 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSaliMory: Orchestrating Cognitive Memory for Conversational Agents
Jun 02, 2026Conversational agents that serve as lifelong companions must maintain persistent memory across all interactions. However, simply expanding context windows with raw retrieval degrades reasoning quality, while training memory agents via standard reinforcement learning creates a severe credit assignment bottleneck in a multi-stage pipeline. To solve this, we introduce SALIMORY, a framework that trains a single language model to manage a cognitively-structured memory-spanning user facts, preferences, and working memory. By introducing a hierarchical stage-wise process reward and reward-decomposed contrastive refinement, SALIMORY provides isolated supervision for distinct memory operations (selective filtering, consolidation, and cue-driven recall) end-to-end. SALIMORY cuts memory-attributed failures by one-third, outperforms the state-of-the-art by over 10% in end-to-end accuracy, and more than doubles the Good Personalization rate.
CoLLM: A Large Language Model for Composed Image Retrieval
Mar 25, 2025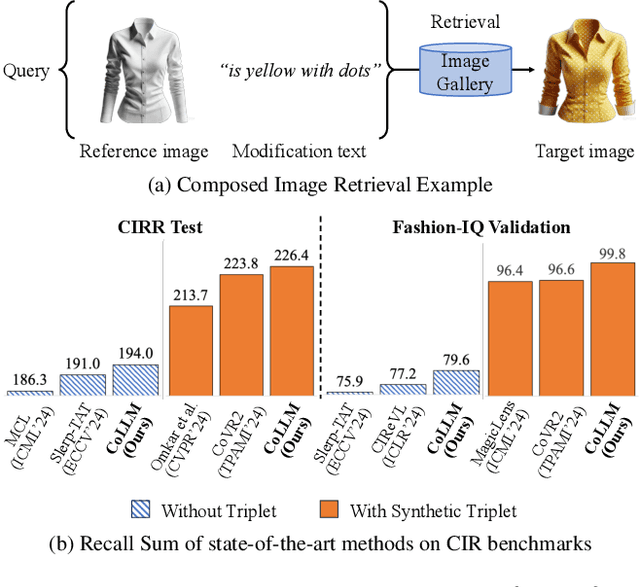
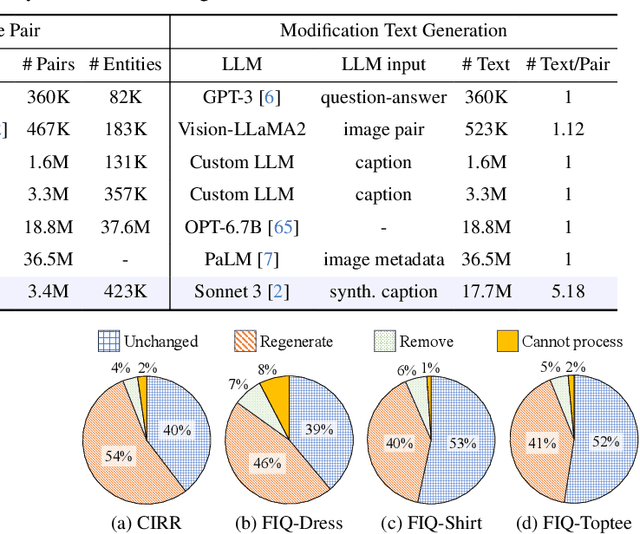
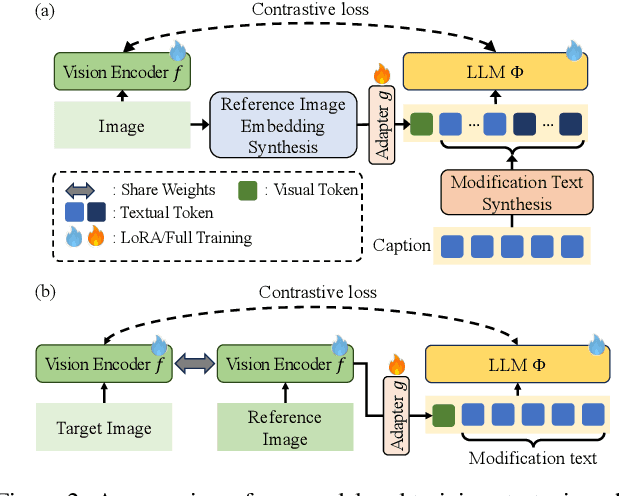
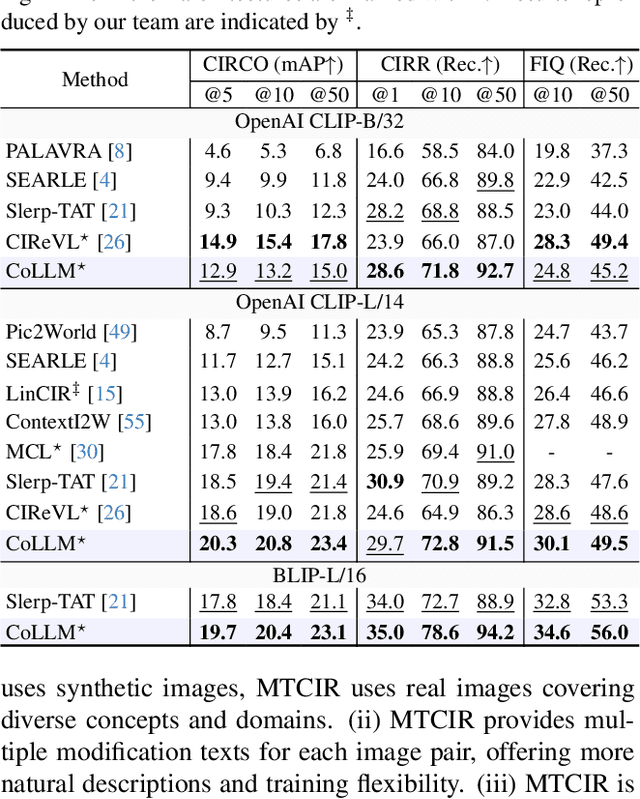
Composed Image Retrieval (CIR) is a complex task that aims to retrieve images based on a multimodal query. Typical training data consists of triplets containing a reference image, a textual description of desired modifications, and the target image, which are expensive and time-consuming to acquire. The scarcity of CIR datasets has led to zero-shot approaches utilizing synthetic triplets or leveraging vision-language models (VLMs) with ubiquitous web-crawled image-caption pairs. However, these methods have significant limitations: synthetic triplets suffer from limited scale, lack of diversity, and unnatural modification text, while image-caption pairs hinder joint embedding learning of the multimodal query due to the absence of triplet data. Moreover, existing approaches struggle with complex and nuanced modification texts that demand sophisticated fusion and understanding of vision and language modalities. We present CoLLM, a one-stop