 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAudio-Enhanced Text-to-Video Retrieval using Text-Conditioned Feature Alignment
Jul 24, 2023



Text-to-video retrieval systems have recently made significant progress by utilizing pre-trained models trained on large-scale image-text pairs. However, most of the latest methods primarily focus on the video modality while disregarding the audio signal for this task. Nevertheless, a recent advancement by ECLIPSE has improved long-range text-to-video retrieval by developing an audiovisual video representation. Nonetheless, the objective of the text-to-video retrieval task is to capture the complementary audio and video information that is pertinent to the text query rather than simply achieving better audio and video alignment. To address this issue, we introduce TEFAL, a TExt-conditioned Feature ALignment method that produces both audio and video representations conditioned on the text query. Instead of using only an audiovisual attention block, which could suppress the audio information relevant to the text query, our approach employs two independent cross-modal attention blocks that enable the text to attend to the audio and video representations separately. Our proposed method's efficacy is demonstrated on four benchmark datasets that include audio: MSR-VTT, LSMDC, VATEX, and Charades, and achieves better than state-of-the-art performance consistently across the four datasets. This is attributed to the additional text-query-conditioned audio representation and the complementary information it adds to the text-query-conditioned video representation.
The Met Dataset: Instance-level Recognition for Artworks
Feb 03, 2022

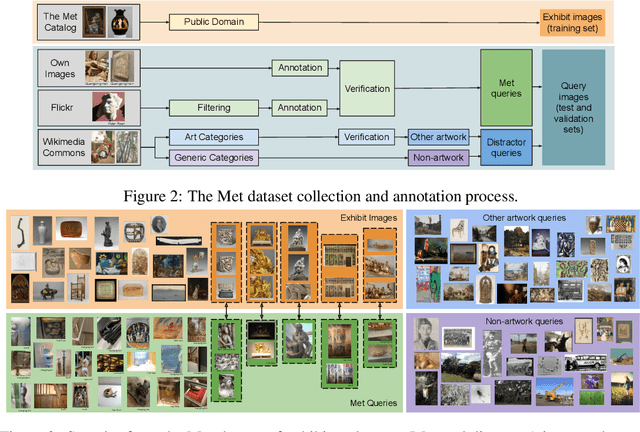
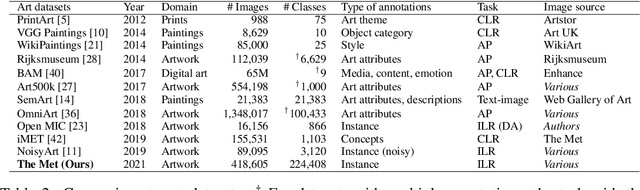
