 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFlow Matching Policy with Entropy Regularization
Mar 19, 2026Diffusion-based policies have gained significant popularity in Reinforcement Learning (RL) due to their ability to represent complex, non-Gaussian distributions. Stochastic Differential Equation (SDE)-based diffusion policies often rely on indirect entropy control due to the intractability of the exact entropy, while also suffering from computationally prohibitive policy gradients through the iterative denoising chain. To overcome these issues, we propose Flow Matching Policy with Entropy Regularization (FMER), an Ordinary Differential Equation (ODE)-based online RL framework. FMER parameterizes the policy via flow matching and samples actions along a straight probability path, motivated by optimal transport. FMER leverages the model's generative nature to construct an advantage-weighted target velocity field from a candidate set, steering policy updates toward high-value regions. By deriving a tractable entropy objective, FMER enables principled maximum-entropy optimization for enhanced exploration. Experiments on sparse multi-goal FrankaKitchen benchmarks demonstrate that FMER outperforms state-of-the-art methods, while remaining competitive on standard MuJoco benchmarks. Moreover, FMER reduces training time by 7x compared to heavy diffusion baselines (QVPO) and 10-15% relative to efficient variants.
SmartMeterFM: Unifying Smart Meter Data Generative Tasks Using Flow Matching Models
Jan 29, 2026Smart meter data is the foundation for planning and operating the distribution network. Unfortunately, such data are not always available due to privacy regulations. Meanwhile, the collected data may be corrupted due to sensor or transmission failure, or it may not have sufficient resolution for downstream tasks. A wide range of generative tasks is formulated to address these issues, including synthetic data generation, missing data imputation, and super-resolution. Despite the success of machine learning models on these tasks, dedicated models need to be designed and trained for each task, leading to redundancy and inefficiency. In this paper, by recognizing the powerful modeling capability of flow matching models, we propose a new approach to unify diverse smart meter data generative tasks with a single model trained for conditional generation. The proposed flow matching models are trained to generate challenging, high-dimensional time series data, specifically monthly smart meter data at a 15 min resolution. By viewing different generative tasks as distinct forms of partial data observations and injecting them into the generation process, we unify tasks such as imputation and super-resolution with a single model, eliminating the need for re-training. The data generated by our model not only are consistent with the given observations but also remain realistic, showing better performance against interpolation and other machine learning based baselines dedicated to the tasks.
EnergyDiff: Universal Time-Series Energy Data Generation using Diffusion Models
Jul 18, 2024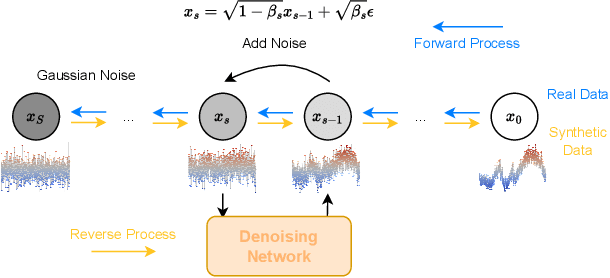
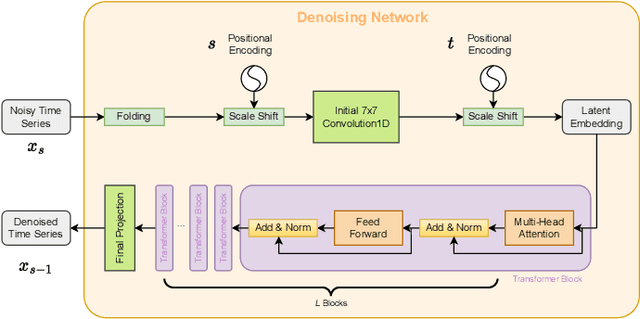
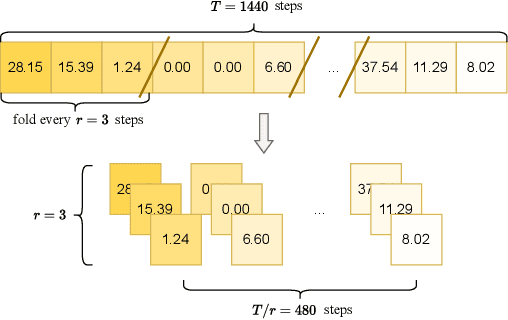

High-resolution time series data are crucial for operation and planning in energy systems such as electrical power systems and heating systems. However, due to data collection costs and privacy concerns, such data is often unavailable or insufficient for downstream tasks. Data synthesis is a potential solution for this data scarcity. With the recent development of generative AI, we propose EnergyDiff, a universal data generation framework for energy time series data. EnergyDiff builds on state-of-the-art denoising diffusion probabilistic models, utilizing a proposed denoising network dedicated to high-resolution time series data and introducing a novel Marginal Calibration technique. Our extensive experimental results demonstrate that EnergyDiff achieves significant improvement in capturing temporal dependencies and marginal distributions compared to baselines, particularly at the 1-minute resolution. Additionally, EnergyDiff consistently generates high-quality time series data across diverse energy domains, time resolutions, and at both customer and transformer levels with reduced computational need.
