 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Reinforcement Learning for Localizability-Enhanced Navigation in Dynamic Human Environments
Mar 22, 2023Reliable localization is crucial for autonomous robots to navigate efficiently and safely. Some navigation methods can plan paths with high localizability (which describes the capability of acquiring reliable localization). By following these paths, the robot can access the sensor streams that facilitate more accurate location estimation results by the localization algorithms. However, most of these methods require prior knowledge and struggle to adapt to unseen scenarios or dynamic changes. To overcome these limitations, we propose a novel approach for localizability-enhanced navigation via deep reinforcement learning in dynamic human environments. Our proposed planner automatically extracts geometric features from 2D laser data that are helpful for localization. The planner learns to assign different importance to the geometric features and encourages the robot to navigate through areas that are helpful for laser localization. To facilitate the learning of the planner, we suggest two techniques: (1) an augmented state representation that considers the dynamic changes and the confidence of the localization results, which provides more information and allows the robot to make better decisions, (2) a reward metric that is capable to offer both sparse and dense feedback on behaviors that affect localization accuracy. Our method exhibits significant improvements in lost rate and arrival rate when tested in previously unseen environments.
Learning to Socially Navigate in Pedestrian-rich Environments with Interaction Capacity
Mar 30, 2022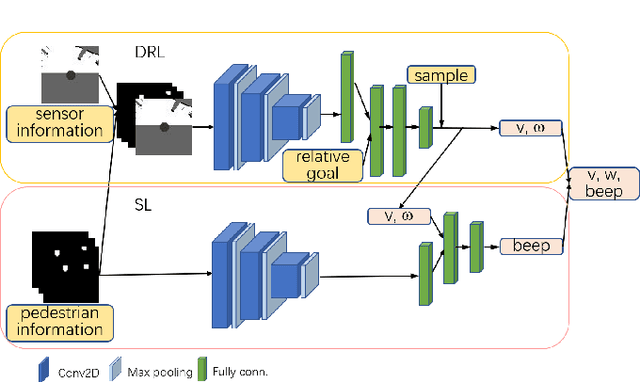
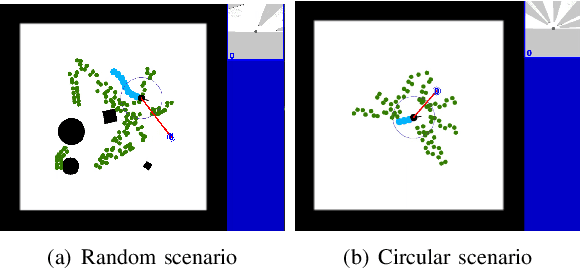
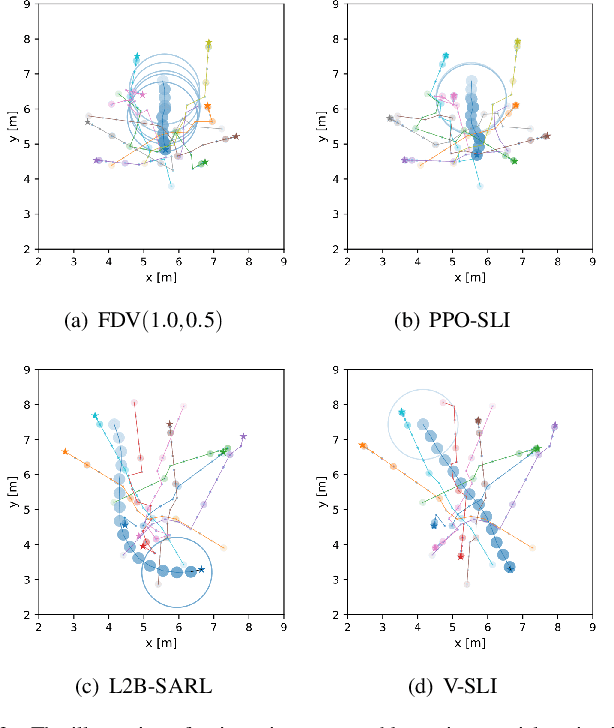
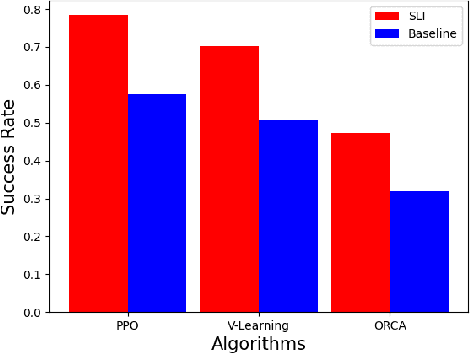
Existing navigation policies for autonomous robots tend to focus on collision avoidance while ignoring human-robot interactions in social life. For instance, robots can pass along the corridor safer and easier if pedestrians notice them. Sounds have been considered as an efficient way to attract the attention of pedestrians, which can alleviate the freezing robot problem. In this work, we present a new deep reinforcement learning (DRL) based social navigation approach for autonomous robots to move in pedestrian-rich environments with interaction capacity. Most existing DRL based methods intend to train a general policy that outputs both navigation actions, i.e., expected robot's linear and angular velocities, and interaction actions, i.e., the beep action, in the context of reinforcement learning. Different from these methods, we intend to train the policy via both supervised learning and reinforcement learning. In specific, we first train an interaction policy in the context of supervised learning, which provides a better understanding of the social situation, then we use this interaction policy to train the navigation policy via multiple reinforcement learning algorithms. We evaluate our approach in various simulation environments and compare it to other methods. The experimental results show that our approach outperforms others in terms of the success rate. We also deploy the trained policy on a real-world robot, which shows a nice performance in crowded environments.
