 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultiplex Imaging Analysis in Pathology: a Comprehensive Review on Analytical Approaches and Digital Toolkits
Nov 01, 2024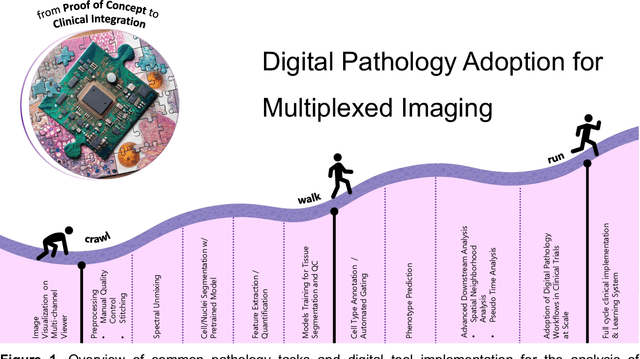

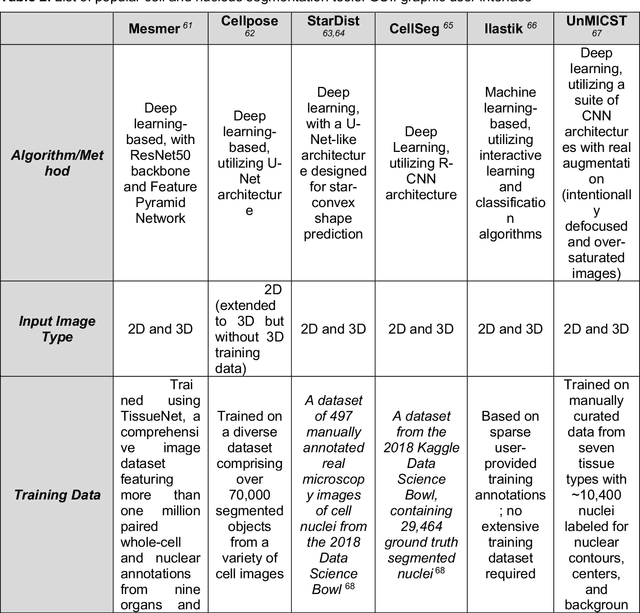
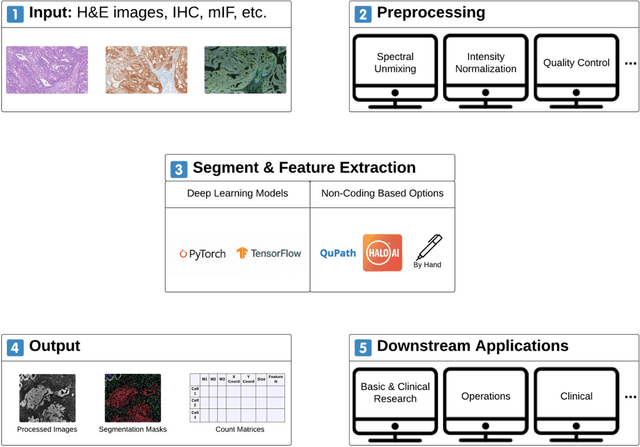
Conventional histopathology has long been essential for disease diagnosis, relying on visual inspection of tissue sections. Immunohistochemistry aids in detecting specific biomarkers but is limited by its single-marker approach, restricting its ability to capture the full tissue environment. The advent of multiplexed imaging technologies, like multiplexed immunofluorescence and spatial transcriptomics, allows for simultaneous visualization of multiple biomarkers in a single section, enhancing morphological data with molecular and spatial information. This provides a more comprehensive view of the tissue microenvironment, cellular interactions, and disease mechanisms - crucial for understanding disease progression, prognosis, and treatment response. However, the extensive data from multiplexed imaging necessitates sophisticated computational methods for preprocessing, segmentation, feature extraction, and spatial analysis. These tools are vital for managing large, multidimensional datasets, converting raw imaging data into actionable insights. By automating labor-intensive tasks and enhancing reproducibility and accuracy, computational tools are pivotal in diagnostics and research. This review explores the current landscape of multiplexed imaging in pathology, detailing workflows and key technologies like PathML, an AI-powered platform that streamlines image analysis, making complex dataset interpretation accessible for clinical and research settings.
