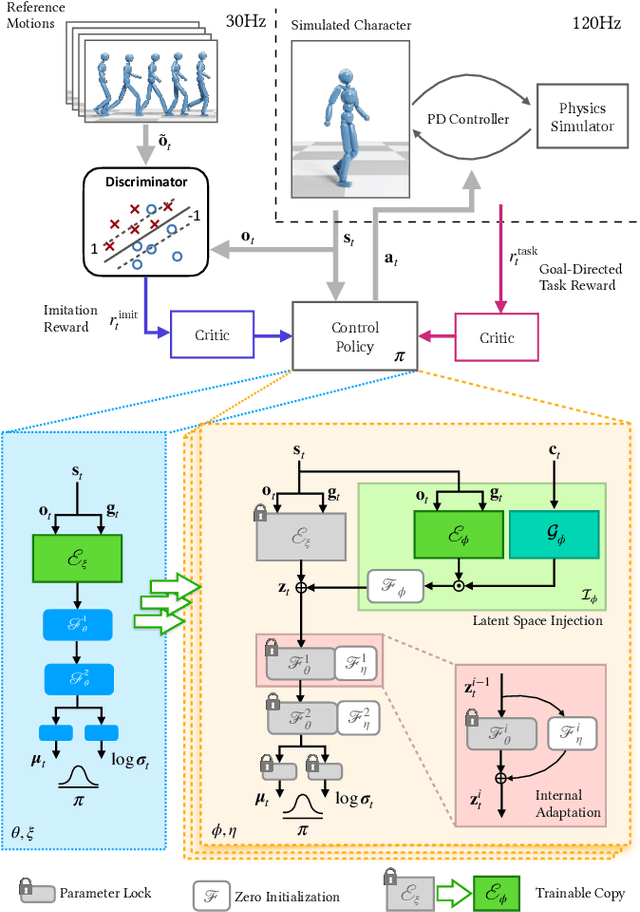
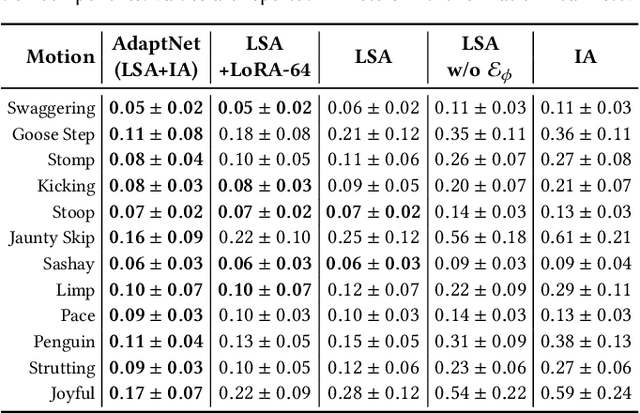
Motivated by humans' ability to adapt skills in the learning of new ones, this paper presents AdaptNet, an approach for modifying the latent space of existing policies to allow new behaviors to be quickly learned from like tasks in comparison to learning from scratch. Building on top of a given reinforcement learning controller, AdaptNet uses a two-tier hierarchy that augments the original state embedding to support modest changes in a behavior and further modifies the policy network layers to make more substantive changes. The technique is shown to be effective for adapting existing physics-based controllers to a wide range of new styles for locomotion, new task targets, changes in character morphology and extensive changes in environment. Furthermore, it exhibits significant increase in learning efficiency, as indicated by greatly reduced training times when compared to training from scratch or using other approaches that modify existing policies. Code is available at https://motion-lab.github.io/AdaptNet.
* SIGGRAPH Asia 2023. Video: https://youtu.be/WxmJSCNFb28. Website: https://motion-lab.github.io/AdaptNet, https://pei-xu.github.io/AdaptNet
Composite Motion Learning with Task Control
May 05, 2023



We present a deep learning method for composite and task-driven motion control for physically simulated characters. In contrast to existing data-driven approaches using reinforcement learning that imitate full-body motions, we learn decoupled motions for specific body parts from multiple reference motions simultaneously and directly by leveraging the use of multiple discriminators in a GAN-like setup. In this process, there is no need of any manual work to produce composite reference motions for learning. Instead, the control policy explores by itself how the composite motions can be combined automatically. We further account for multiple task-specific rewards and train a single, multi-objective control policy. To this end, we propose a novel framework for multi-objective learning that adaptively balances the learning of disparate motions from multiple sources and multiple goal-directed control objectives. In addition, as composite motions are typically augmentations of simpler behaviors, we introduce a sample-efficient method for training composite control policies in an incremental manner, where we reuse a pre-trained policy as the meta policy and train a cooperative policy that adapts the meta one for new composite tasks. We show the applicability of our approach on a variety of challenging multi-objective tasks involving both composite motion imitation and multiple goal-directed control.
* SIGGRAPH 2023. Code: https://github.com/xupei0610/CompositeMotion. Video: https://youtu.be/mcRAxwoTh3E