 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHiMemVLN: Enhancing Reliability of Open-Source Zero-Shot Vision-and-Language Navigation with Hierarchical Memory System
Mar 16, 2026LLM-based agents have demonstrated impressive zero-shot performance in vision-language navigation (VLN) tasks. However, most zero-shot methods primarily rely on closed-source LLMs as navigators, which face challenges related to high token costs and potential data leakage risks. Recent efforts have attempted to address this by using open-source LLMs combined with a spatiotemporal CoT framework, but they still fall far short compared to closed-source models. In this work, we identify a critical issue, Navigation Amnesia, through a detailed analysis of the navigation process. This issue leads to navigation failures and amplifies the gap between open-source and closed-source methods. To address this, we propose HiMemVLN, which incorporates a Hierarchical Memory System into a multimodal large model to enhance visual perception recall and long-term localization, mitigating the amnesia issue and improving the agent's navigation performance. Extensive experiments in both simulated and real-world environments demonstrate that HiMemVLN achieves nearly twice the performance of the open-source state-of-the-art method. The code is available at https://github.com/lvkailin0118/HiMemVLN.
Component-Level Lesioning of Language Models Reveals Clinically Aligned Aphasia Phenotypes
Jan 27, 2026Large language models (LLMs) increasingly exhibit human-like linguistic behaviors and internal representations that they could serve as computational simulators of language cognition. We ask whether LLMs can be systematically manipulated to reproduce language-production impairments characteristic of aphasia following focal brain lesions. Such models could provide scalable proxies for testing rehabilitation hypotheses, and offer a controlled framework for probing the functional organization of language. We introduce a clinically grounded, component-level framework that simulates aphasia by selectively perturbing functional components in LLMs, and apply it to both modular Mixture-of-Experts models and dense Transformers using a unified intervention interface. Our pipeline (i) identifies subtype-linked components for Broca's and Wernicke's aphasia, (ii) interprets these components with linguistic probing tasks, and (iii) induces graded impairments by progressively perturbing the top-k subtype-linked components, evaluating outcomes with Western Aphasia Battery (WAB) subtests summarized by Aphasia Quotient (AQ). Across architectures and lesioning strategies, subtype-targeted perturbations yield more systematic, aphasia-like regressions than size-matched random perturbations, and MoE modularity supports more localized and interpretable phenotype-to-component mappings. These findings suggest that modular LLMs, combined with clinically informed component perturbations, provide a promising platform for simulating aphasic language production and studying how distinct language functions degrade under targeted disruptions.
MIRA: Medical Time Series Foundation Model for Real-World Health Data
Jun 09, 2025


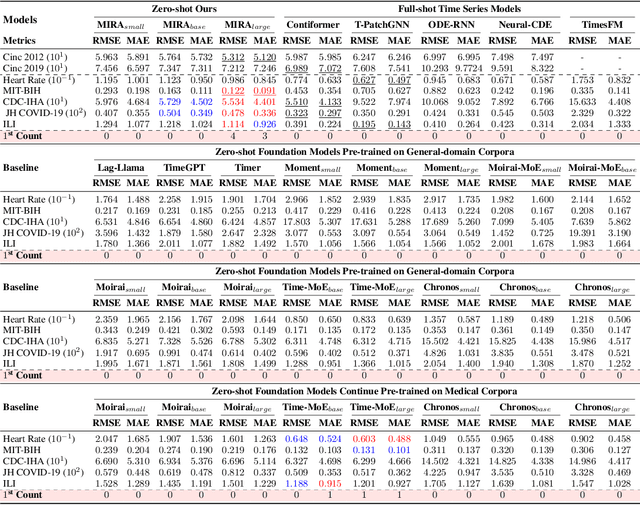
A unified foundation model for medical time series -- pretrained on open access and ethics board-approved medical corpora -- offers the potential to reduce annotation burdens, minimize model customization, and enable robust transfer across clinical institutions, modalities, and tasks, particularly in data-scarce or privacy-constrained environments. However, existing generalist time series foundation models struggle to handle medical time series data due to their inherent challenges, including irregular intervals, heterogeneous sampling rates, and frequent missing values. To address these challenges, we introduce MIRA, a unified foundation model specifically designed for medical time series forecasting. MIRA incorporates a Continuous-Time Rotary Positional Encoding that enables fine-grained modeling of variable time intervals, a frequency-specific mixture-of-experts layer that routes computation across latent frequency regimes to further promote temporal specialization, and a Continuous Dynamics Extrapolation Block based on Neural ODE that models the continuous trajectory of latent states, enabling accurate forecasting at arbitrary target timestamps. Pretrained on a large-scale and diverse medical corpus comprising over 454 billion time points collect from publicly available datasets, MIRA achieves reductions in forecasting errors by an average of 10% and 7% in out-of-distribution and in-distribution scenarios, respectively, when compared to other zero-shot and fine-tuned baselines. We also introduce a comprehensive benchmark spanning multiple downstream clinical tasks, establishing a foundation for future research in medical time series modeling.
