 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePangu Ultra MoE: How to Train Your Big MoE on Ascend NPUs
May 07, 2025



Sparse large language models (LLMs) with Mixture of Experts (MoE) and close to a trillion parameters are dominating the realm of most capable language models. However, the massive model scale poses significant challenges for the underlying software and hardware systems. In this paper, we aim to uncover a recipe to harness such scale on Ascend NPUs. The key goals are better usage of the computing resources under the dynamic sparse model structures and materializing the expected performance gain on the actual hardware. To select model configurations suitable for Ascend NPUs without repeatedly running the expensive experiments, we leverage simulation to compare the trade-off of various model hyperparameters. This study led to Pangu Ultra MoE, a sparse LLM with 718 billion parameters, and we conducted experiments on the model to verify the simulation results. On the system side, we dig into Expert Parallelism to optimize the communication between NPU devices to reduce the synchronization overhead. We also optimize the memory efficiency within the devices to further reduce the parameter and activation management overhead. In the end, we achieve an MFU of 30.0% when training Pangu Ultra MoE, with performance comparable to that of DeepSeek R1, on 6K Ascend NPUs, and demonstrate that the Ascend system is capable of harnessing all the training stages of the state-of-the-art language models. Extensive experiments indicate that our recipe can lead to efficient training of large-scale sparse language models with MoE. We also study the behaviors of such models for future reference.
Reconstructing Cell Lineage Trees from Phenotypic Features with Metric Learning
Mar 18, 2025How a single fertilized cell gives rise to a complex array of specialized cell types in development is a central question in biology. The cells grow, divide, and acquire differentiated characteristics through poorly understood molecular processes. A key approach to studying developmental processes is to infer the tree graph of cell lineage division and differentiation histories, providing an analytical framework for dissecting individual cells' molecular decisions during replication and differentiation. Although genetically engineered lineage-tracing methods have advanced the field, they are either infeasible or ethically constrained in many organisms. In contrast, modern single-cell technologies can measure high-content molecular profiles (e.g., transcriptomes) in a wide range of biological systems. Here, we introduce CellTreeQM, a novel deep learning method based on transformer architectures that learns an embedding space with geometric properties optimized for tree-graph inference. By formulating lineage reconstruction as a tree-metric learning problem, we have systematically explored supervised, weakly supervised, and unsupervised training settings and present a Lineage Reconstruction Benchmark to facilitate comprehensive evaluation of our learning method. We benchmarked the method on (1) synthetic data modeled via Brownian motion with independent noise and spurious signals and (2) lineage-resolved single-cell RNA sequencing datasets. Experimental results show that CellTreeQM recovers lineage structures with minimal supervision and limited data, offering a scalable framework for uncovering cell lineage relationships in challenging animal models. To our knowledge, this is the first method to cast cell lineage inference explicitly as a metric learning task, paving the way for future computational models aimed at uncovering the molecular dynamics of cell lineage.
Complexity Matters: Dynamics of Feature Learning in the Presence of Spurious Correlations
Mar 05, 2024Existing research often posits spurious features as "easier" to learn than core features in neural network optimization, but the impact of their relative simplicity remains under-explored. Moreover they mainly focus on the end performance intead of the learning dynamics of feature learning. In this paper, we propose a theoretical framework and associated synthetic dataset grounded in boolean function analysis which allows for fine-grained control on the relative complexity (compared to core features) and correlation strength (with respect to the label) of spurious features to study the dynamics of feature learning under spurious correlation. Our setup uncovers several interesting phenomenon: (1) stronger spurious correlations or simpler spurious features slow down the rate of learning for the core features, (2) learning phases of spurious features and core features are not always separable, (3) spurious features are not forgotten even after core features are fully learned. We show that our findings justify the success of retraining the last layer to remove spurious correlation and also identifies limitations of popular debiasing algorithms that exploit early learning of spurious features. We support our empirical findings with theoretical analyses for the case of learning XOR features with a one-hidden-layer ReLU network.
