 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamical Modeling and Control of Soft Robots with Non-constant Curvature Deformation
Mar 19, 2022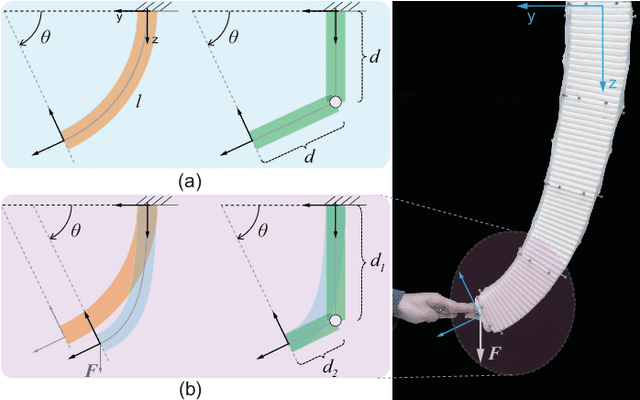
The Piecewise Constant Curvature (PCC) model is the most widely used soft robotic modeling and control. However, the PCC fails to accurately describe the deformation of the soft robots when executing dynamic tasks or interacting with the environment. This paper presents a simple threedimensional (3D) modeling method for a multi-segment soft robotic manipulator with non-constant curvature deformation. We devise kinematic and dynamical models for soft manipulators by modeling each segment of the manipulator as two stretchable links connected by a universal joint. Based on that, we present two controllers for dynamic trajectory tracking in confguration space and pose control in task space, respectively. Model accuracy is demonstrated with simulations and experimental data. The controllers are implemented on a four-segment soft robotic manipulator and validated in dynamic motions and pose control with unknown loads. The experimental results show that the dynamic controller enables a stable reference trajectory tracking at speeds up to 7m/s.
Task planning and explanation with virtual actions
Jan 10, 2022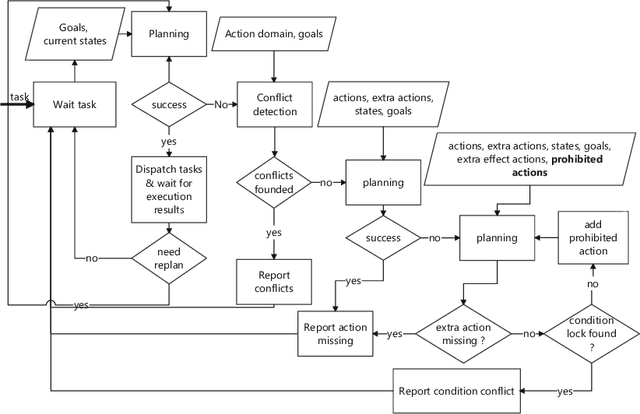
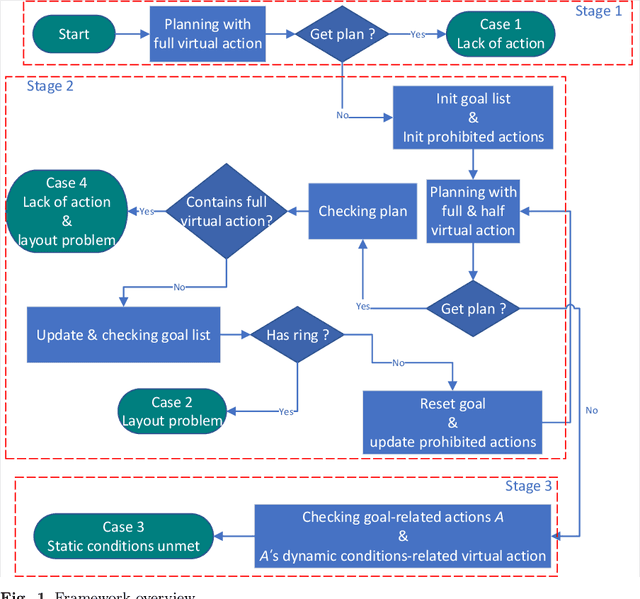

One of the challenges of task planning is to find out what causes the planning failure and how to handle the failure intelligently. This paper shows how to achieve this. The idea is inspired by the connected graph: each verticle represents a set of compatible \textit{states}, and each edge represents an \textit{action}. For any given initial states and goals, we construct virtual actions to ensure that we always get a plan via task planning. This paper shows how to introduce virtual action to extend action models to make the graph to be connected: i) explicitly defines static predicate (type, permanent properties, etc) or dynamic predicate (state); ii) constructs a full virtual action or a semi-virtual action for each state; iii) finds the cause of the planning failure through a progressive planning approach. The implementation was evaluated in three typical scenarios.