Crowd-Aware Robot Navigation for Pedestrians with Multiple Collision Avoidance Strategies via Map-based Deep Reinforcement Learning
Sep 06, 2021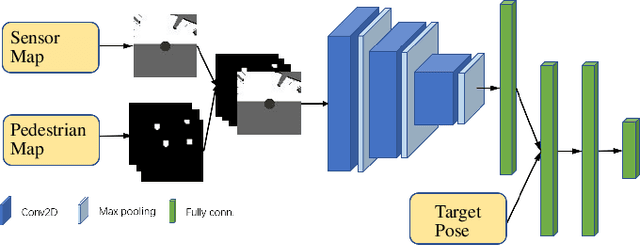
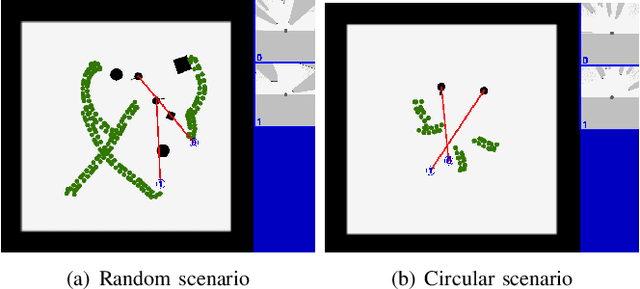
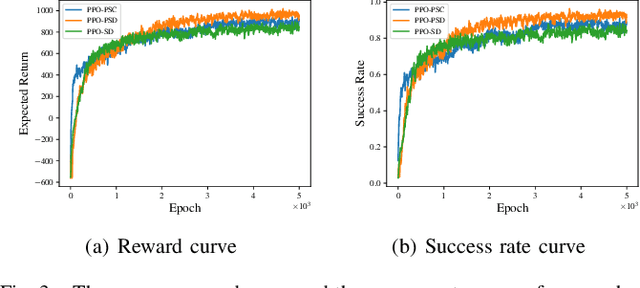
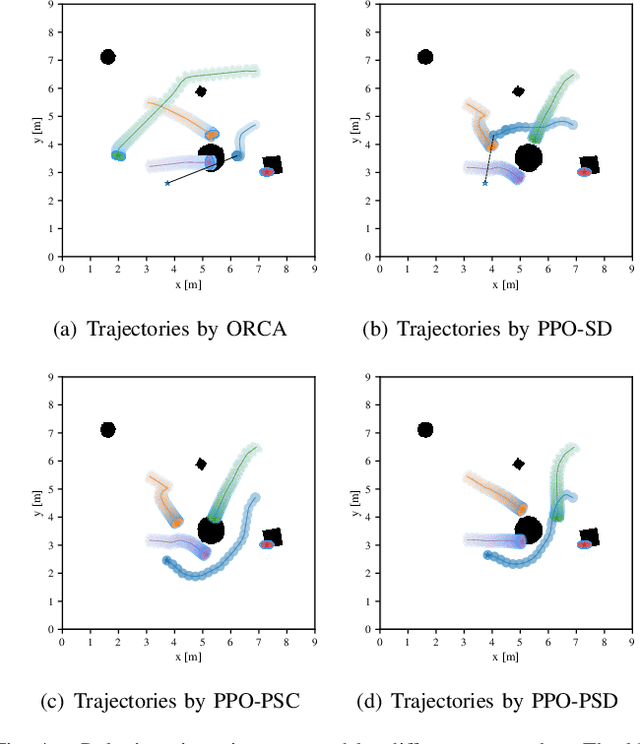
It is challenging for a mobile robot to navigate through human crowds. Existing approaches usually assume that pedestrians follow a predefined collision avoidance strategy, like social force model (SFM) or optimal reciprocal collision avoidance (ORCA). However, their performances commonly need to be further improved for practical applications, where pedestrians follow multiple different collision avoidance strategies. In this paper, we propose a map-based deep reinforcement learning approach for crowd-aware robot navigation with various pedestrians. We use the sensor map to represent the environmental information around the robot, including its shape and observable appearances of obstacles. We also introduce the pedestrian map that specifies the movements of pedestrians around the robot. By applying both maps as inputs of the neural network, we show that a navigation policy can be trained to better interact with pedestrians following different collision avoidance strategies. We evaluate our approach under multiple scenarios both in the simulator and on an actual robot. The results show that our approach allows the robot to successfully interact with various pedestrians and outperforms compared methods in terms of the success rate.