Deep Pairwise Learning To Rank For Search Autocomplete
Aug 11, 2021

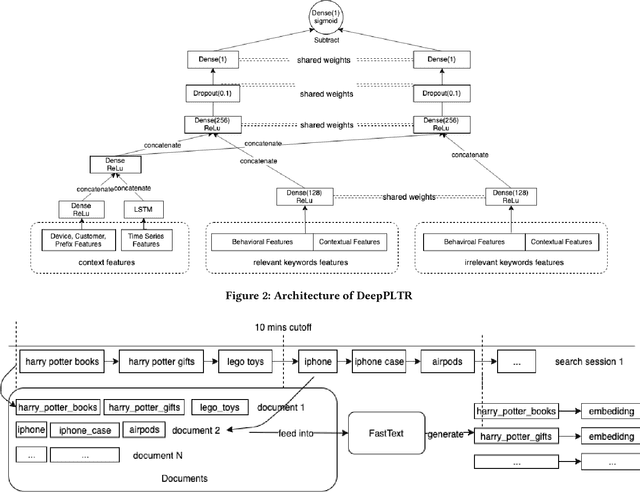
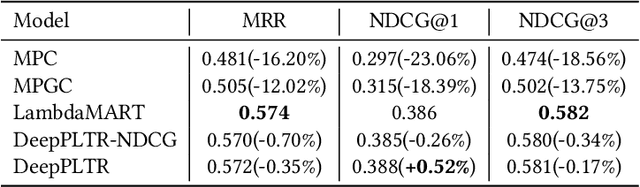
Autocomplete (a.k.a "Query Auto-Completion", "AC") suggests full queries based on a prefix typed by customer. Autocomplete has been a core feature of commercial search engine. In this paper, we propose a novel context-aware neural network based pairwise ranker (DeepPLTR) to improve AC ranking, DeepPLTR leverages contextual and behavioral features to rank queries by minimizing a pairwise loss, based on a fully-connected neural network structure. Compared to LambdaMART ranker, DeepPLTR shows +3.90% MeanReciprocalRank (MRR) lift in offline evaluation, and yielded +0.06% (p < 0.1) Gross Merchandise Value (GMV) lift in an Amazon's online A/B experiment.
Crime Topic Modeling
Aug 06, 2018
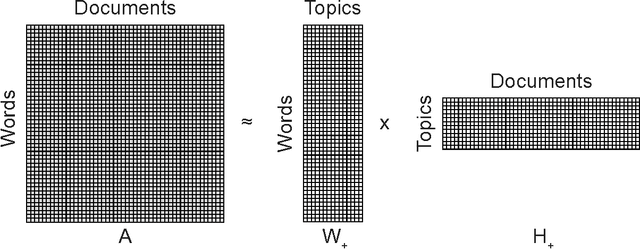
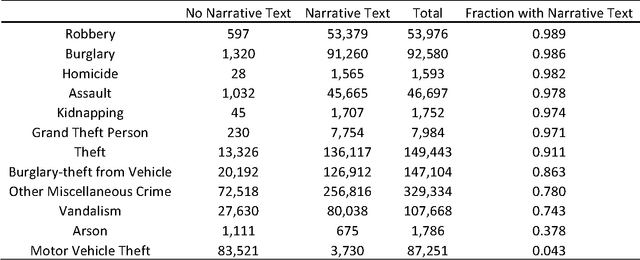
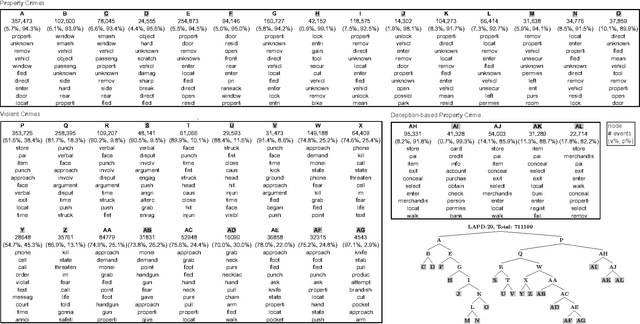
The classification of crime into discrete categories entails a massive loss of information. Crimes emerge out of a complex mix of behaviors and situations, yet most of these details cannot be captured by singular crime type labels. This information loss impacts our ability to not only understand the causes of crime, but also how to develop optimal crime prevention strategies. We apply machine learning methods to short narrative text descriptions accompanying crime records with the goal of discovering ecologically more meaningful latent crime classes. We term these latent classes "crime topics" in reference to text-based topic modeling methods that produce them. We use topic distributions to measure clustering among formally recognized crime types. Crime topics replicate broad distinctions between violent and property crime, but also reveal nuances linked to target characteristics, situational conditions and the tools and methods of attack. Formal crime types are not discrete in topic space. Rather, crime types are distributed across a range of crime topics. Similarly, individual crime topics are distributed across a range of formal crime types. Key ecological groups include identity theft, shoplifting, burglary and theft, car crimes and vandalism, criminal threats and confidence crimes, and violent crimes. Though not a replacement for formal legal crime classifications, crime topics provide a unique window into the heterogeneous causal processes underlying crime.