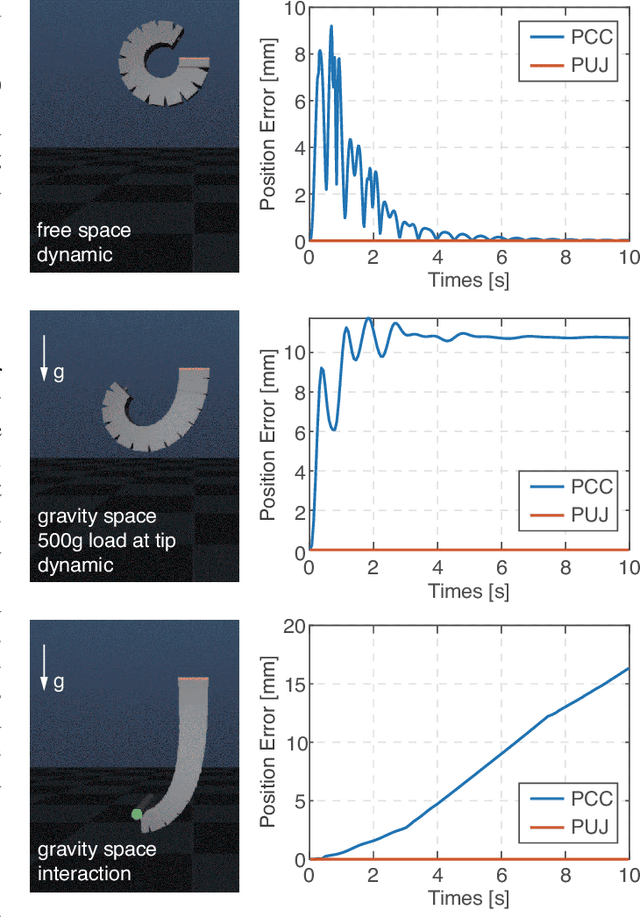
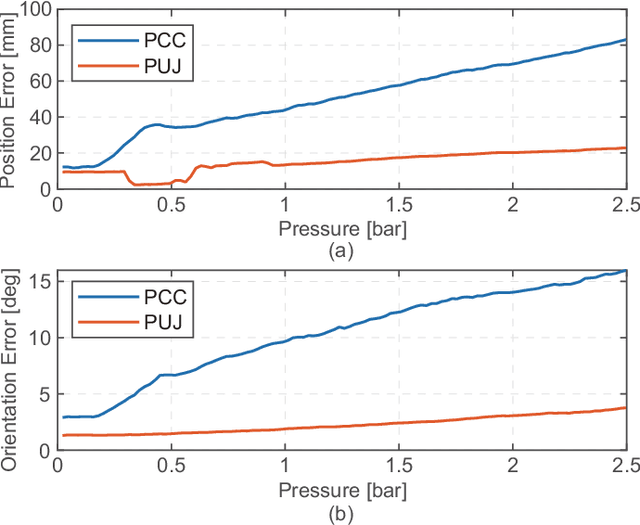
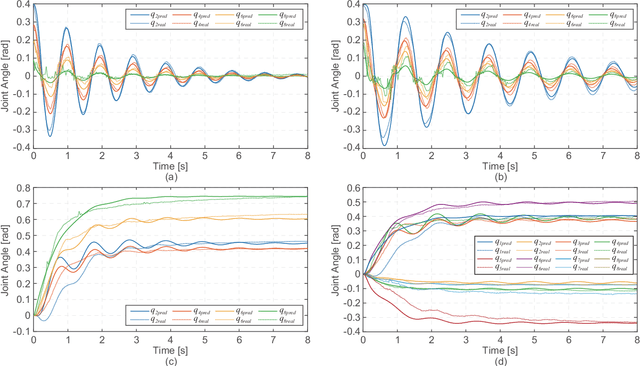
Control of a Soft Robotic Arm Using a Piecewise Universal Joint Model
Jan 05, 2022
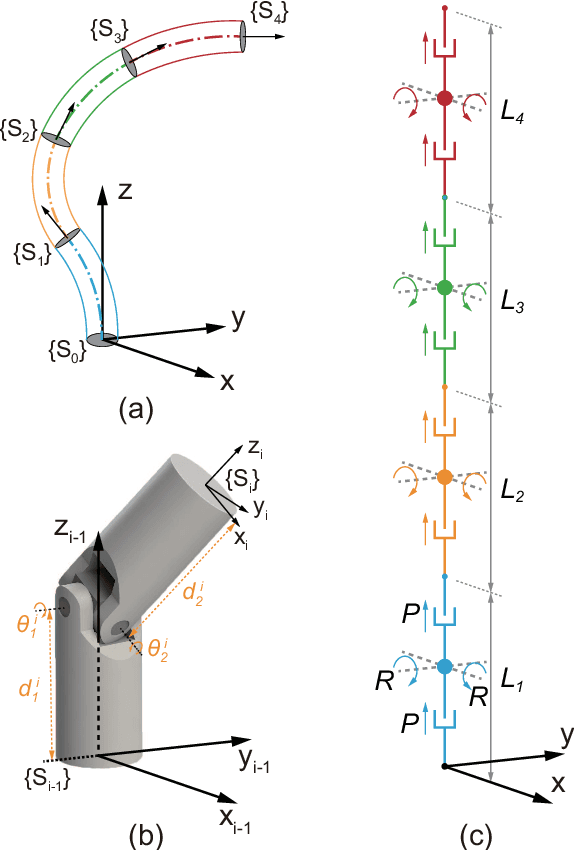


The 'infinite' passive degrees of freedom of soft robotic arms render their control especially challenging. In this paper, we leverage a previously developed model, which drawing equivalence of the soft arm to a series of universal joints, to design two closed-loop controllers: a configuration space controller for trajectory tracking and a task space controller for position control of the end effector. Extensive experiments and simulations on a four-segment soft arm attest to substantial improvement in terms of: a) superior tracking accuracy of the configuration space controller and b) reduced settling time and steady-state error of the task space controller. The task space controller is also verified to be effective in the presence of interactions between the soft arm and the environment.