Reinforcement Learning for Robot Navigation with Adaptive ExecutionDuration (AED) in a Semi-Markov Model
Aug 30, 2021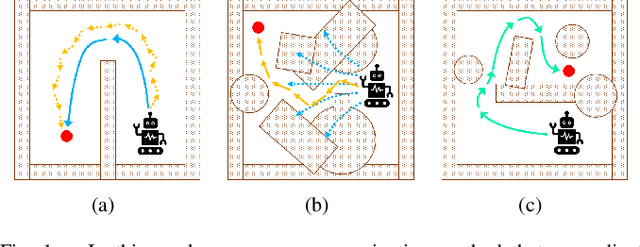
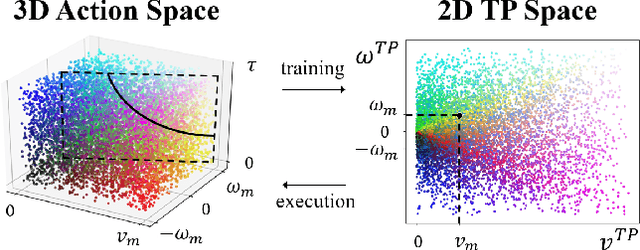
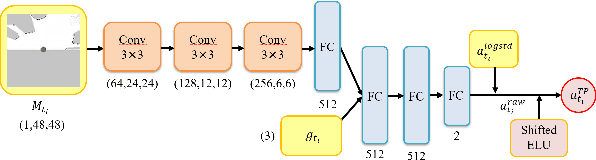
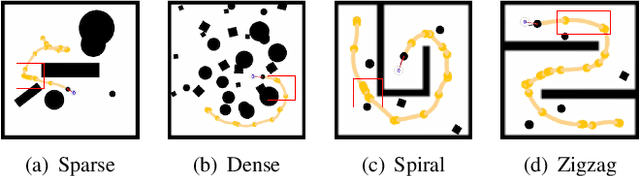
Deep reinforcement learning (DRL) algorithms have proven effective in robot navigation, especially in unknown environments, through directly mapping perception inputs into robot control commands. Most existing methods adopt uniform execution duration with robots taking commands at fixed intervals. As such, the length of execution duration becomes a crucial parameter to the navigation algorithm. In particular, if the duration is too short, then the navigation policy would be executed at a high frequency, with increased training difficulty and high computational cost. Meanwhile, if the duration is too long, then the policy becomes unable to handle complex situations, like those with crowded obstacles. It is thus tricky to find the "sweet" duration range; some duration values may render a DRL model to fail to find a navigation path. In this paper, we propose to employ adaptive execution duration to overcome this problem. Specifically, we formulate the navigation task as a Semi-Markov Decision Process (SMDP) problem to handle adaptive execution duration. We also improve the distributed proximal policy optimization (DPPO) algorithm and provide its theoretical guarantee for the specified SMDP problem. We evaluate our approach both in the simulator and on an actual robot. The results show that our approach outperforms the other DRL-based method (with fixed execution duration) by 10.3% in terms of the navigation success rate.
