 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMSGField: A Unified Scene Representation Integrating Motion, Semantics, and Geometry for Robotic Manipulation
Oct 21, 2024Combining accurate geometry with rich semantics has been proven to be highly effective for language-guided robotic manipulation. Existing methods for dynamic scenes either fail to update in real-time or rely on additional depth sensors for simple scene editing, limiting their applicability in real-world. In this paper, we introduce MSGField, a representation that uses a collection of 2D Gaussians for high-quality reconstruction, further enhanced with attributes to encode semantic and motion information. Specially, we represent the motion field compactly by decomposing each primitive's motion into a combination of a limited set of motion bases. Leveraging the differentiable real-time rendering of Gaussian splatting, we can quickly optimize object motion, even for complex non-rigid motions, with image supervision from only two camera views. Additionally, we designed a pipeline that utilizes object priors to efficiently obtain well-defined semantics. In our challenging dataset, which includes flexible and extremely small objects, our method achieve a success rate of 79.2% in static and 63.3% in dynamic environments for language-guided manipulation. For specified object grasping, we achieve a success rate of 90%, on par with point cloud-based methods. Code and dataset will be released at:https://shengyu724.github.io/MSGField.github.io.
PathRL: An End-to-End Path Generation Method for Collision Avoidance via Deep Reinforcement Learning
Oct 20, 2023Robot navigation using deep reinforcement learning (DRL) has shown great potential in improving the performance of mobile robots. Nevertheless, most existing DRL-based navigation methods primarily focus on training a policy that directly commands the robot with low-level controls, like linear and angular velocities, which leads to unstable speeds and unsmooth trajectories of the robot during the long-term execution. An alternative method is to train a DRL policy that outputs the navigation path directly. However, two roadblocks arise for training a DRL policy that outputs paths: (1) The action space for potential paths often involves higher dimensions comparing to low-level commands, which increases the difficulties of training; (2) It takes multiple time steps to track a path instead of a single time step, which requires the path to predicate the interactions of the robot w.r.t. the dynamic environment in multiple time steps. This, in turn, amplifies the challenges associated with training. In response to these challenges, we propose PathRL, a novel DRL method that trains the policy to generate the navigation path for the robot. Specifically, we employ specific action space discretization techniques and tailored state space representation methods to address the associated challenges. In our experiments, PathRL achieves better success rates and reduces angular rotation variability compared to other DRL navigation methods, facilitating stable and smooth robot movement. We demonstrate the competitive edge of PathRL in both real-world scenarios and multiple challenging simulation environments.
Deep Reinforcement Learning for Localizability-Enhanced Navigation in Dynamic Human Environments
Mar 22, 2023Reliable localization is crucial for autonomous robots to navigate efficiently and safely. Some navigation methods can plan paths with high localizability (which describes the capability of acquiring reliable localization). By following these paths, the robot can access the sensor streams that facilitate more accurate location estimation results by the localization algorithms. However, most of these methods require prior knowledge and struggle to adapt to unseen scenarios or dynamic changes. To overcome these limitations, we propose a novel approach for localizability-enhanced navigation via deep reinforcement learning in dynamic human environments. Our proposed planner automatically extracts geometric features from 2D laser data that are helpful for localization. The planner learns to assign different importance to the geometric features and encourages the robot to navigate through areas that are helpful for laser localization. To facilitate the learning of the planner, we suggest two techniques: (1) an augmented state representation that considers the dynamic changes and the confidence of the localization results, which provides more information and allows the robot to make better decisions, (2) a reward metric that is capable to offer both sparse and dense feedback on behaviors that affect localization accuracy. Our method exhibits significant improvements in lost rate and arrival rate when tested in previously unseen environments.