framework that effectively addresses these limitations. Our approach generates triplets on-the-fly from image-caption pairs, enabling supervised training without manual annotation. We leverage Large Language Models (LLMs) to generate joint embeddings of reference images and modification texts, facilitating deeper multimodal fusion. Additionally, we introduce Multi-Text CIR (MTCIR), a large-scale dataset comprising 3.4M samples, and refine existing CIR benchmarks (CIRR and Fashion-IQ) to enhance evaluation reliability. Experimental results demonstrate that CoLLM achieves state-of-the-art performance across multiple CIR benchmarks and settings. MTCIR yields competitive results, with up to 15% performance improvement. Our refined benchmarks provide more reliable evaluation metrics for CIR models, contributing to the advancement of this important field.
M-LLM Based Video Frame Selection for Efficient Video Understanding
Feb 27, 2025Recent advances in Multi-Modal Large Language Models (M-LLMs) show promising results in video reasoning. Popular Multi-Modal Large Language Model (M-LLM) frameworks usually apply naive uniform sampling to reduce the number of video frames that are fed into an M-LLM, particularly for long context videos. However, it could lose crucial context in certain periods of a video, so that the downstream M-LLM may not have sufficient visual information to answer a question. To attack this pain point, we propose a light-weight M-LLM -based frame selection method that adaptively select frames that are more relevant to users' queries. In order to train the proposed frame selector, we introduce two supervision signals (i) Spatial signal, where single frame importance score by prompting a M-LLM; (ii) Temporal signal, in which multiple frames selection by prompting Large Language Model (LLM) using the captions of all frame candidates. The selected frames are then digested by a frozen downstream video M-LLM for visual reasoning and question answering. Empirical results show that the proposed M-LLM video frame selector improves the performances various downstream video Large Language Model (video-LLM) across medium (ActivityNet, NExT-QA) and long (EgoSchema, LongVideoBench) context video question answering benchmarks.