DRQN-based 3D Obstacle Avoidance with a Limited Field of View
Aug 12, 2021
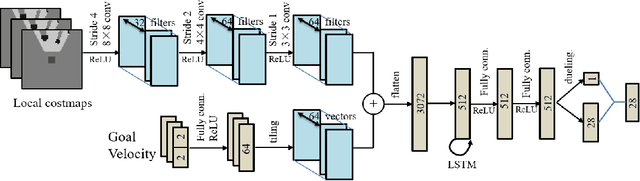
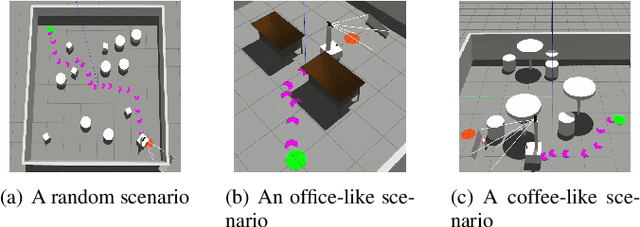
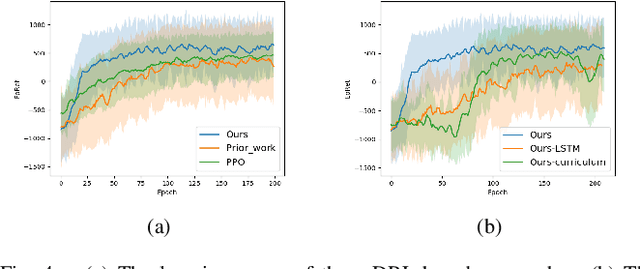
In this paper, we propose a map-based end-to-end DRL approach for three-dimensional (3D) obstacle avoidance in a partially observed environment, which is applied to achieve autonomous navigation for an indoor mobile robot using a depth camera with a narrow field of view. We first train a neural network with LSTM units in a 3D simulator of mobile robots to approximate the Q-value function in double DRQN. We also use a curriculum learning strategy to accelerate and stabilize the training process. Then we deploy the trained model to a real robot to perform 3D obstacle avoidance in its navigation. We evaluate the proposed approach both in the simulated environment and on a robot in the real world. The experimental results show that the approach is efficient and easy to be deployed, and it performs well for 3D obstacle avoidance with a narrow observation angle, which outperforms other existing DRL-based models by 15.5% on success rate.
Robot Navigation with Map-Based Deep Reinforcement Learning
Feb 11, 2020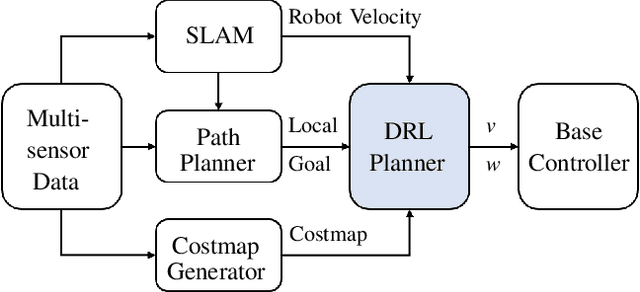
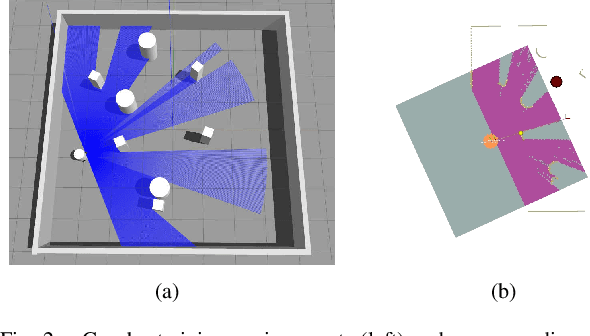
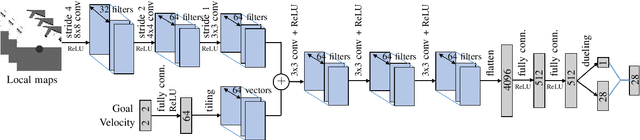
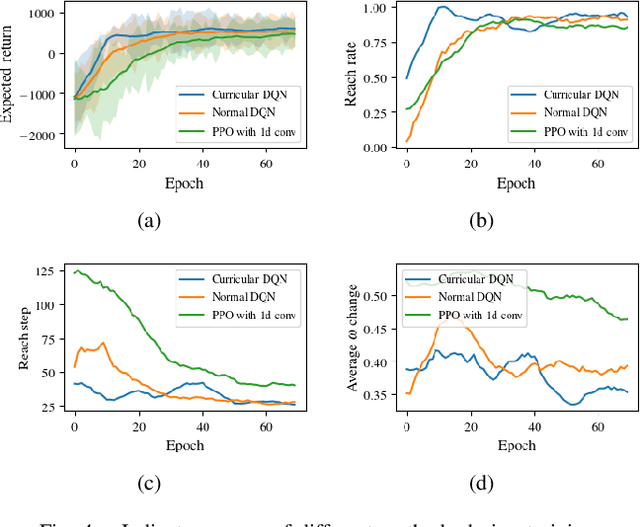
This paper proposes an end-to-end deep reinforcement learning approach for mobile robot navigation with dynamic obstacles avoidance. Using experience collected in a simulation environment, a convolutional neural network (CNN) is trained to predict proper steering actions of a robot from its egocentric local occupancy maps, which accommodate various sensors and fusion algorithms. The trained neural network is then transferred and executed on a real-world mobile robot to guide its local path planning. The new approach is evaluated both qualitatively and quantitatively in simulation and real-world robot experiments. The results show that the map-based end-to-end navigation model is easy to be deployed to a robotic platform, robust to sensor noise and outperforms other existing DRL-based models in many indicators.