* 47 pages, 4 tables, 7 figures
Unsupervised Classification in Hyperspectral Imagery with Nonlocal Total Variation and Primal-Dual Hybrid Gradient Algorithm
Feb 13, 2017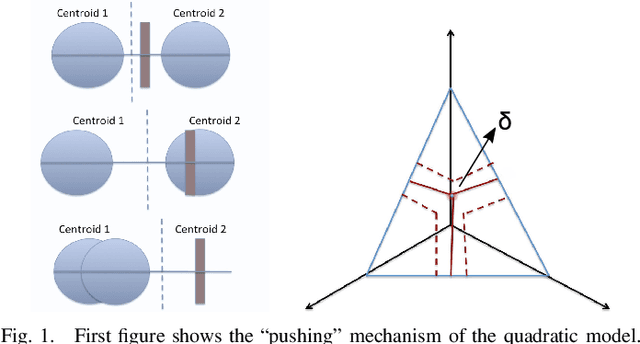
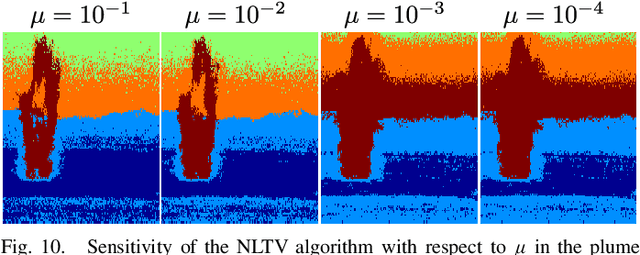
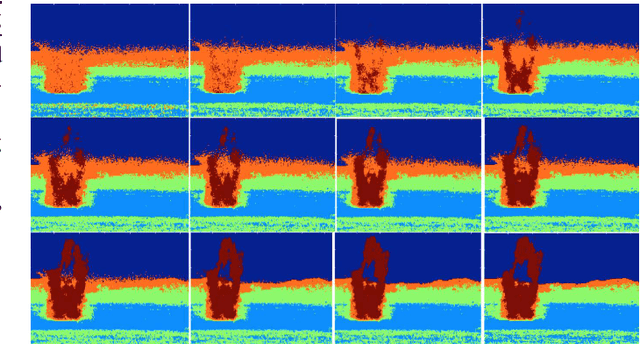

In this paper, a graph-based nonlocal total variation method (NLTV) is proposed for unsupervised classification of hyperspectral images (HSI). The variational problem is solved by the primal-dual hybrid gradient (PDHG) algorithm. By squaring the labeling function and using a stable simplex clustering routine, an unsupervised clustering method with random initialization can be implemented. The effectiveness of this proposed algorithm is illustrated on both synthetic and real-world HSI, and numerical results show that the proposed algorithm outperforms other standard unsupervised clustering methods such as spherical K-means, nonnegative matrix factorization (NMF), and the graph-based Merriman-Bence-Osher (MBO) scheme.
A Harmonic Extension Approach for Collaborative Ranking
Feb 16, 2016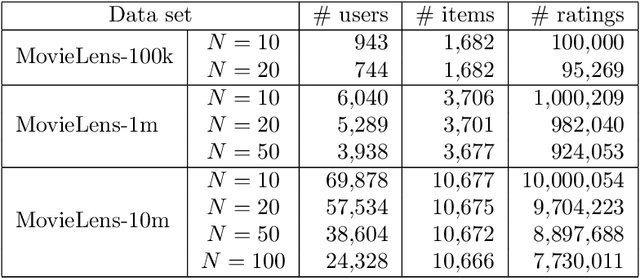
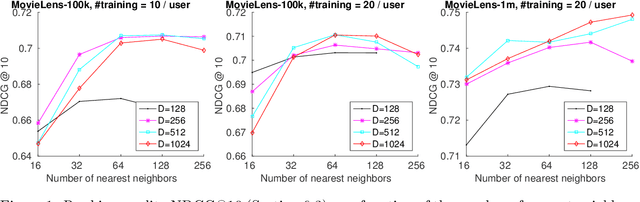
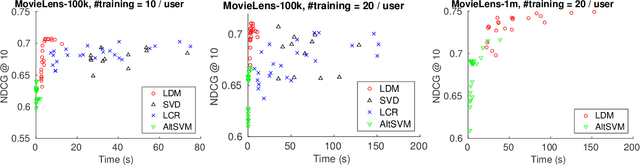

We present a new perspective on graph-based methods for collaborative ranking for recommender systems. Unlike user-based or item-based methods that compute a weighted average of ratings given by the nearest neighbors, or low-rank approximation methods using convex optimization and the nuclear norm, we formulate matrix completion as a series of semi-supervised learning problems, and propagate the known ratings to the missing ones on the user-user or item-item graph globally. The semi-supervised learning problems are expressed as Laplace-Beltrami equations on a manifold, or namely, harmonic extension, and can be discretized by a point integral method. We show that our approach does not impose a low-rank Euclidean subspace on the data points, but instead minimizes the dimension of the underlying manifold. Our method, named LDM (low dimensional manifold), turns out to be particularly effective in generating rankings of items, showing decent computational efficiency and robust ranking quality compared to state-of-the-art methods.