A Q-learning Control Method for a Soft Robotic Arm Utilizing Training Data from a Rough Simulator
Sep 13, 2021
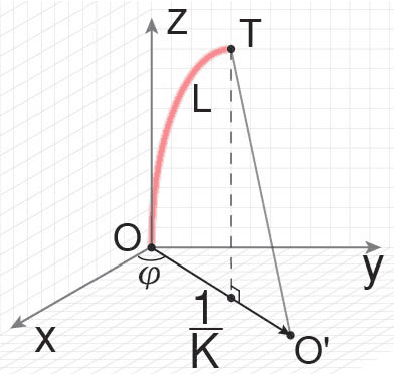
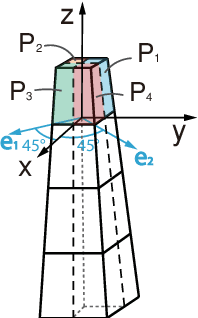
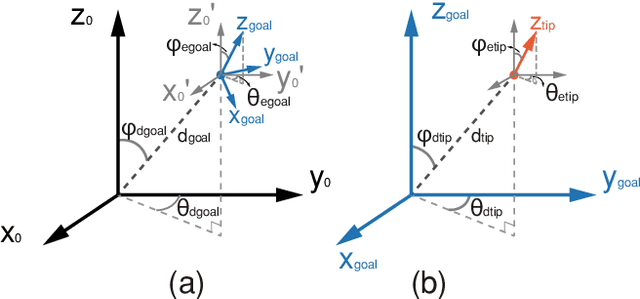
It is challenging to control a soft robot, where reinforcement learning methods have been applied with promising results. However, due to the poor sample efficiency, reinforcement learning methods require a large collection of training data, which limits their applications. In this paper, we propose a Q-learning controller for a physical soft robot, in which pre-trained models using data from a rough simulator are applied to improve the performance of the controller. We implement the method on our soft robot, i.e., Honeycomb Pneumatic Network (HPN) arm. The experiments show that the usage of pre-trained models can not only reduce the amount of the real-world training data, but also greatly improve its accuracy and convergence rate.