Computational Models to Study Language Processing in the Human Brain: A Survey
Mar 20, 2024



Despite differing from the human language processing mechanism in implementation and algorithms, current language models demonstrate remarkable human-like or surpassing language capabilities. Should computational language models be employed in studying the brain, and if so, when and how? To delve into this topic, this paper reviews efforts in using computational models for brain research, highlighting emerging trends. To ensure a fair comparison, the paper evaluates various computational models using consistent metrics on the same dataset. Our analysis reveals that no single model outperforms others on all datasets, underscoring the need for rich testing datasets and rigid experimental control to draw robust conclusions in studies involving computational models.
PowerFlowNet: Leveraging Message Passing GNNs for Improved Power Flow Approximation
Nov 06, 2023



Accurate and efficient power flow (PF) analysis is crucial in modern electrical networks' efficient operation and planning. Therefore, there is a need for scalable algorithms capable of handling large-scale power networks that can provide accurate and fast solutions. Graph Neural Networks (GNNs) have emerged as a promising approach for enhancing the speed of PF approximations by leveraging their ability to capture distinctive features from the underlying power network graph. In this study, we introduce PowerFlowNet, a novel GNN architecture for PF approximation that showcases similar performance with the traditional Newton-Raphson method but achieves it 4 times faster in the simple IEEE 14-bus system and 145 times faster in the realistic case of the French high voltage network (6470rte). Meanwhile, it significantly outperforms other traditional approximation methods, such as the DC relaxation method, in terms of performance and execution time; therefore, making PowerFlowNet a highly promising solution for real-world PF analysis. Furthermore, we verify the efficacy of our approach by conducting an in-depth experimental evaluation, thoroughly examining the performance, scalability, interpretability, and architectural dependability of PowerFlowNet. The evaluation provides insights into the behavior and potential applications of GNNs in power system analysis.
Language Cognition and Language Computation -- Human and Machine Language Understanding
Jan 12, 2023Language understanding is a key scientific issue in the fields of cognitive and computer science. However, the two disciplines differ substantially in the specific research questions. Cognitive science focuses on analyzing the specific mechanism of the brain and investigating the brain's response to language; few studies have examined the brain's language system as a whole. By contrast, computer scientists focus on the efficiency of practical applications when choosing research questions but may ignore the most essential laws of language. Given these differences, can a combination of the disciplines offer new insights for building intelligent language models and studying language cognitive mechanisms? In the following text, we first review the research questions, history, and methods of language understanding in cognitive and computer science, focusing on the current progress and challenges. We then compare and contrast the research of language understanding in cognitive and computer sciences. Finally, we review existing work that combines insights from language cognition and language computation and offer prospects for future development trends.
