 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRaising Bars, Not Parameters: LilMoo Compact Language Model for Hindi
Mar 03, 2026The dominance of large multilingual foundation models has widened linguistic inequalities in Natural Language Processing (NLP), often leaving low-resource languages underrepresented. This paper introduces LilMoo, a 0.6-billion-parameter Hindi language model trained entirely from scratch to address this gap. Unlike prior Hindi models that rely on continual pretraining from opaque multilingual foundations, LilMoo is developed through a fully transparent and reproducible pipeline optimized for limited compute environments. We construct a high-quality Hindi corpus (GigaLekh) filtered through both heuristic and learned (LLM-as-a-judge) methods, complemented by bilingual augmentation with curated English data. Using this dataset, we explore various training recipes for small-scale language models. Across comprehensive evaluation suites, LilMoo consistently outperforms comparably sized multilingual baselines such as Qwen2.5-0.5B and Qwen3-0.6B, demonstrating that well-designed language-specific pretraining can rival large multilingual models at the sub-billion-parameter range.
Understanding Artificial Theory of Mind: Perturbed Tasks and Reasoning in Large Language Models
Feb 25, 2026Theory of Mind (ToM) refers to an agent's ability to model the internal states of others. Contributing to the debate whether large language models (LLMs) exhibit genuine ToM capabilities, our study investigates their ToM robustness using perturbations on false-belief tasks and examines the potential of Chain-of-Thought prompting (CoT) to enhance performance and explain the LLM's decision. We introduce a handcrafted, richly annotated ToM dataset, including classic and perturbed false belief tasks, the corresponding spaces of valid reasoning chains for correct task completion, subsequent reasoning faithfulness, task solutions, and propose metrics to evaluate reasoning chain correctness and to what extent final answers are faithful to reasoning traces of the generated CoT. We show a steep drop in ToM capabilities under task perturbation for all evaluated LLMs, questioning the notion of any robust form of ToM being present. While CoT prompting improves the ToM performance overall in a faithful manner, it surprisingly degrades accuracy for some perturbation classes, indicating that selective application is necessary.
IKnow: Instruction-Knowledge-Aware Continual Pretraining for Effective Domain Adaptation
Oct 23, 2025Continual pretraining promises to adapt large language models (LLMs) to new domains using only unlabeled test-time data, but naively applying standard self-supervised objectives to instruction-tuned models is known to degrade their instruction-following capability and semantic representations. Existing fixes assume access to the original base model or rely on knowledge from an external domain-specific database - both of which pose a realistic barrier in settings where the base model weights are withheld for safety reasons or reliable external corpora are unavailable. In this work, we propose Instruction-Knowledge-Aware Continual Adaptation (IKnow), a simple and general framework that formulates novel self-supervised objectives in the instruction-response dialogue format. Rather than depend- ing on external resources, IKnow leverages domain knowledge embedded within the text itself and learns to encode it at a deeper semantic level.
In-Training Defenses against Emergent Misalignment in Language Models
Aug 08, 2025Fine-tuning lets practitioners repurpose aligned large language models (LLMs) for new domains, yet recent work reveals emergent misalignment (EMA): Even a small, domain-specific fine-tune can induce harmful behaviors far outside the target domain. Even in the case where model weights are hidden behind a fine-tuning API, this gives attackers inadvertent access to a broadly misaligned model in a way that can be hard to detect from the fine-tuning data alone. We present the first systematic study of in-training safeguards against EMA that are practical for providers who expose fine-tuning via an API. We investigate four training regularization interventions: (i) KL-divergence regularization toward a safe reference model, (ii) $\ell_2$ distance in feature space, (iii) projecting onto a safe subspace (SafeLoRA), and (iv) interleaving of a small amount of safe training examples from a general instruct-tuning dataset. We first evaluate the methods' emergent misalignment effect across four malicious, EMA-inducing tasks. Second, we assess the methods' impacts on benign tasks. We conclude with a discussion of open questions in emergent misalignment research.
Judging Quality Across Languages: A Multilingual Approach to Pretraining Data Filtering with Language Models
May 28, 2025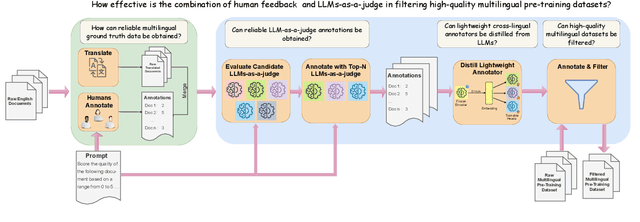
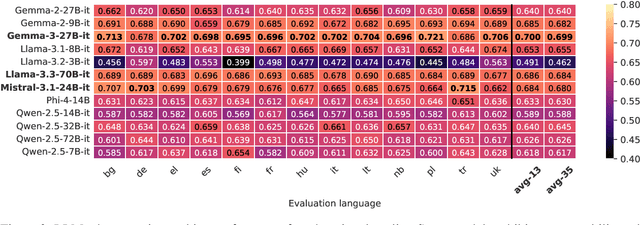