Audio-Enhanced Text-to-Video Retrieval using Text-Conditioned Feature Alignment
Jul 24, 2023



Text-to-video retrieval systems have recently made significant progress by utilizing pre-trained models trained on large-scale image-text pairs. However, most of the latest methods primarily focus on the video modality while disregarding the audio signal for this task. Nevertheless, a recent advancement by ECLIPSE has improved long-range text-to-video retrieval by developing an audiovisual video representation. Nonetheless, the objective of the text-to-video retrieval task is to capture the complementary audio and video information that is pertinent to the text query rather than simply achieving better audio and video alignment. To address this issue, we introduce TEFAL, a TExt-conditioned Feature ALignment method that produces both audio and video representations conditioned on the text query. Instead of using only an audiovisual attention block, which could suppress the audio information relevant to the text query, our approach employs two independent cross-modal attention blocks that enable the text to attend to the audio and video representations separately. Our proposed method's efficacy is demonstrated on four benchmark datasets that include audio: MSR-VTT, LSMDC, VATEX, and Charades, and achieves better than state-of-the-art performance consistently across the four datasets. This is attributed to the additional text-query-conditioned audio representation and the complementary information it adds to the text-query-conditioned video representation.
Selective Structured State-Spaces for Long-Form Video Understanding
Mar 25, 2023
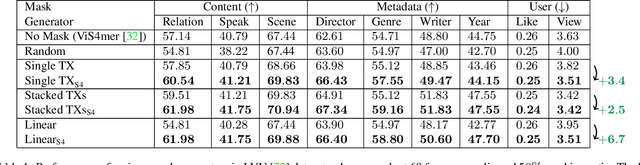
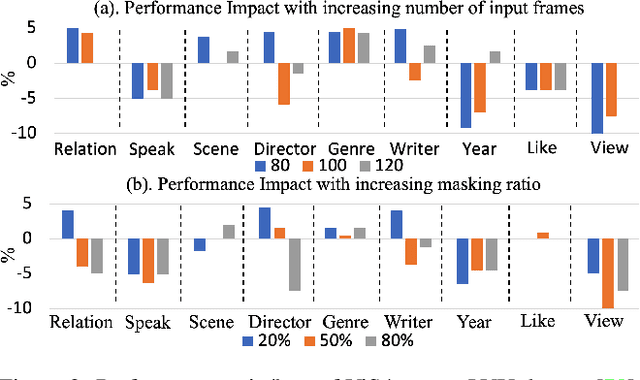
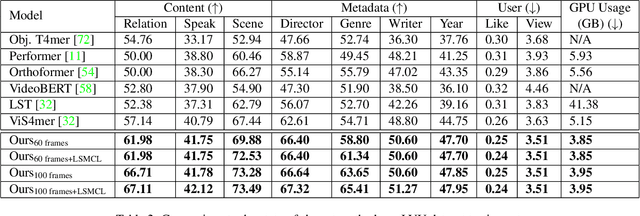
Effective modeling of complex spatiotemporal dependencies in long-form videos remains an open problem. The recently proposed Structured State-Space Sequence (S4) model with its linear complexity offers a promising direction in this space. However, we demonstrate that treating all image-tokens equally as done by S4 model can adversely affect its efficiency and accuracy. To address this limitation, we present a novel Selective S4 (i.e., S5) model that employs a lightweight mask generator to adaptively select informative image tokens resulting in more efficient and accurate modeling of long-term spatiotemporal dependencies in videos. Unlike previous mask-based token reduction methods used in transformers, our S5 model avoids the dense self-attention calculation by making use of the guidance of the momentum-updated S4 model. This enables our model to efficiently discard less informative tokens and adapt to various long-form video understanding tasks more effectively. However, as is the case for most token reduction methods, the informative image tokens could be dropped incorrectly. To improve the robustness and the temporal horizon of our model, we propose a novel long-short masked contrastive learning (LSMCL) approach that enables our model to predict longer temporal context using shorter input videos. We present extensive comparative results using three challenging long-form video understanding datasets (LVU, COIN and Breakfast), demonstrating that our approach consistently outperforms the previous state-of-the-art S4 model by up to 9.6% accuracy while reducing its memory footprint by 23%.
Multiscale Audio Spectrogram Transformer for Efficient Audio Classification
Mar 19, 2023Audio event has a hierarchical architecture in both time and frequency and can be grouped together to construct more abstract semantic audio classes. In this work, we develop a multiscale audio spectrogram Transformer (MAST) that employs hierarchical representation learning for efficient audio classification. Specifically, MAST employs one-dimensional (and two-dimensional) pooling operators along the time (and frequency domains) in different stages, and progressively reduces the number of tokens and increases the feature dimensions. MAST significantly outperforms AST~\cite{gong2021ast} by 22.2\%, 4.4\% and 4.7\% on Kinetics-Sounds, Epic-Kitchens-100 and VGGSound in terms of the top-1 accuracy without external training data. On the downloaded AudioSet dataset, which has over 20\% missing audios, MAST also achieves slightly better accuracy than AST. In addition, MAST is 5x more efficient in terms of multiply-accumulates (MACs) with 42\% reduction in the number of parameters compared to AST. Through clustering metrics and visualizations, we demonstrate that the proposed MAST can learn semantically more separable feature representations from audio signals.