 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBQ-NCO: Bisimulation Quotienting for Generalizable Neural Combinatorial Optimization
Jan 12, 2023Despite the success of Neural Combinatorial Optimization methods for end-to-end heuristic learning, out-of-distribution generalization remains a challenge. In this paper, we present a novel formulation of combinatorial optimization (CO) problems as Markov Decision Processes (MDPs) that effectively leverages symmetries of the CO problems to improve out-of-distribution robustness. Starting from the standard MDP formulation of constructive heuristics, we introduce a generic transformation based on bisimulation quotienting (BQ) in MDPs. This transformation allows to reduce the state space by accounting for the intrinsic symmetries of the CO problem and facilitates the MDP solving. We illustrate our approach on the Traveling Salesman, Capacitated Vehicle Routing and Knapsack Problems. We present a BQ reformulation of these problems and introduce a simple attention-based policy network that we train by imitation of (near) optimal solutions for small instances from a single distribution. We obtain new state-of-the-art generalization results for instances with up to 1000 nodes from synthetic and realistic benchmarks that vary both in size and node distributions.
Simple and Effective Balance of Contrastive Losses
Dec 22, 2021

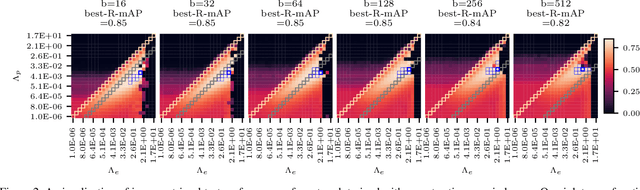
Contrastive losses have long been a key ingredient of deep metric learning and are now becoming more popular due to the success of self-supervised learning. Recent research has shown the benefit of decomposing such losses into two sub-losses which act in a complementary way when learning the representation network: a positive term and an entropy term. Although the overall loss is thus defined as a combination of two terms, the balance of these two terms is often hidden behind implementation details and is largely ignored and sub-optimal in practice. In this work, we approach the balance of contrastive losses as a hyper-parameter optimization problem, and propose a coordinate descent-based search method that efficiently find the hyper-parameters that optimize evaluation performance. In the process, we extend existing balance analyses to the contrastive margin loss, include batch size in the balance, and explain how to aggregate loss elements from the batch to maintain near-optimal performance over a larger range of batch sizes. Extensive experiments with benchmarks from deep metric learning and self-supervised learning show that optimal hyper-parameters are found faster with our method than with other common search methods.
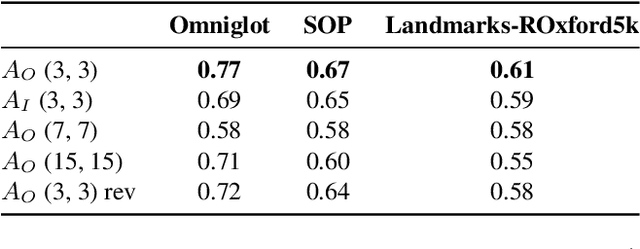
Learning with Label Noise for Image Retrieval by Selecting Interactions
Dec 21, 2021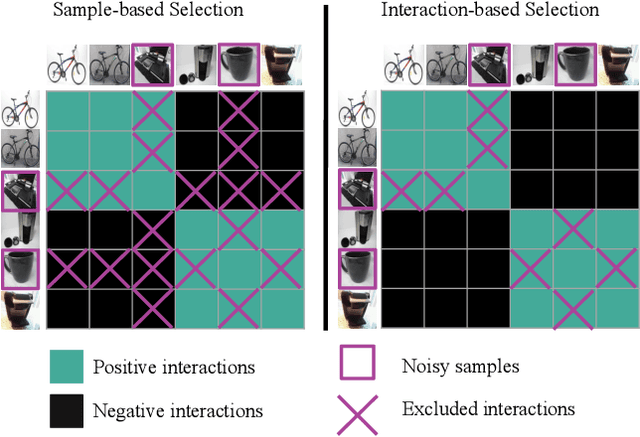
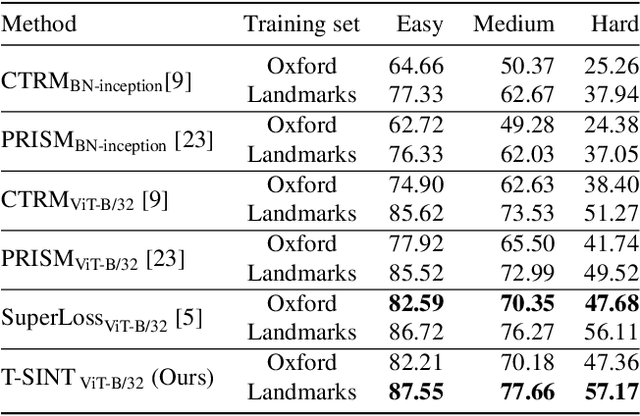
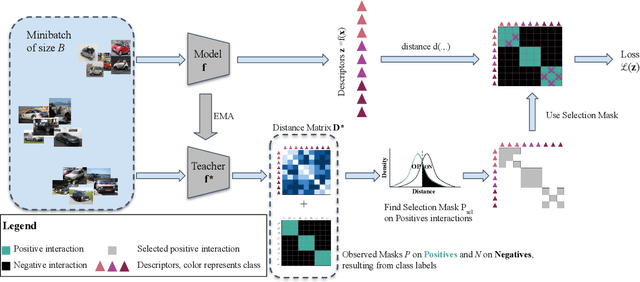
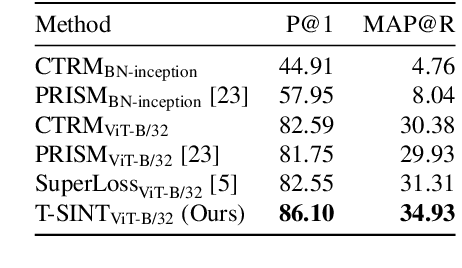
Learning with noisy labels is an active research area for image classification. However, the effect of noisy labels on image retrieval has been less studied. In this work, we propose a noise-resistant method for image retrieval named Teacher-based Selection of Interactions, T-SINT, which identifies noisy interactions, ie. elements in the distance matrix, and selects correct positive and negative interactions to be considered in the retrieval loss by using a teacher-based training setup which contributes to the stability. As a result, it consistently outperforms state-of-the-art methods on high noise rates across benchmark datasets with synthetic noise and more realistic noise.