LEMaRT: Label-Efficient Masked Region Transform for Image Harmonization
Apr 25, 2023



We present a simple yet effective self-supervised pre-training method for image harmonization which can leverage large-scale unannotated image datasets. To achieve this goal, we first generate pre-training data online with our Label-Efficient Masked Region Transform (LEMaRT) pipeline. Given an image, LEMaRT generates a foreground mask and then applies a set of transformations to perturb various visual attributes, e.g., defocus blur, contrast, saturation, of the region specified by the generated mask. We then pre-train image harmonization models by recovering the original image from the perturbed image. Secondly, we introduce an image harmonization model, namely SwinIH, by retrofitting the Swin Transformer [27] with a combination of local and global self-attention mechanisms. Pre-training SwinIH with LEMaRT results in a new state of the art for image harmonization, while being label-efficient, i.e., consuming less annotated data for fine-tuning than existing methods. Notably, on iHarmony4 dataset [8], SwinIH outperforms the state of the art, i.e., SCS-Co [16] by a margin of 0.4 dB when it is fine-tuned on only 50% of the training data, and by 1.0 dB when it is trained on the full training dataset.
Selective Structured State-Spaces for Long-Form Video Understanding
Mar 25, 2023
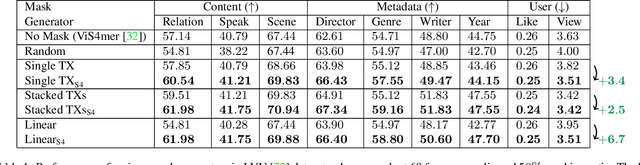
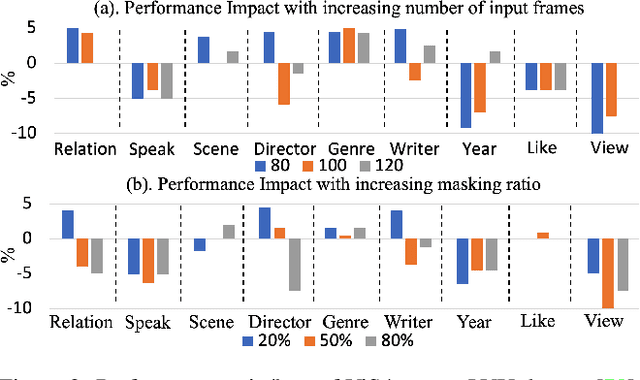
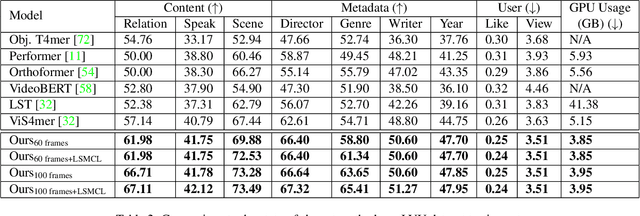
Effective modeling of complex spatiotemporal dependencies in long-form videos remains an open problem. The recently proposed Structured State-Space Sequence (S4) model with its linear complexity offers a promising direction in this space. However, we demonstrate that treating all image-tokens equally as done by S4 model can adversely affect its efficiency and accuracy. To address this limitation, we present a novel Selective S4 (i.e., S5) model that employs a lightweight mask generator to adaptively select informative image tokens resulting in more efficient and accurate modeling of long-term spatiotemporal dependencies in videos. Unlike previous mask-based token reduction methods used in transformers, our S5 model avoids the dense self-attention calculation by making use of the guidance of the momentum-updated S4 model. This enables our model to efficiently discard less informative tokens and adapt to various long-form video understanding tasks more effectively. However, as is the case for most token reduction methods, the informative image tokens could be dropped incorrectly. To improve the robustness and the temporal horizon of our model, we propose a novel long-short masked contrastive learning (LSMCL) approach that enables our model to predict longer temporal context using shorter input videos. We present extensive comparative results using three challenging long-form video understanding datasets (LVU, COIN and Breakfast), demonstrating that our approach consistently outperforms the previous state-of-the-art S4 model by up to 9.6% accuracy while reducing its memory footprint by 23%.