Exploring Pose-Guided Imitation Learning for Robotic Precise Insertion
May 14, 2025Recent studies have proved that imitation learning shows strong potential in the field of robotic manipulation. However, existing methods still struggle with precision manipulation task and rely on inefficient image/point cloud observations. In this paper, we explore to introduce SE(3) object pose into imitation learning and propose the pose-guided efficient imitation learning methods for robotic precise insertion task. First, we propose a precise insertion diffusion policy which utilizes the relative SE(3) pose as the observation-action pair. The policy models the source object SE(3) pose trajectory relative to the target object. Second, we explore to introduce the RGBD data to the pose-guided diffusion policy. Specifically, we design a goal-conditioned RGBD encoder to capture the discrepancy between the current state and the goal state. In addition, a pose-guided residual gated fusion method is proposed, which takes pose features as the backbone, and the RGBD features selectively compensate for pose feature deficiencies through an adaptive gating mechanism. Our methods are evaluated on 6 robotic precise insertion tasks, demonstrating competitive performance with only 7-10 demonstrations. Experiments demonstrate that the proposed methods can successfully complete precision insertion tasks with a clearance of about 0.01 mm. Experimental results highlight its superior efficiency and generalization capability compared to existing baselines. Code will be available at https://github.com/sunhan1997/PoseInsert.
Silent Hazards of Token Reduction in Vision-Language Models: The Hidden Impact on Consistency
Mar 11, 2025


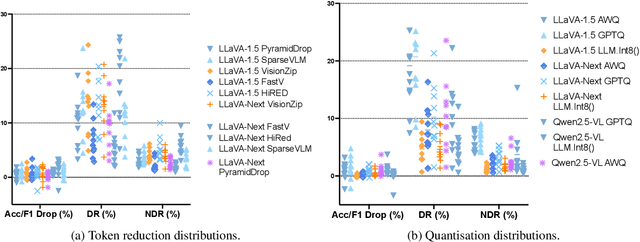
Vision language models (VLMs) have excelled in visual reasoning but often incur high computational costs. One key reason is the redundancy of visual tokens. Although recent token reduction methods claim to achieve minimal performance loss, our extensive experiments reveal that token reduction can substantially alter a model's output distribution, leading to changes in prediction patterns that standard metrics such as accuracy loss do not fully capture. Such inconsistencies are especially concerning for practical applications where system stability is critical. To investigate this phenomenon, we analyze how token reduction influences the energy distribution of a VLM's internal representations using a lower-rank approximation via Singular Value Decomposition (SVD). Our results show that changes in the Inverse Participation Ratio of the singular value spectrum are strongly correlated with the model's consistency after token reduction. Based on these insights, we propose LoFi--a training-free visual token reduction method that utilizes the leverage score from SVD for token pruning. Experimental evaluations demonstrate that LoFi not only reduces computational costs with minimal performance degradation but also significantly outperforms state-of-the-art methods in terms of output consistency.
LVPruning: An Effective yet Simple Language-Guided Vision Token Pruning Approach for Multi-modal Large Language Models
Jan 23, 2025



Multi-modal Large Language Models (MLLMs) have achieved remarkable success by integrating visual and textual modalities. However, they incur significant computational overhead due to the large number of vision tokens processed, limiting their practicality in resource-constrained environments. We introduce Language-Guided Vision Token Pruning (LVPruning) for MLLMs, an effective yet simple method that significantly reduces the computational burden while preserving model performance. LVPruning employs cross-attention modules to compute the importance of vision tokens based on their interaction with language tokens, determining which to prune. Importantly, LVPruning can be integrated without modifying the original MLLM parameters, which makes LVPruning simple to apply or remove. Our experiments show that LVPruning can effectively reduce up to 90% of vision tokens by the middle layer of LLaVA-1.5, resulting in a 62.1% decrease in inference Tera Floating-Point Operations Per Second (TFLOPs), with an average performance loss of just 0.45% across nine multi-modal benchmarks.