This work introduces a dataset for large-scale instance-level recognition in the domain of artworks. The proposed benchmark exhibits a number of different challenges such as large inter-class similarity, long tail distribution, and many classes. We rely on the open access collection of The Met museum to form a large training set of about 224k classes, where each class corresponds to a museum exhibit with photos taken under studio conditions. Testing is primarily performed on photos taken by museum guests depicting exhibits, which introduces a distribution shift between training and testing. Testing is additionally performed on a set of images not related to Met exhibits making the task resemble an out-of-distribution detection problem. The proposed benchmark follows the paradigm of other recent datasets for instance-level recognition on different domains to encourage research on domain independent approaches. A number of suitable approaches are evaluated to offer a testbed for future comparisons. Self-supervised and supervised contrastive learning are effectively combined to train the backbone which is used for non-parametric classification that is shown as a promising direction. Dataset webpage: http://cmp.felk.cvut.cz/met/
Simple and Effective Balance of Contrastive Losses
Dec 22, 2021

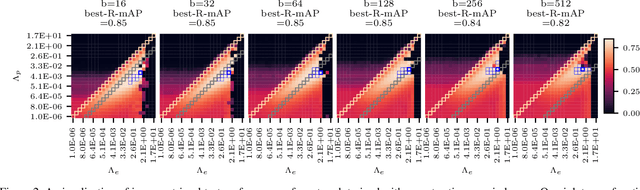
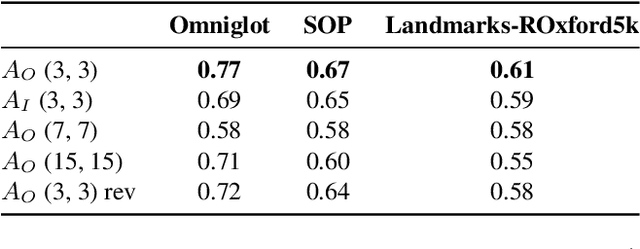
Contrastive losses have long been a key ingredient of deep metric learning and are now becoming more popular due to the success of self-supervised learning. Recent research has shown the benefit of decomposing such losses into two sub-losses which act in a complementary way when learning the representation network: a positive term and an entropy term. Although the overall loss is thus defined as a combination of two terms, the balance of these two terms is often hidden behind implementation details and is largely ignored and sub-optimal in practice. In this work, we approach the balance of contrastive losses as a hyper-parameter optimization problem, and propose a coordinate descent-based search