Scalable Temporal Localization of Sensitive Activities in Movies and TV Episodes
Jun 16, 2022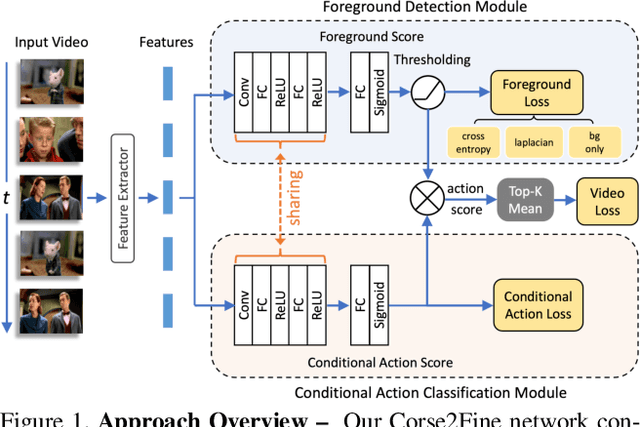
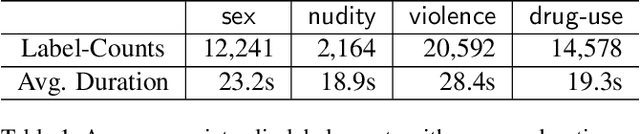


To help customers make better-informed viewing choices, video-streaming services try to moderate their content and provide more visibility into which portions of their movies and TV episodes contain age-appropriate material (e.g., nudity, sex, violence, or drug-use). Supervised models to localize these sensitive activities require large amounts of clip-level labeled data which is hard to obtain, while weakly-supervised models to this end usually do not offer competitive accuracy. To address this challenge, we propose a novel Coarse2Fine network designed to make use of readily obtainable video-level weak labels in conjunction with sparse clip-level labels of age-appropriate activities. Our model aggregates frame-level predictions to make video-level classifications and is therefore able to leverage sparse clip-level labels along with video-level labels. Furthermore, by performing frame-level predictions in a hierarchical manner, our approach is able to overcome the label-imbalance problem caused due to the rare-occurrence nature of age-appropriate content. We present comparative results of our approach using 41,234 movies and TV episodes (~3 years of video-content) from 521 sub-genres and 250 countries making it by far the largest-scale empirical analysis of age-appropriate activity localization in long-form videos ever published. Our approach offers 107.2% relative mAP improvement (from 5.5% to 11.4%) over existing state-of-the-art activity-localization approaches.