End-to-end Planner Training for Language Modeling
Oct 16, 2024



Through end-to-end training to predict the next token, LLMs have become valuable tools for various tasks. Enhancing their core training in language modeling can improve numerous downstream applications. A successful approach to enhance language modeling uses a separate planning module to predict abstract labels of future sentences and conditions the LM on these predictions. However, this method is non-differentiable, preventing joint end-to-end tuning of the planner with the LM. We propose an effective method to improve this approach by enabling joint fine-tuning of the planner and the LM. We show that a naive way of approximating the gradient of selecting a label via the straight-through estimator is not effective. Instead, we propose to use the predicted label probabilities as mixing weights to condition the LM on a weighted average of label embeddings in a differentiable manner. This not only enables joint fine-tuning of the planner and the LM, but also allows the LM to draw on the full label distribution predicted by the planner, retaining more information. Our experimental results show consistent improvements in perplexity.
DMON: A Simple yet Effective Approach for Argument Structure Learning
May 02, 2024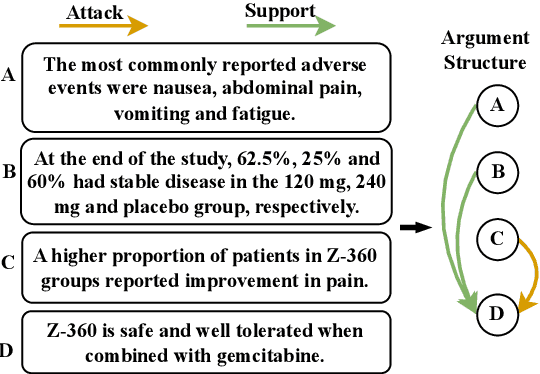
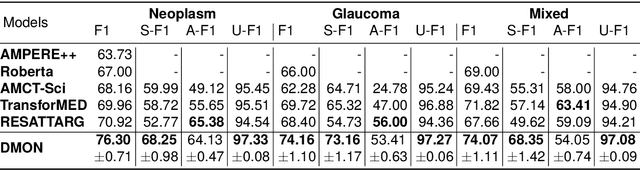
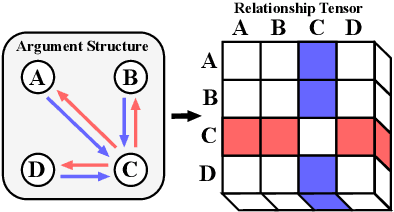
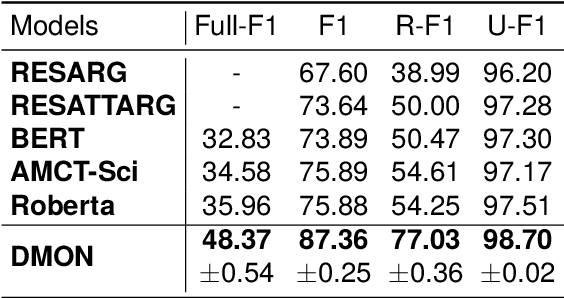
Argument structure learning~(ASL) entails predicting relations between arguments. Because it can structure a document to facilitate its understanding, it has been widely applied in many fields~(medical, commercial, and scientific domains). Despite its broad utilization, ASL remains a challenging task because it involves examining the complex relationships between the sentences in a potentially unstructured discourse. To resolve this problem, we have developed a simple yet effective approach called Dual-tower Multi-scale cOnvolution neural Network~(DMON) for the ASL task. Specifically, we organize arguments into a relationship matrix that together with the argument embeddings forms a relationship tensor and design a mechanism to capture relations with contextual arguments. Experimental results on three different-domain argument mining datasets demonstrate that our framework outperforms state-of-the-art models. The code is available at https://github.com/VRCMF/DMON.git .