High-quality multilingual training data is essential for effectively pretraining large language models (LLMs). Yet, the availability of suitable open-source multilingual datasets remains limited. Existing state-of-the-art datasets mostly rely on heuristic filtering methods, restricting both their cross-lingual transferability and scalability. Here, we introduce JQL, a systematic approach that efficiently curates diverse and high-quality multilingual data at scale while significantly reducing computational demands. JQL distills LLMs' annotation capabilities into lightweight annotators based on pretrained multilingual embeddings. These models exhibit robust multilingual and cross-lingual performance, even for languages and scripts unseen during training. Evaluated empirically across 35 languages, the resulting annotation pipeline substantially outperforms current heuristic filtering methods like Fineweb2. JQL notably enhances downstream model training quality and increases data retention rates. Our research provides practical insights and valuable resources for multilingual data curation, raising the standards of multilingual dataset development.
Superalignment with Dynamic Human Values
Mar 17, 2025

Two core challenges of alignment are 1) scalable oversight and 2) accounting for the dynamic nature of human values. While solutions like recursive reward modeling address 1), they do not simultaneously account for 2). We sketch a roadmap for a novel algorithmic framework that trains a superhuman reasoning model to decompose complex tasks into subtasks that are still amenable to human-level guidance. Our approach relies on what we call the part-to-complete generalization hypothesis, which states that the alignment of subtask solutions generalizes to the alignment of complete solutions. We advocate for the need to measure this generalization and propose ways to improve it in the future.
End-to-end Planner Training for Language Modeling
Oct 16, 2024



Through end-to-end training to predict the next token, LLMs have become valuable tools for various tasks. Enhancing their core training in language modeling can improve numerous downstream applications. A successful approach to enhance language modeling uses a separate planning module to predict abstract labels of future sentences and conditions the LM on these predictions. However, this method is non-differentiable, preventing joint end-to-end tuning of the planner with the LM. We propose an effective method to improve this approach by enabling joint fine-tuning of the planner and the LM. We show that a naive way of approximating the gradient of selecting a label via the straight-through estimator is not effective. Instead, we propose to use the predicted label probabilities as mixing weights to condition the LM on a weighted average of label embeddings in a differentiable manner. This not only enables joint fine-tuning of the planner and the LM, but also allows the LM to draw on the full label distribution predicted by the planner, retaining more information. Our experimental results show consistent improvements in perplexity.
Open-Source Conversational AI with SpeechBrain 1.0
Jul 02, 2024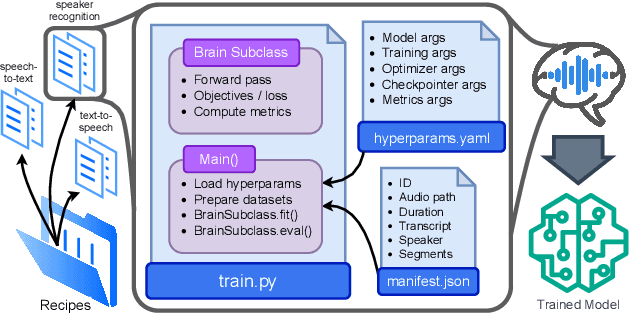

SpeechBrain is an open-source Conversational AI toolkit based on PyTorch, focused particularly on speech processing tasks such as speech recognition, speech enhancement, speaker recognition, text-to-speech, and much more. It promotes transparency and replicability by releasing both the pre-trained models and the complete "recipes" of code and algorithms required for training them. This paper presents SpeechBrain 1.0, a significant milestone in the evolution of the toolkit, which now has over 200 recipes for speech, audio, and language processing tasks, and more than 100 models available on Hugging Face. SpeechBrain 1.0 introduces new technologies to support diverse learning modalities, Large Language Model (LLM) integration, and advanced decoding strategies, along with novel models, tasks, and modalities. It also includes a new benchmark repository, offering researchers a unified platform for evaluating models across diverse tasks
Learning to Plan for Language Modeling from Unlabeled Data
Mar 31, 2024By training to predict the next token in an unlabeled corpus, large language models learn to perform many tasks without any labeled data. However, their next-token-prediction objective arguably limits their performance in scenarios that require planning, such as writing a coherent article. In this paper, we train a module for planning the future writing process via a self-supervised learning objective. By conditioning on generated latent plans, our model extends the successful language model formula to more abstract planning in an unsupervised way. Empirically, we demonstrate that our method improves language modeling performance in general, particularly with respect to the text structure. Because our framework uses a planner module that is unsupervised and external to the language model, new planner modules can be trained at large scale and easily be shared with the community.
Triple-Encoders: Representations That Fire Together, Wire Together
Feb 19, 2024



Search-based dialog models typically re-encode the dialog history at every turn, incurring high cost. Curved Contrastive Learning, a representation learning method that encodes relative distances between utterances into the embedding space via a bi-encoder, has recently shown promising results for dialog modeling at far superior efficiency. While high efficiency is achieved through independently encoding utterances, this ignores the importance of contextualization. To overcome this issue, this study introduces triple-encoders, which efficiently compute distributed utterance mixtures from these independently encoded utterances through a novel hebbian inspired co-occurrence learning objective without using any weights. Empirically, we find that triple-encoders lead to a substantial improvement over bi-encoders, and even to better zero-shot generalization than single-vector representation models without requiring re-encoding. Our code/model is publicly available.