 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Reinforcement Learning for Localizability-Enhanced Navigation in Dynamic Human Environments
Mar 22, 2023Reliable localization is crucial for autonomous robots to navigate efficiently and safely. Some navigation methods can plan paths with high localizability (which describes the capability of acquiring reliable localization). By following these paths, the robot can access the sensor streams that facilitate more accurate location estimation results by the localization algorithms. However, most of these methods require prior knowledge and struggle to adapt to unseen scenarios or dynamic changes. To overcome these limitations, we propose a novel approach for localizability-enhanced navigation via deep reinforcement learning in dynamic human environments. Our proposed planner automatically extracts geometric features from 2D laser data that are helpful for localization. The planner learns to assign different importance to the geometric features and encourages the robot to navigate through areas that are helpful for laser localization. To facilitate the learning of the planner, we suggest two techniques: (1) an augmented state representation that considers the dynamic changes and the confidence of the localization results, which provides more information and allows the robot to make better decisions, (2) a reward metric that is capable to offer both sparse and dense feedback on behaviors that affect localization accuracy. Our method exhibits significant improvements in lost rate and arrival rate when tested in previously unseen environments.
Learning to Socially Navigate in Pedestrian-rich Environments with Interaction Capacity
Mar 30, 2022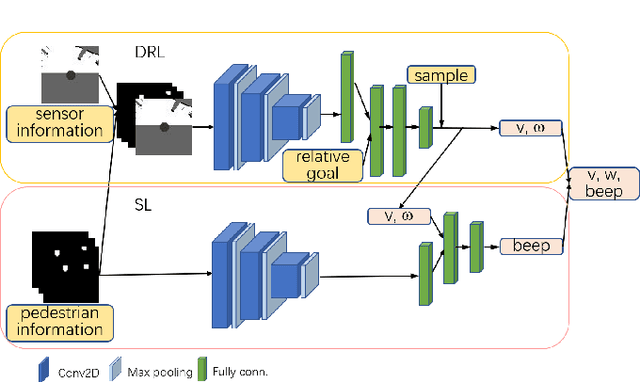
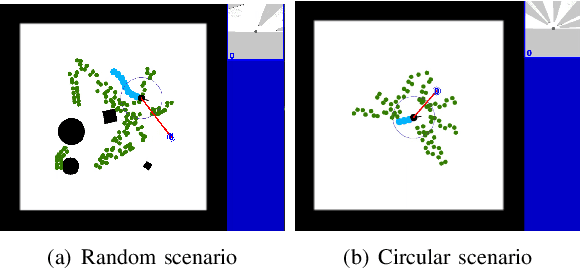
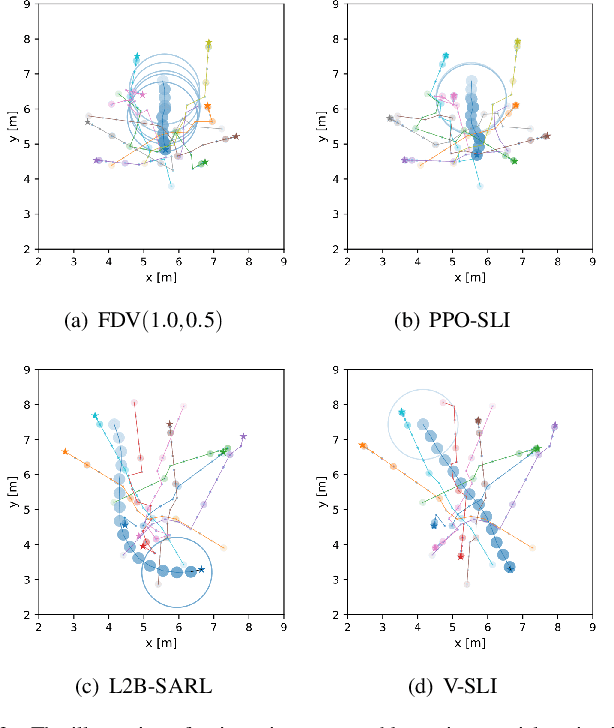
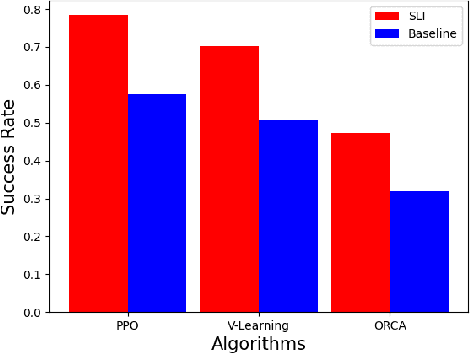
Existing navigation policies for autonomous robots tend to focus on collision avoidance while ignoring human-robot interactions in social life. For instance, robots can pass along the corridor safer and easier if pedestrians notice them. Sounds have been considered as an efficient way to attract the attention of pedestrians, which can alleviate the freezing robot problem. In this work, we present a new deep reinforcement learning (DRL) based social navigation approach for autonomous robots to move in pedestrian-rich environments with interaction capacity. Most existing DRL based methods intend to train a general policy that outputs both navigation actions, i.e., expected robot's linear and angular velocities, and interaction actions, i.e., the beep action, in the context of reinforcement learning. Different from these methods, we intend to train the policy via both supervised learning and reinforcement learning. In specific, we first train an interaction policy in the context of supervised learning, which provides a better understanding of the social situation, then we use this interaction policy to train the navigation policy via multiple reinforcement learning algorithms. We evaluate our approach in various simulation environments and compare it to other methods. The experimental results show that our approach outperforms others in terms of the success rate. We also deploy the trained policy on a real-world robot, which shows a nice performance in crowded environments.