Robust Cross-Modal Representation Learning with Progressive Self-Distillation
Apr 10, 2022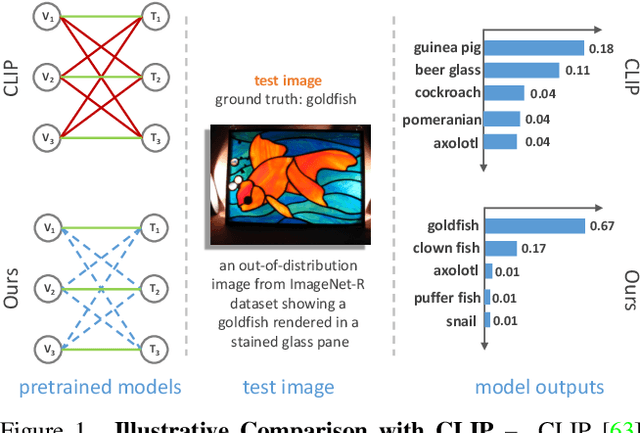

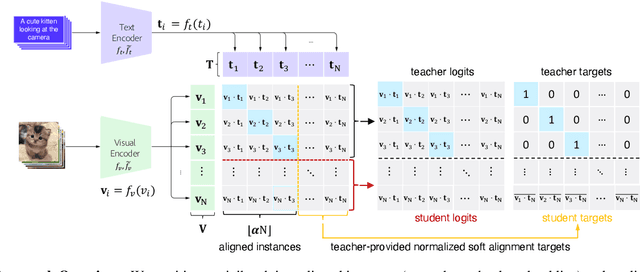
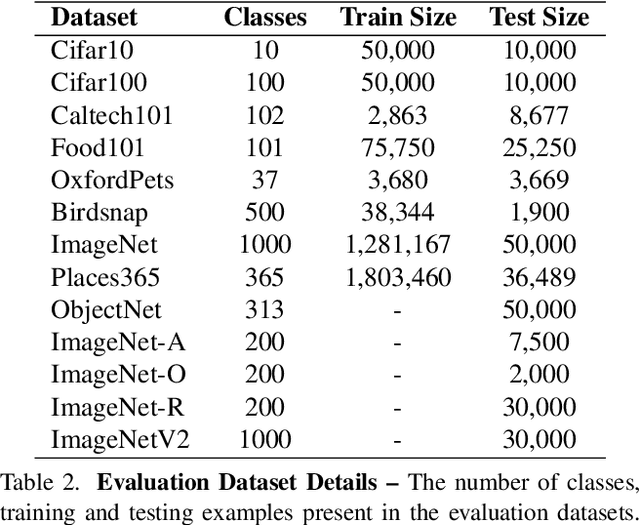
The learning objective of vision-language approach of CLIP does not effectively account for the noisy many-to-many correspondences found in web-harvested image captioning datasets, which contributes to its compute and data inefficiency. To address this challenge, we introduce a novel training framework based on cross-modal contrastive learning that uses progressive self-distillation and soft image-text alignments to more efficiently learn robust representations from noisy data. Our model distills its own knowledge to dynamically generate soft-alignment targets for a subset of images and captions in every minibatch, which are then used to update its parameters. Extensive evaluation across 14 benchmark datasets shows that our method consistently outperforms its CLIP counterpart in multiple settings, including: (a) zero-shot classification, (b) linear probe transfer, and (c) image-text retrieval, without incurring added computational cost. Analysis using an ImageNet-based robustness test-bed reveals that our method offers better effective robustness to natural distribution shifts compared to both ImageNet-trained models and CLIP itself. Lastly, pretraining with datasets spanning two orders of magnitude in size shows that our improvements over CLIP tend to scale with number of training examples.
Depth-Guided Sparse Structure-from-Motion for Movies and TV Shows
Apr 05, 2022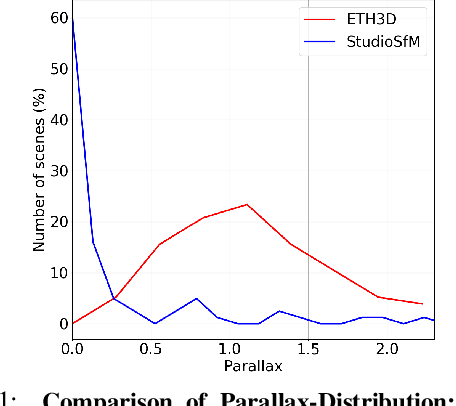
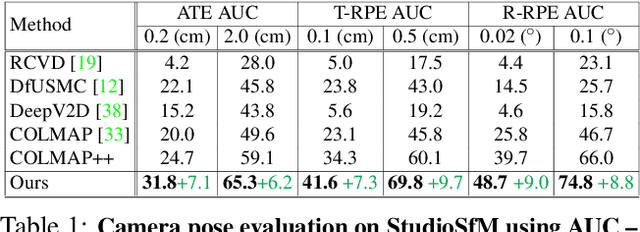
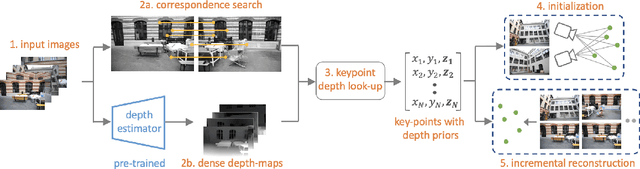
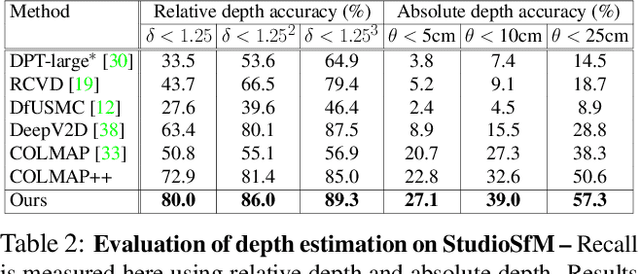
Existing approaches for Structure from Motion (SfM) produce impressive 3-D reconstruction results especially when using imagery captured with large parallax. However, to create engaging video-content in movies and TV shows, the amount by which a camera can be moved while filming a particular shot is often limited. The resulting small-motion parallax between video frames makes standard geometry-based SfM approaches not as effective for movies and TV shows. To address