Fast Clustering and Topic Modeling Based on Rank-2 Nonnegative Matrix Factorization
Oct 02, 2015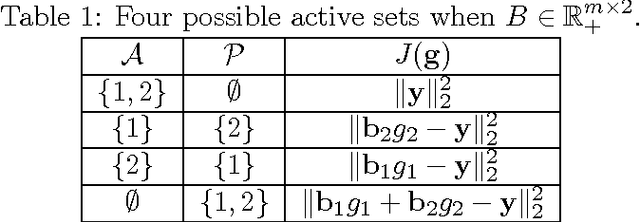
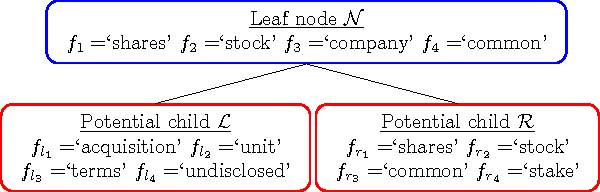

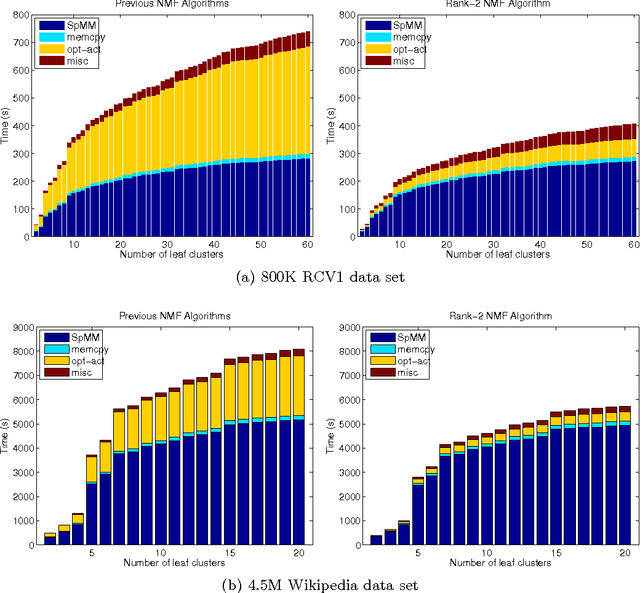
The importance of unsupervised clustering and topic modeling is well recognized with ever-increasing volumes of text data. In this paper, we propose a fast method for hierarchical clustering and topic modeling called HierNMF2. Our method is based on fast Rank-2 nonnegative matrix factorization (NMF) that performs binary clustering and an efficient node splitting rule. Further utilizing the final leaf nodes generated in HierNMF2 and the idea of nonnegative least squares fitting, we propose a new clustering/topic modeling method called FlatNMF2 that recovers a flat clustering/topic modeling result in a very simple yet significantly more effective way than any other existing methods. We implement highly optimized open source software in C++ for both HierNMF2 and FlatNMF2 for hierarchical and partitional clustering/topic modeling of document data sets. Substantial experimental tests are presented that illustrate significant improvements both in computational time as well as quality of solutions. We compare our methods to other clustering methods including K-means, standard NMF, and CLUTO, and also topic modeling methods including latent Dirichlet allocation (LDA) and recently proposed algorithms for NMF with separability constraints. Overall, we present efficient tools for analyzing large-scale data sets, and techniques that can be generalized to many other data analytics problem domains.