Crowd-Aware Robot Navigation for Pedestrians with Multiple Collision Avoidance Strategies via Map-based Deep Reinforcement Learning
Sep 06, 2021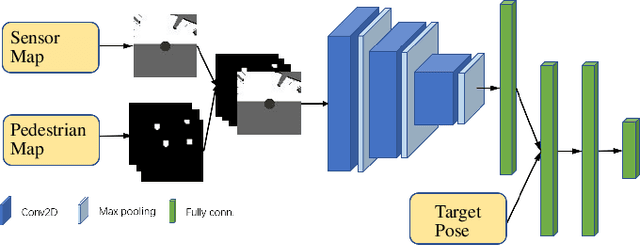
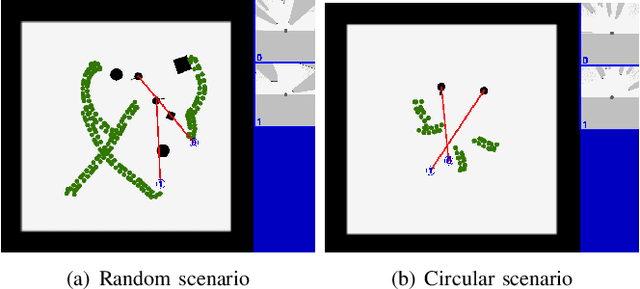
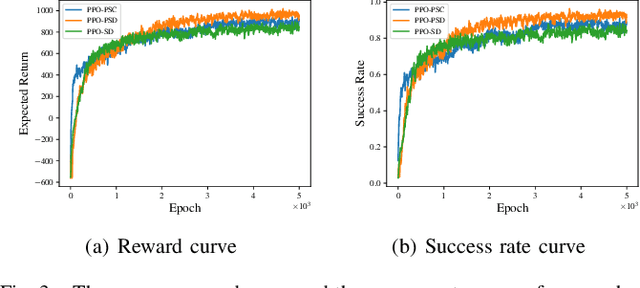
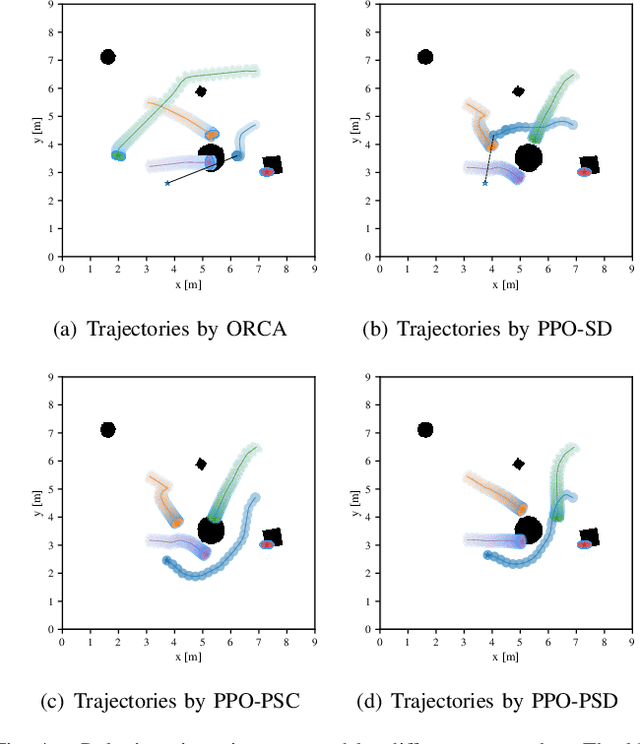
It is challenging for a mobile robot to navigate through human crowds. Existing approaches usually assume that pedestrians follow a predefined collision avoidance strategy, like social force model (SFM) or optimal reciprocal collision avoidance (ORCA). However, their performances commonly need to be further improved for practical applications, where pedestrians follow multiple different collision avoidance strategies. In this paper, we propose a map-based deep reinforcement learning approach for crowd-aware robot navigation with various pedestrians. We use the sensor map to represent the environmental information around the robot, including its shape and observable appearances of obstacles. We also introduce the pedestrian map that specifies the movements of pedestrians around the robot. By applying both maps as inputs of the neural network, we show that a navigation policy can be trained to better interact with pedestrians following different collision avoidance strategies. We evaluate our approach under multiple scenarios both in the simulator and on an actual robot. The results show that our approach allows the robot to successfully interact with various pedestrians and outperforms compared methods in terms of the success rate.