MapGuide: A Simple yet Effective Method to Reconstruct Continuous Language from Brain Activities
Apr 02, 2024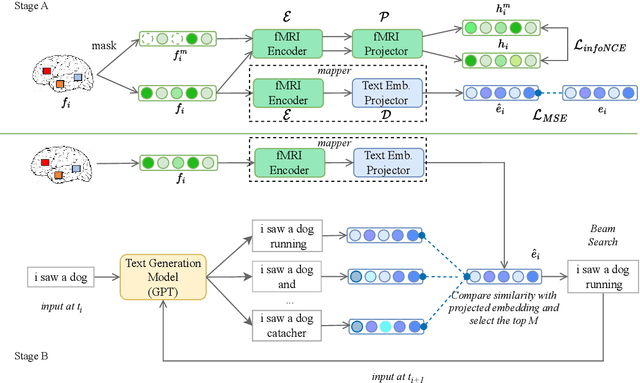
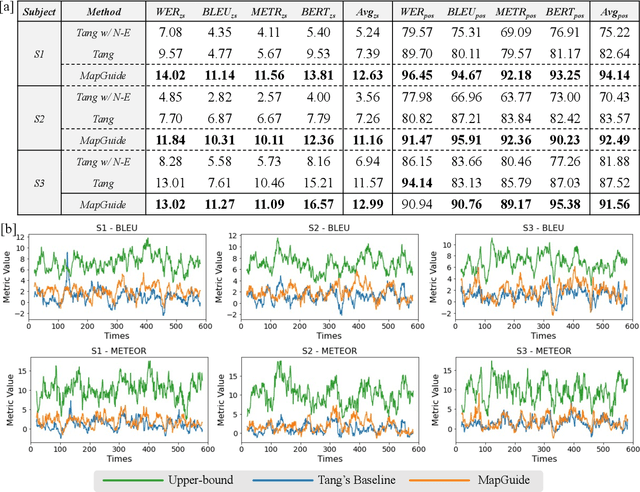
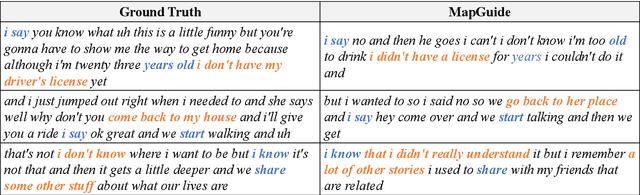
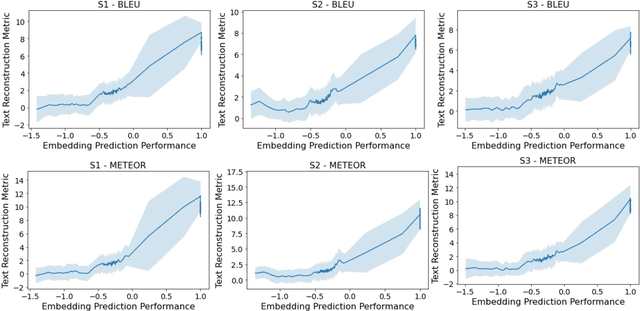
Decoding continuous language from brain activity is a formidable yet promising field of research. It is particularly significant for aiding people with speech disabilities to communicate through brain signals. This field addresses the complex task of mapping brain signals to text. The previous best attempt reverse-engineered this process in an indirect way: it began by learning to encode brain activity from text and then guided text generation by aligning with predicted brain responses. In contrast, we propose a simple yet effective method that guides text reconstruction by directly comparing them with the predicted text embeddings mapped from brain activities. Comprehensive experiments reveal that our method significantly outperforms the current state-of-the-art model, showing average improvements of 77% and 54% on BLEU and METEOR scores. We further validate the proposed modules through detailed ablation studies and case analyses and highlight a critical correlation: the more precisely we map brain activities to text embeddings, the better the text reconstruction results. Such insight can simplify the task of reconstructing language from brain activities for future work, emphasizing the importance of improving brain-to-text-embedding mapping techniques.
Computational Models to Study Language Processing in the Human Brain: A Survey
Mar 20, 2024



Despite differing from the human language processing mechanism in implementation and algorithms, current language models demonstrate remarkable human-like or surpassing language capabilities. Should computational language models be employed in studying the brain, and if so, when and how? To delve into this topic, this paper reviews efforts in using computational models for brain research, highlighting emerging trends. To ensure a fair comparison, the paper evaluates various computational models using consistent metrics on the same dataset. Our analysis reveals that no single model outperforms others on all datasets, underscoring the need for rich testing datasets and rigid experimental control to draw robust conclusions in studies involving computational models.