Learning to Socially Navigate in Pedestrian-rich Environments with Interaction Capacity
Mar 30, 2022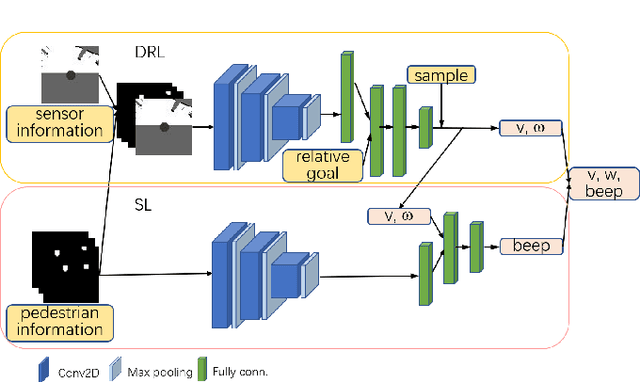
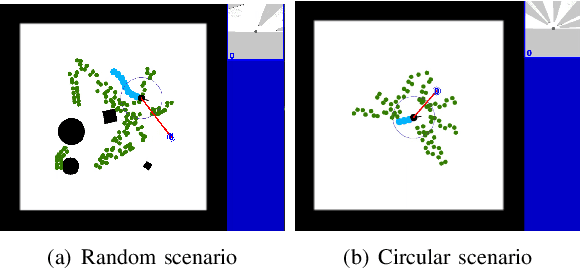
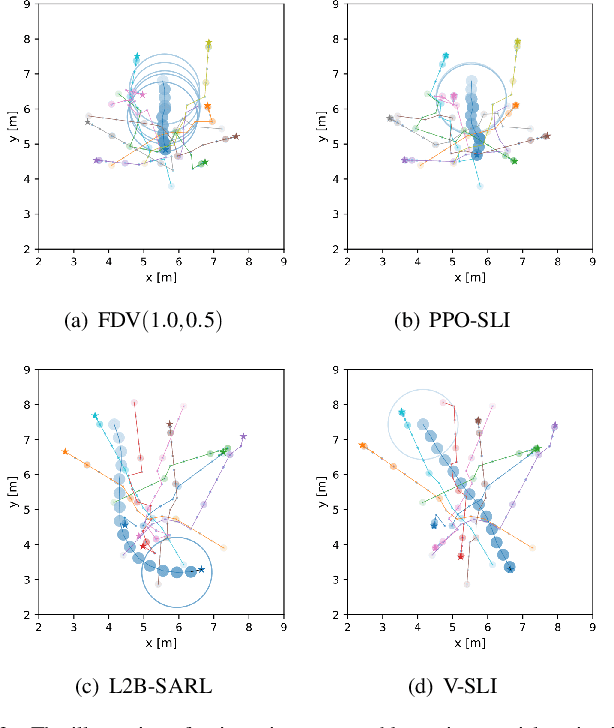
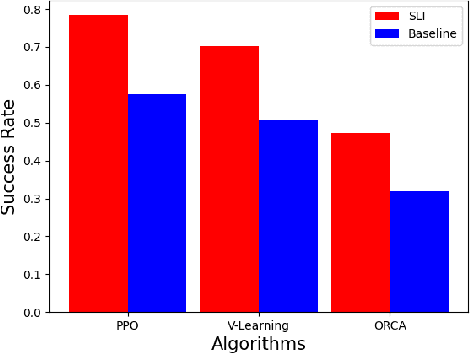
Existing navigation policies for autonomous robots tend to focus on collision avoidance while ignoring human-robot interactions in social life. For instance, robots can pass along the corridor safer and easier if pedestrians notice them. Sounds have been considered as an efficient way to attract the attention of pedestrians, which can alleviate the freezing robot problem. In this work, we present a new deep reinforcement learning (DRL) based social navigation approach for autonomous robots to move in pedestrian-rich environments with interaction capacity. Most existing DRL based methods intend to train a general policy that outputs both navigation actions, i.e., expected robot's linear and angular velocities, and interaction actions, i.e., the beep action, in the context of reinforcement learning. Different from these methods, we intend to train the policy via both supervised learning and reinforcement learning. In specific, we first train an interaction policy in the context of supervised learning, which provides a better understanding of the social situation, then we use this interaction policy to train the navigation policy via multiple reinforcement learning algorithms. We evaluate our approach in various simulation environments and compare it to other methods. The experimental results show that our approach outperforms others in terms of the success rate. We also deploy the trained policy on a real-world robot, which shows a nice performance in crowded environments.