NEARL: Non-Explicit Action Reinforcement Learning for Robotic Control
Nov 02, 2020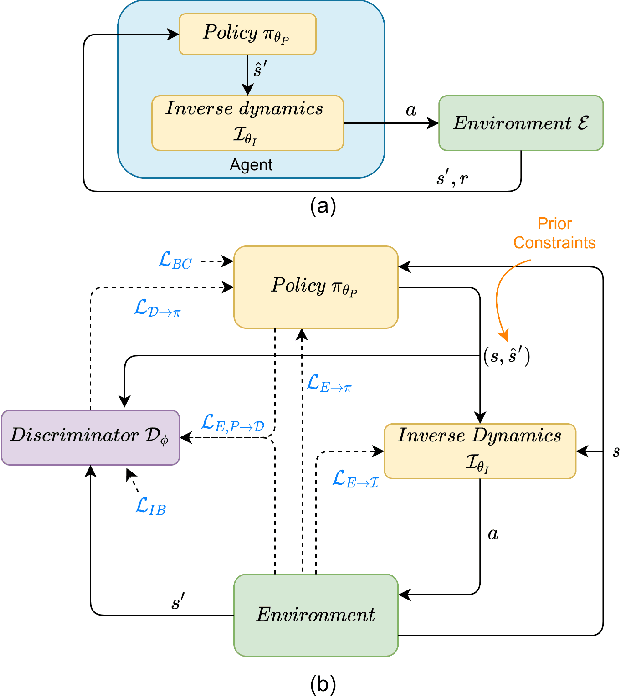
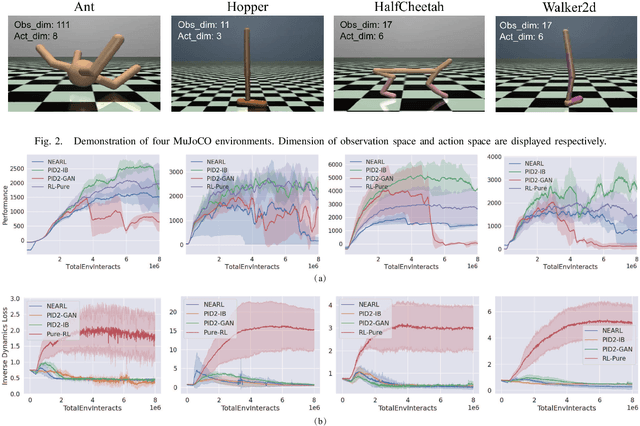
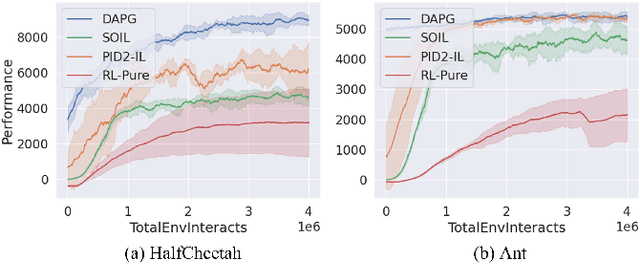
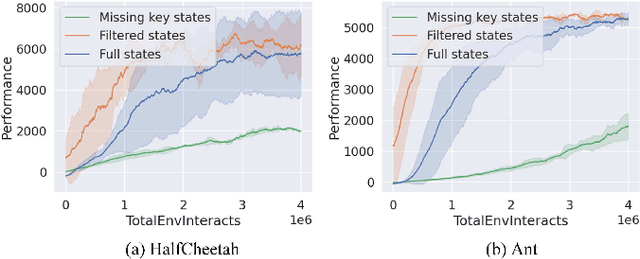
Traditionally, reinforcement learning methods predict the next action based on the current state. However, in many situations, directly applying actions to control systems or robots is dangerous and may lead to unexpected behaviors because action is rather low-level. In this paper, we propose a novel hierarchical reinforcement learning framework without explicit action. Our meta policy tries to manipulate the next optimal state and actual action is produced by the inverse dynamics model. To stabilize the training process, we integrate adversarial learning and information bottleneck into our framework. Under our framework, widely available state-only demonstrations can be exploited effectively for imitation learning. Also, prior knowledge and constraints can be applied to meta policy. We test our algorithm in simulation tasks and its combination with imitation learning. The experimental results show the reliability and robustness of our algorithms.