this challenge, we propose a simple yet effective approach that uses single-frame depth-prior obtained from a pretrained network to significantly improve geometry-based SfM for our small-parallax setting. To this end, we first use the depth-estimates of the detected keypoints to reconstruct the point cloud and camera-pose for initial two-view reconstruction. We then perform depth-regularized optimization to register new images and triangulate the new points during incremental reconstruction. To comprehensively evaluate our approach, we introduce a new dataset (StudioSfM) consisting of 130 shots with 21K frames from 15 studio-produced videos that are manually annotated by a professional CG studio. We demonstrate that our approach: (a) significantly improves the quality of 3-D reconstruction for our small-parallax setting, (b) does not cause any degradation for data with large-parallax, and (c) maintains the generalizability and scalability of geometry-based sparse SfM. Our dataset can be obtained at https://github.com/amazon-research/small-baseline-camera-tracking.
Movies2Scenes: Learning Scene Representations Using Movie Similarities
Mar 12, 2022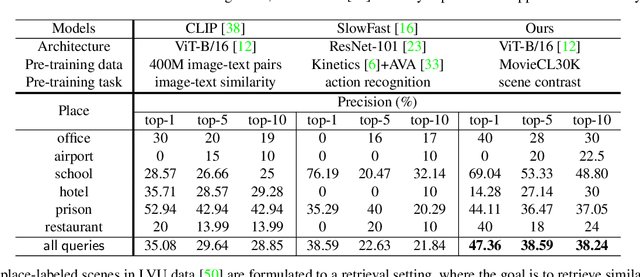
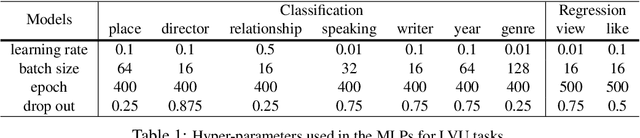
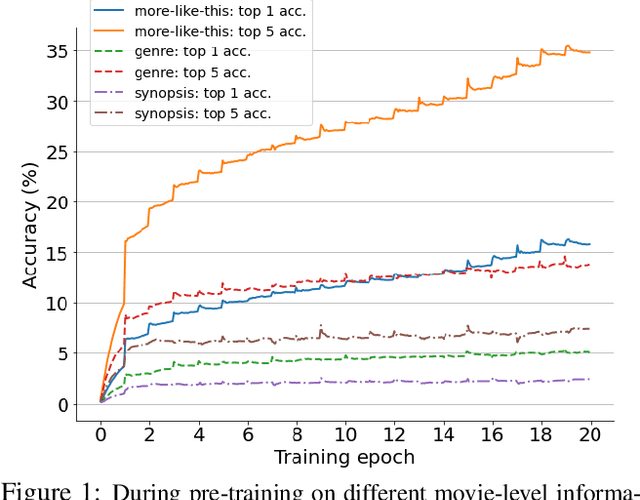
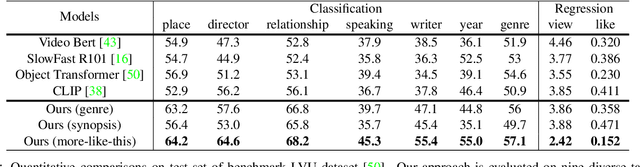
Labeling movie-scenes is a time-consuming process which makes applying end-to-end supervised methods for scene-understanding a challenging problem. Moreover, directly using image-based visual representations for scene-understanding tasks does not prove to be effective given the large gap between the two domains. To address these challenges, we propose a novel contrastive learning approach that uses commonly available movie-level information (e.g., co-watch, genre, synopsis) to learn a general-purpose scene-level representation. Our learned representation comfortably outperforms existing state-of-the-art approaches on eleven downstream tasks evaluated using multiple benchmark datasets. To further demonstrate generalizability of our learned representation, we present its comparative results on a set of video-moderation tasks evaluated using a newly collected large-scale internal movie dataset.