Crowd-Aware Robot Navigation for Pedestrians with Multiple Collision Avoidance Strategies via Map-based Deep Reinforcement Learning
Sep 06, 2021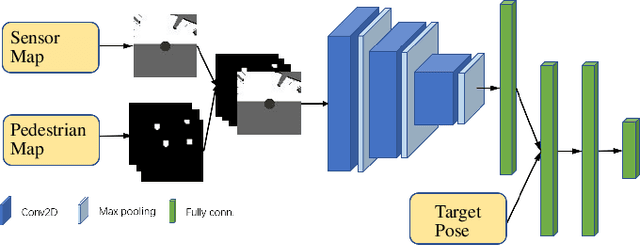
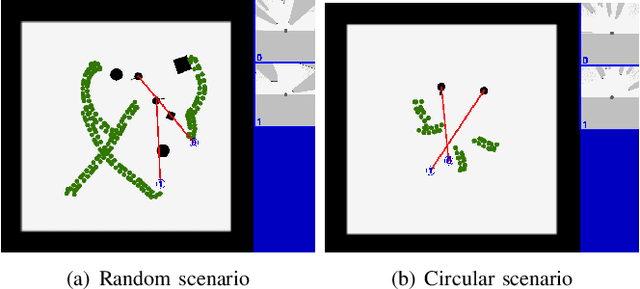
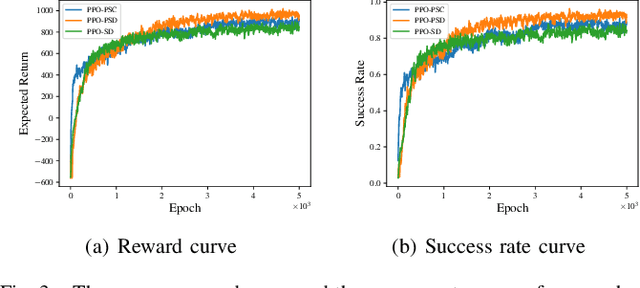
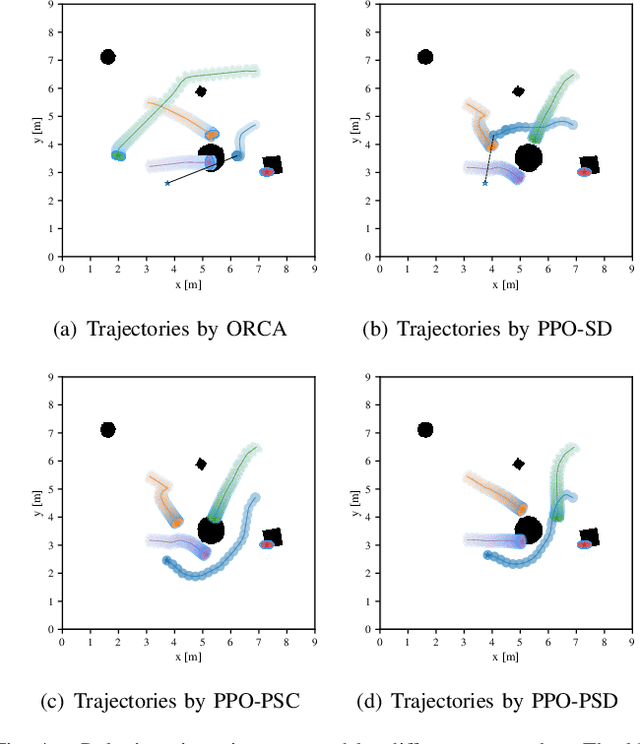
It is challenging for a mobile robot to navigate through human crowds. Existing approaches usually assume that pedestrians follow a predefined collision avoidance strategy, like social force model (SFM) or optimal reciprocal collision avoidance (ORCA). However, their performances commonly need to be further improved for practical applications, where pedestrians follow multiple different collision avoidance strategies. In this paper, we propose a map-based deep reinforcement learning approach for crowd-aware robot navigation with various pedestrians. We use the sensor map to represent the environmental information around the robot, including its shape and observable appearances of obstacles. We also introduce the pedestrian map that specifies the movements of pedestrians around the robot. By applying both maps as inputs of the neural network, we show that a navigation policy can be trained to better interact with pedestrians following different collision avoidance strategies. We evaluate our approach under multiple scenarios both in the simulator and on an actual robot. The results show that our approach allows the robot to successfully interact with various pedestrians and outperforms compared methods in terms of the success rate.