Semantic Task Planning for Service Robots in Open World
Nov 01, 2020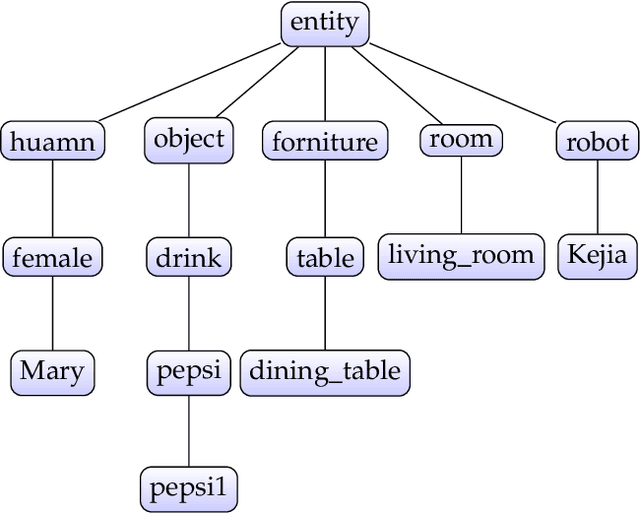
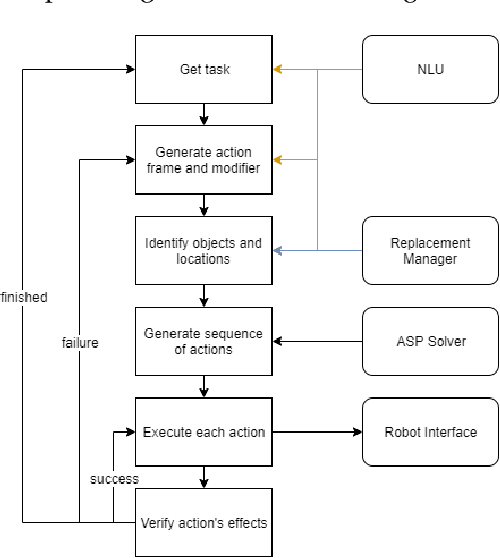

In this paper, we present a planning system based on semantic reasoning for a general-purpose service robot, which is aimed at behaving more intelligently in domains that contain incomplete information, under-specified goals, and dynamic changes. First, Two kinds of data are generated by Natural Language Processing module from the speech: (i) action frames and their relationships; (ii) the modifier used to indicate some property or characteristic of a variable in the action frame. Next, the goals of the task are generated from these action frames and modifiers. These goals are represented as AI symbols, combining world state and domain knowledge, which are used to generate plans by an Answer Set Programming solver. Finally, the actions of the plan are executed one by one, and continuous sensing grounds useful information, which make the robot to use contingent knowledge to adapt to dynamic changes and faults. For each action in the plan, the planner gets its preconditions and effects from domain knowledge, so during the execution of the task, the environmental changes, especially those conflict with the actions, not only the action being performed, but also the subsequent actions, can be detected and handled as early as possible. A series of case studies are used to evaluate the system and verify its ability to acquire knowledge through dialogue with users, solve problems with the acquired causal knowledge, and plan for complex tasks autonomously in the open world.
Design, Control, and Applications of a Soft Robotic Arm
Jul 08, 2020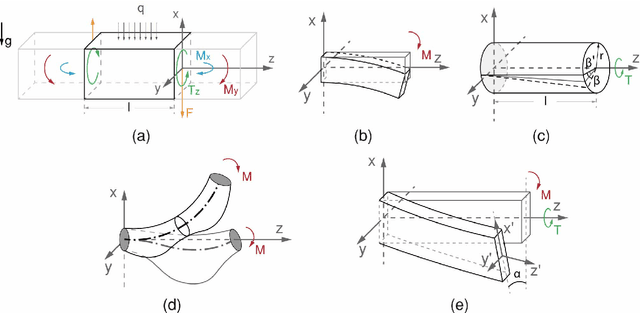
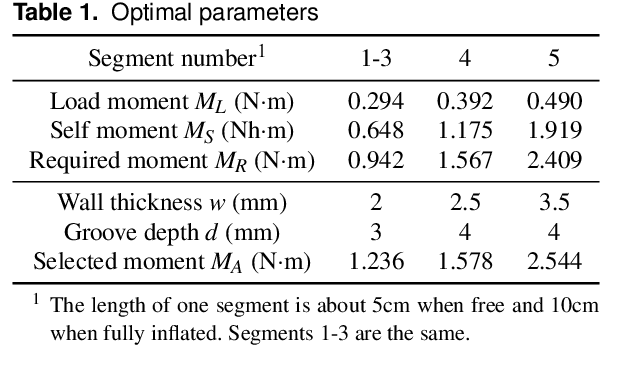
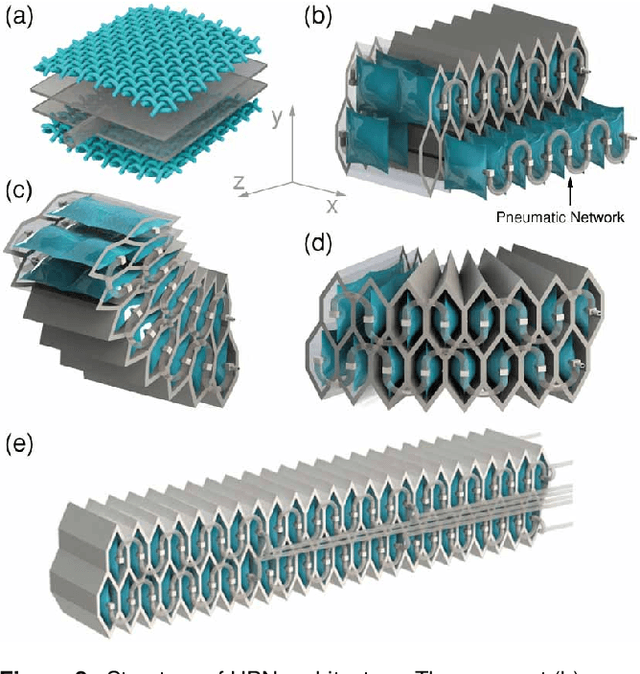