method that efficiently find the hyper-parameters that optimize evaluation performance. In the process, we extend existing balance analyses to the contrastive margin loss, include batch size in the balance, and explain how to aggregate loss elements from the batch to maintain near-optimal performance over a larger range of batch sizes. Extensive experiments with benchmarks from deep metric learning and self-supervised learning show that optimal hyper-parameters are found faster with our method than with other common search methods.
Learning with Label Noise for Image Retrieval by Selecting Interactions
Dec 21, 2021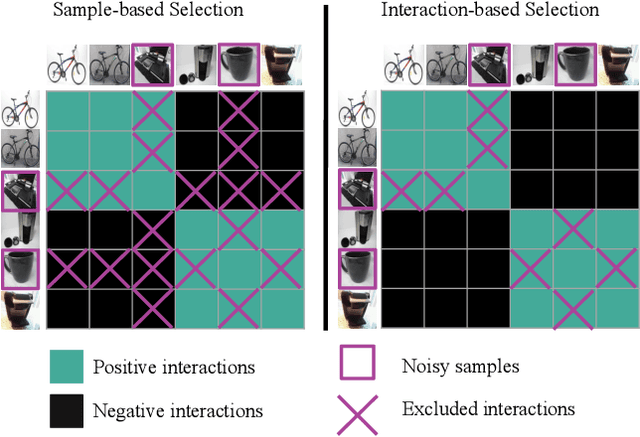
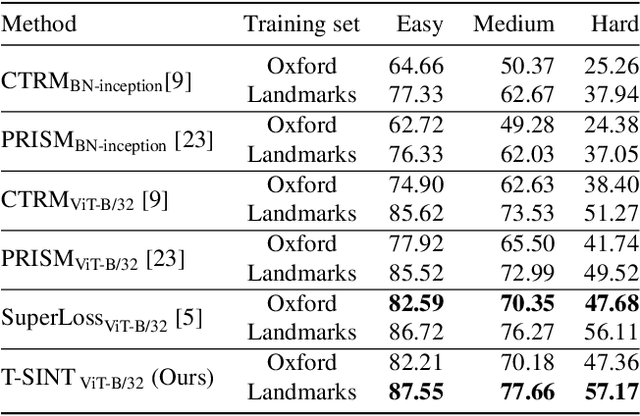
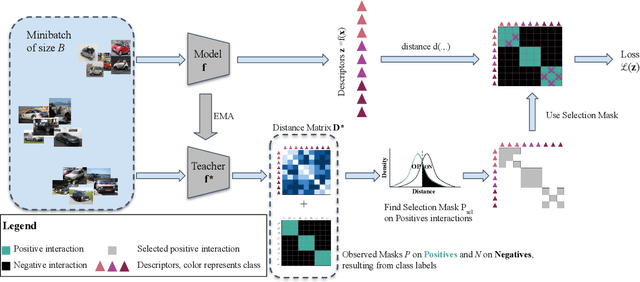
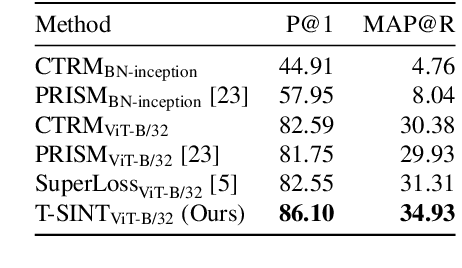
Learning with noisy labels is an active research area for image classification. However, the effect of noisy labels on image retrieval has been less studied. In this work, we propose a noise-resistant method for image retrieval named Teacher-based Selection of Interactions, T-SINT, which identifies noisy interactions, ie. elements in the distance matrix, and selects correct positive and negative interactions to be considered in the retrieval loss by using a teacher-based training setup which contributes to the stability. As a result, it consistently outperforms state-of-the-art methods on high noise rates across benchmark datasets with synthetic noise and more realistic noise.
Inside Out Visual Place Recognition
Nov 26, 2021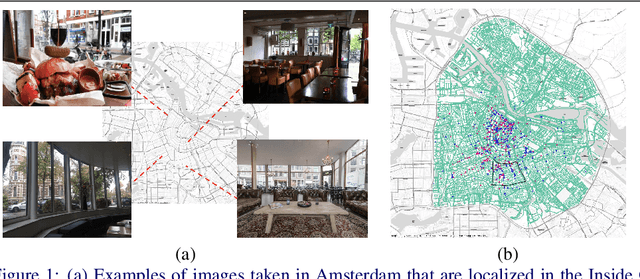
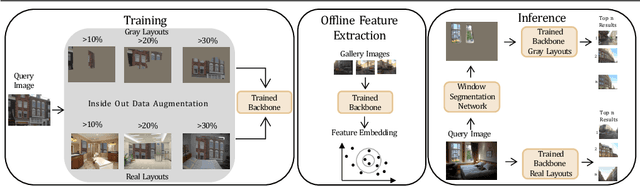
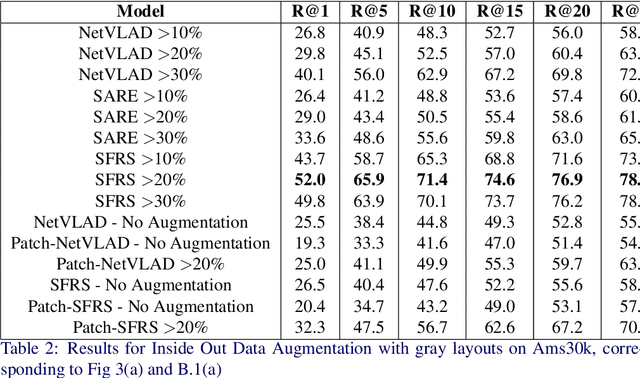
Visual Place Recognition (VPR) is generally concerned with localizing outdoor images. However, localizing indoor scenes that contain part of an outdoor scene can be of large value for a wide range of applications. In this paper, we introduce Inside Out Visual Place Recognition (IOVPR), a task aiming