NEARL: Non-Explicit Action Reinforcement Learning for Robotic Control
Nov 02, 2020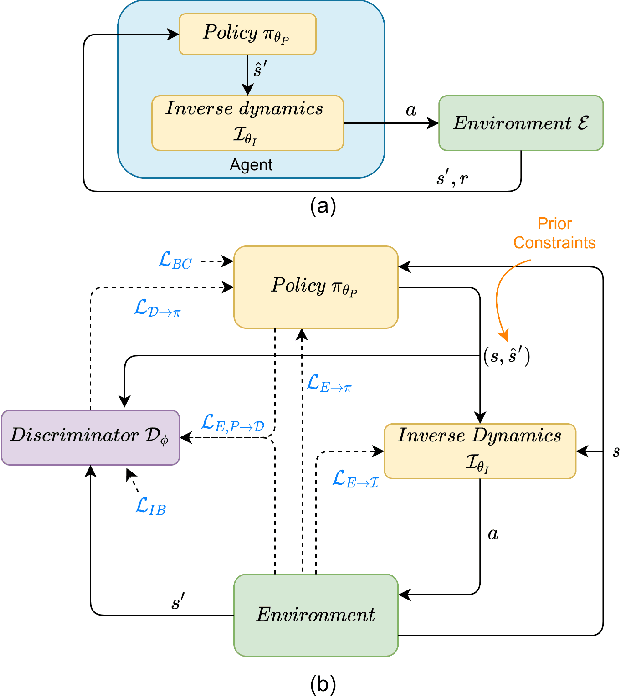
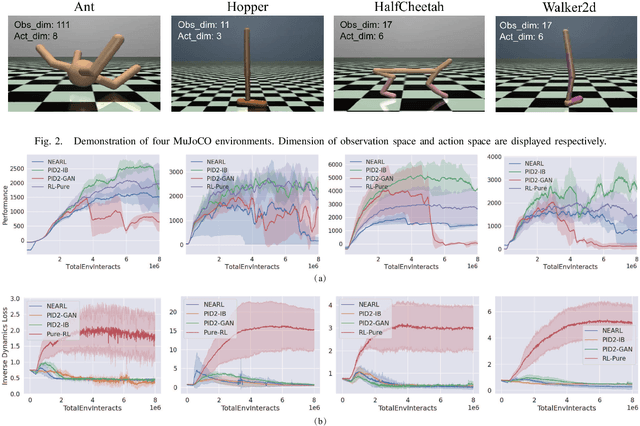
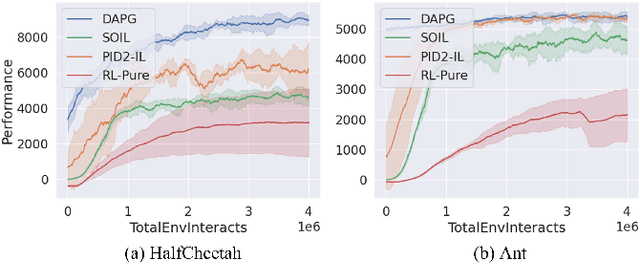
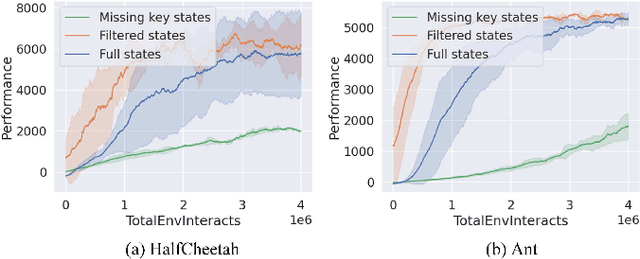
Traditionally, reinforcement learning methods predict the next action based on the current state. However, in many situations, directly applying actions to control systems or robots is dangerous and may lead to unexpected behaviors because action is rather low-level. In this paper, we propose a novel hierarchical reinforcement learning framework without explicit action. Our meta policy tries to manipulate the next optimal state and actual action is produced by the inverse dynamics model. To stabilize the training process, we integrate adversarial learning and information bottleneck into our framework. Under our framework, widely available state-only demonstrations can be exploited effectively for imitation learning. Also, prior knowledge and constraints can be applied to meta policy. We test our algorithm in simulation tasks and its combination with imitation learning. The experimental results show the reliability and robustness of our algorithms.