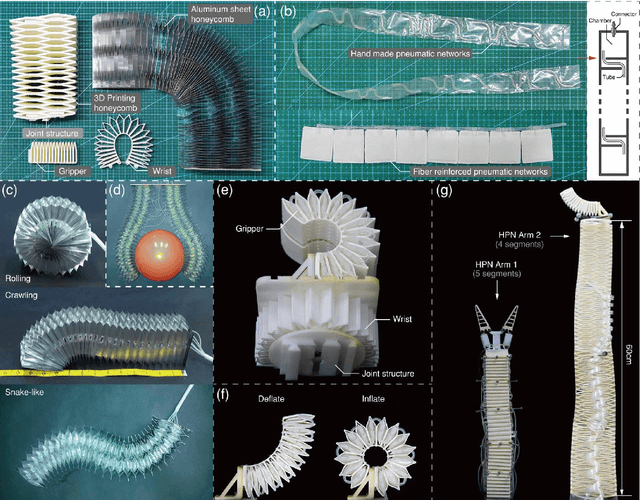
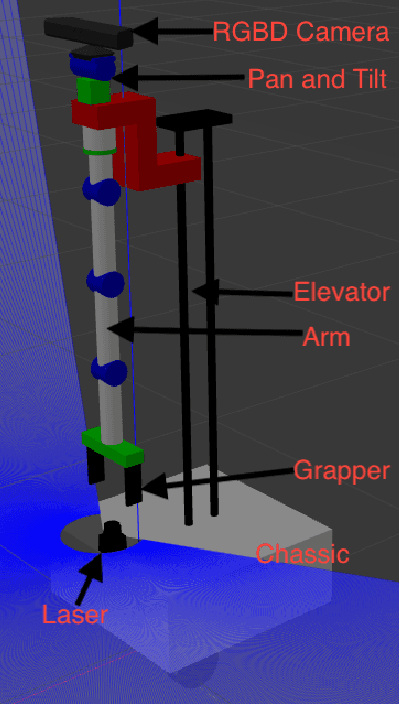
This paper presents the design, control, and applications of a multi-segment soft robotic arm. In order to design a soft arm with large load capacity, several design principles are proposed by analyzing two kinds of buckling issues, under which we present a novel structure named Honeycomb Pneumatic Networks (HPN). Parameter optimization method, based on finite element method (FEM), is proposed to optimize HPN Arm design parameters. Through a quick fabrication process, several prototypes with different performance are made, one of which can achieve the transverse load capacity of 3 kg under 3 bar pressure. Next, considering different internal and external conditions, we develop three controllers according to different model precision. Specifically, based on accurate model, an open-loop controller is realized by combining piece-wise constant curvature (PCC) modeling method and machine learning method. Based on inaccurate model, a feedback controller, using estimated Jacobian, is realized in 3D space. A model-free controller, using reinforcement learning to learn a control policy rather than a model, is realized in 2D plane, with minimal training data. Then, these three control methods are compared on a same experiment platform to explore the applicability of different methods under different conditions. Lastly, we figure out that soft arm can greatly simplify the perception, planning, and control of interaction tasks through its compliance, which is its main advantage over the rigid arm. Through plentiful experiments in three interaction application scenarios, human-robot interaction, free space interaction task, and confined space interaction task, we demonstrate the potential application prospect of the soft arm.