to localize images based on outdoor scenes visible through windows. For this task we present the new large-scale dataset Amsterdam-XXXL, with images taken in Amsterdam, that consists of 6.4 million panoramic street-view images and 1000 user-generated indoor queries. Additionally, we introduce a new training protocol Inside Out Data Augmentation to adapt Visual Place Recognition methods for localizing indoor images, demonstrating the potential of Inside Out Visual Place Recognition. We empirically show the benefits of our proposed data augmentation scheme on a smaller scale, whilst demonstrating the difficulty of this large-scale dataset for existing methods. With this new task we aim to encourage development of methods for IOVPR. The dataset and code are available for research purposes at https://github.com/saibr/IOVPR
Detecting CNN-Generated Facial Images in Real-World Scenarios
May 12, 2020
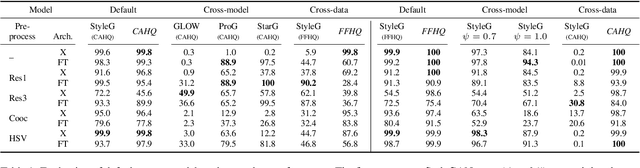
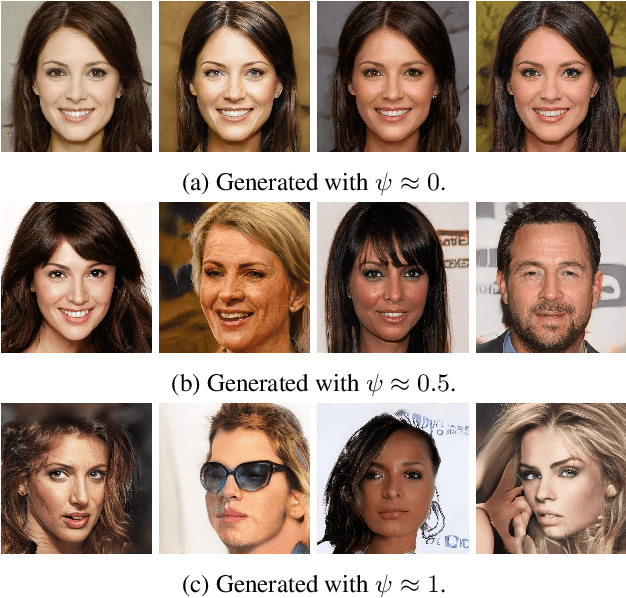
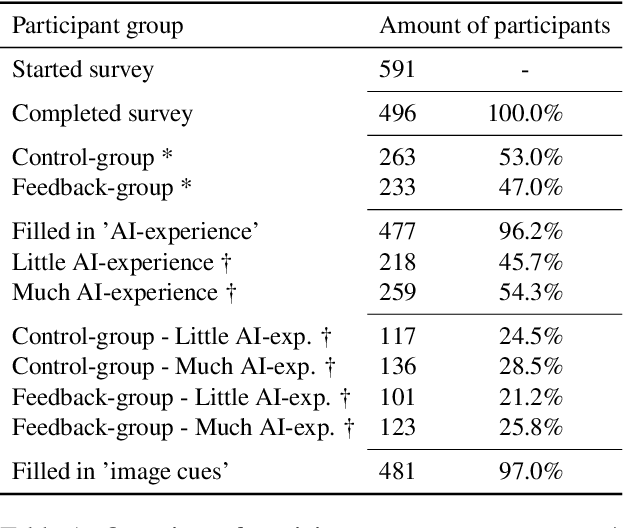
Artificial, CNN-generated images are now of such high quality that humans have trouble distinguishing them from real images. Several algorithmic detection methods have been proposed, but these appear to generalize poorly to data from unknown sources, making them infeasible for real-world scenarios. In this work, we present a framework for evaluating detection methods under real-world conditions, consisting of cross-model, cross-data, and post-processing evaluation, and we evaluate state-of-the-art detection methods using the proposed framework. Furthermore, we examine the usefulness of commonly used image pre-processing methods. Lastly, we evaluate human performance on detecting CNN-generated images, along with factors that influence this performance, by conducting an online survey. Our results suggest that CNN-based detection methods are not yet robust enough to be used in real-world scenarios.