Investigating Inner Properties of Multimodal Representation and Semantic Compositionality with Brain-based Componential Semantics
Nov 22, 2017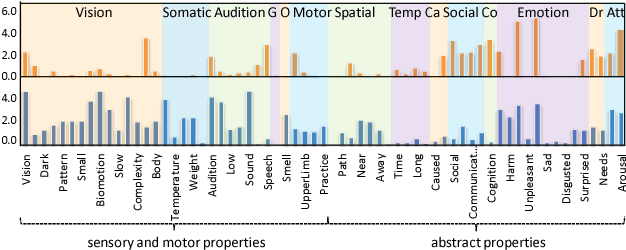


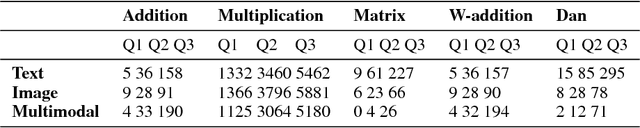
Multimodal models have been proven to outperform text-based approaches on learning semantic representations. However, it still remains unclear what properties are encoded in multimodal representations, in what aspects do they outperform the single-modality representations, and what happened in the process of semantic compositionality in different input modalities. Considering that multimodal models are originally motivated by human concept representations, we assume that correlating multimodal representations with brain-based semantics would interpret their inner properties to answer the above questions. To that end, we propose simple interpretation methods based on brain-based componential semantics. First we investigate the inner properties of multimodal representations by correlating them with corresponding brain-based property vectors. Then we map the distributed vector space to the interpretable brain-based componential space to explore the inner properties of semantic compositionality. Ultimately, the present paper sheds light on the fundamental questions of natural language understanding, such as how to represent the meaning of words and how to combine word meanings into larger units.
Functional Principal Component Analysis and Randomized Sparse Clustering Algorithm for Medical Image Analysis
Aug 01, 2014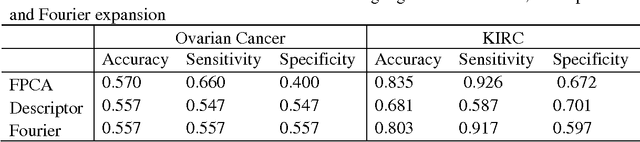

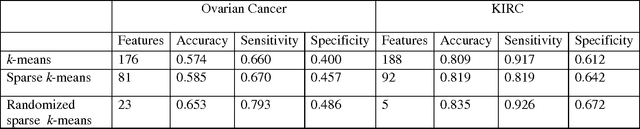

Due to advances in sensors, growing large and complex medical image data have the ability to visualize the pathological change in the cellular or even the molecular level or anatomical changes in tissues and organs. As a consequence, the medical images have the potential to enhance diagnosis of disease, prediction of clinical outcomes, characterization of disease progression, management of health care and development of treatments, but also pose great methodological and computational challenges for representation and selection of features in image cluster analysis. To address these challenges, we first extend one dimensional functional principal component analysis to the two dimensional functional principle component analyses (2DFPCA) to fully capture space variation of image signals. Image signals contain a large number of redundant and irrelevant features which provide no additional or no useful information for cluster analysis. Widely used methods for removing redundant and irrelevant features are sparse clustering algorithms using a lasso-type penalty to select the features. However, the accuracy of clustering using a lasso-type penalty depends on how to select penalty parameters and a threshold for selecting features. In practice, they are difficult to determine. Recently, randomized algorithms have received a great deal of attention in big data analysis. This paper presents a randomized algorithm for accurate feature selection in image cluster analysis. The proposed method is applied to ovarian and kidney cancer histology image data from the TCGA database. The results demonstrate that the randomized feature selection method coupled with functional principal component analysis substantially outperforms the current sparse clustering algorithms in image cluster analysis.