Learning and Reasoning for Robot Dialog and Navigation Tasks
May 20, 2020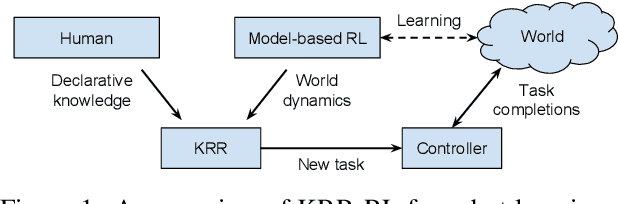
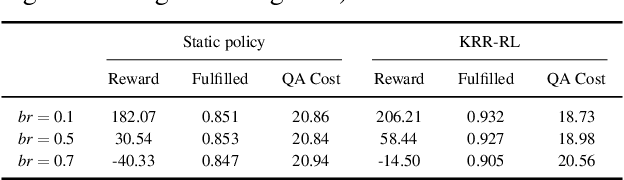

Reinforcement learning and probabilistic reasoning algorithms aim at learning from interaction experiences and reasoning with probabilistic contextual knowledge respectively. In this research, we develop algorithms for robot task completions, while looking into the complementary strengths of reinforcement learning and probabilistic reasoning techniques. The robots learn from trial-and-error experiences to augment their declarative knowledge base, and the augmented knowledge can be used for speeding up the learning process in potentially different tasks. We have implemented and evaluated the developed algorithms using mobile robots conducting dialog and navigation tasks. From the results, we see that our robot's performance can be improved by both reasoning with human knowledge and learning from task-completion experience. More interestingly, the robot was able to learn from navigation tasks to improve its dialog strategies.
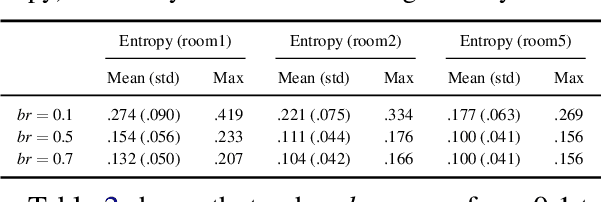
Adaptive Dialog Policy Learning with Hindsight and User Modeling
May 07, 2020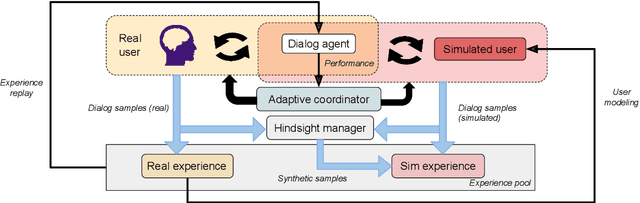

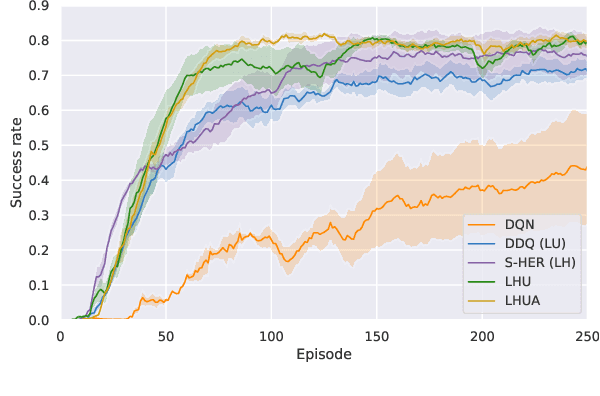
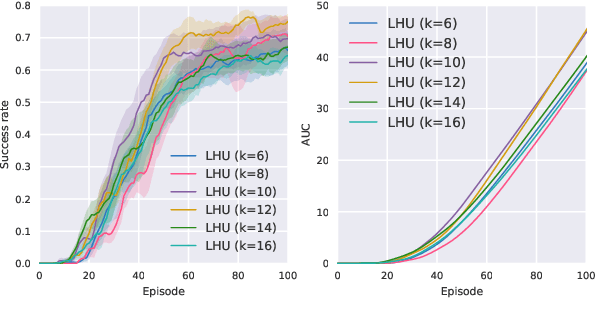
Reinforcement learning methods have been used to compute dialog policies from language-based interaction experiences. Efficiency is of particular importance in dialog policy learning, because of the considerable cost of interacting with people, and the very poor user experience from low-quality conversations. Aiming at improving the efficiency of dialog policy learning, we develop algorithm LHUA (Learning with Hindsight, User modeling, and Adaptation) that, for the first time, enables dialog agents to adaptively learn with hindsight from both simulated and real users. Simulation and hindsight provide the dialog agent with more experience and more (positive) reinforcements respectively. Experimental results suggest that, in success rate and policy quality, LHUA outperforms competitive baselines from the literature, including its no-simulation, no-adaptation, and no-hindsight counterparts.