Conditional Image Generation and Manipulation for User-Specified Content
May 11, 2020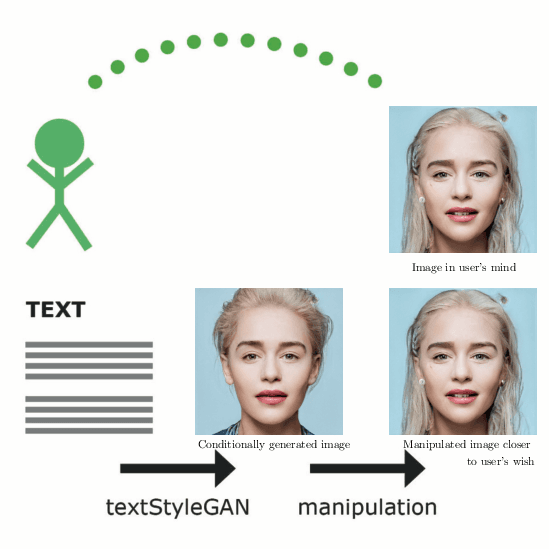
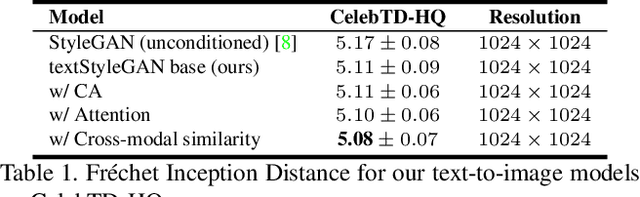
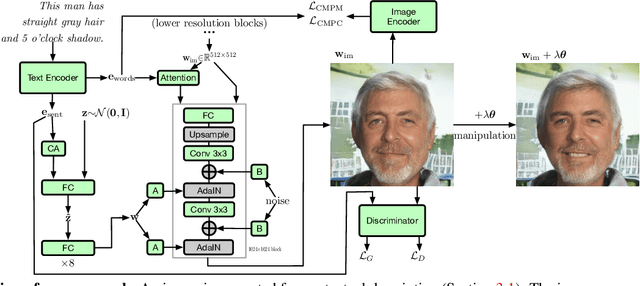
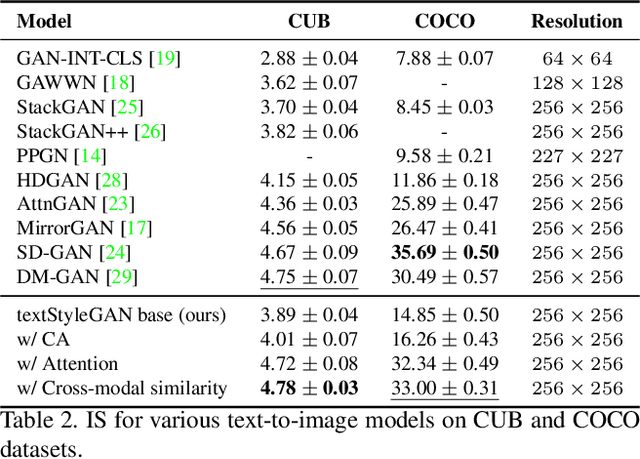
In recent years, Generative Adversarial Networks (GANs) have improved steadily towards generating increasingly impressive real-world images. It is useful to steer the image generation process for purposes such as content creation. This can be done by conditioning the model on additional information. However, when conditioning on additional information, there still exists a large set of images that agree with a particular conditioning. This makes it unlikely that the generated image is exactly as envisioned by a user, which is problematic for practical content creation scenarios such as generating facial composites or stock photos. To solve this problem, we propose a single pipeline for text-to-image generation and manipulation. In the first part of our pipeline we introduce textStyleGAN, a model that is conditioned on text. In the second part of our pipeline we make use of the pre-trained weights of textStyleGAN to perform semantic facial image manipulation. The approach works by finding semantic directions in latent space. We show that this method can be used to manipulate facial images for a wide range of attributes. Finally, we introduce the CelebTD-HQ dataset, an extension to CelebA-HQ, consisting of faces and corresponding textual descriptions.