Shot Contrastive Self-Supervised Learning for Scene Boundary Detection
Apr 28, 2021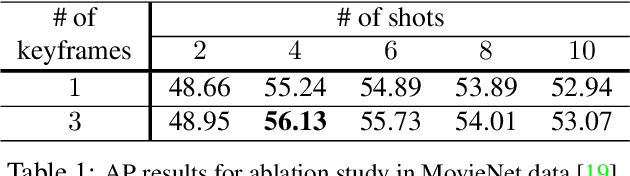
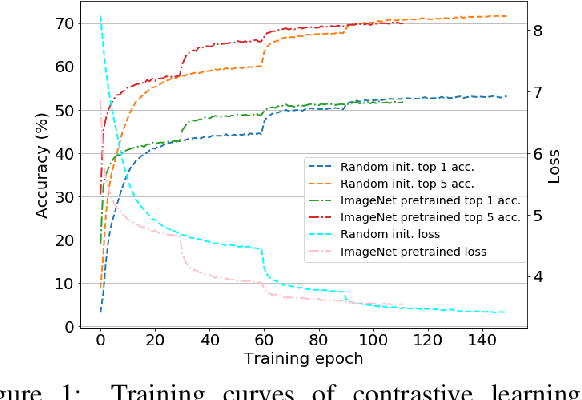

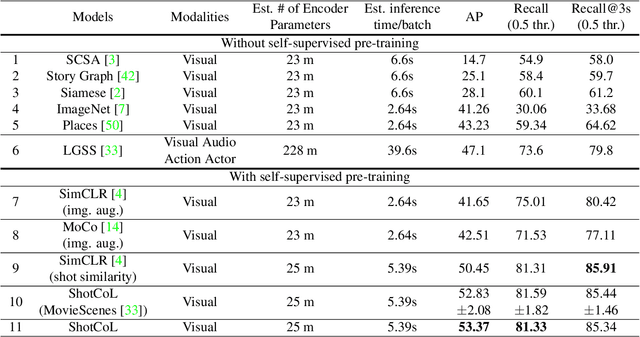
Scenes play a crucial role in breaking the storyline of movies and TV episodes into semantically cohesive parts. However, given their complex temporal structure, finding scene boundaries can be a challenging task requiring large amounts of labeled training data. To address this challenge, we present a self-supervised shot contrastive learning approach (ShotCoL) to learn a shot representation that maximizes the similarity between nearby shots compared to randomly selected shots. We show how to apply our learned shot representation for the task of scene boundary detection to offer state-of-the-art performance on the MovieNet dataset while requiring only ~25% of the training labels, using 9x fewer model parameters and offering 7x faster runtime. To assess the effectiveness of ShotCoL on novel applications of scene boundary detection, we take on the problem of finding timestamps in movies and TV episodes where video-ads can be inserted while offering a minimally disruptive viewing experience. To this end, we collected a new dataset called AdCuepoints with 3,975 movies and TV episodes, 2.2 million shots and 19,119 minimally disruptive ad cue-point labels. We present a thorough empirical analysis on this dataset demonstrating the effectiveness of ShotCoL for ad cue-points detection.