piCholesky: Polynomial Interpolation of Multiple Cholesky Factors for Efficient Approximate Cross-Validation
Jun 10, 2015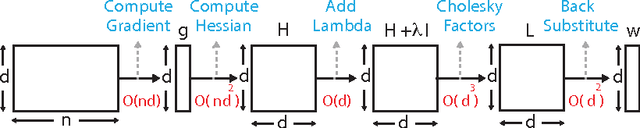


The dominant cost in solving least-square problems using Newton's method is often that of factorizing the Hessian matrix over multiple values of the regularization parameter ($\lambda$). We propose an efficient way to interpolate the Cholesky factors of the Hessian matrix computed over a small set of $\lambda$ values. This approximation enables us to optimally minimize the hold-out error while incurring only a fraction of the cost compared to exact cross-validation. We provide a formal error bound for our approximation scheme and present solutions to a set of key implementation challenges that allow our approach to maximally exploit the compute power of modern architectures. We present a thorough empirical analysis over multiple datasets to show the effectiveness of our approach.
Hierarchical Clustering of Hyperspectral Images using Rank-Two Nonnegative Matrix Factorization
Aug 19, 2014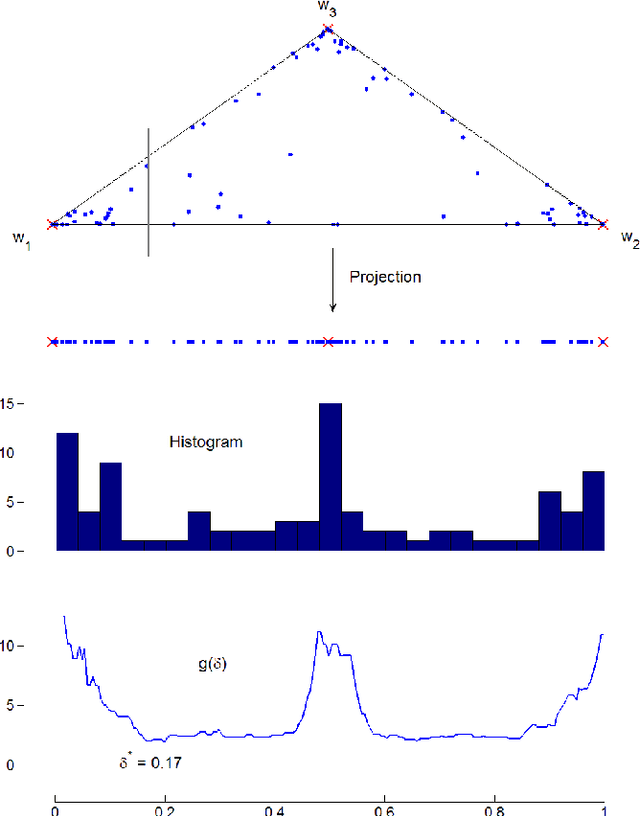

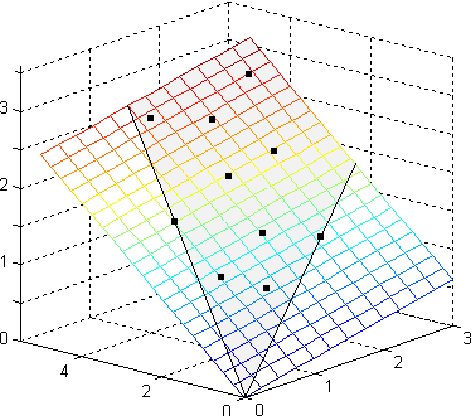
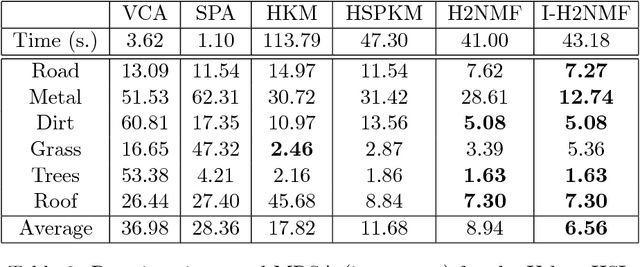
In this paper, we design a hierarchical clustering algorithm for high-resolution hyperspectral images. At the core of the algorithm, a new rank-two nonnegative matrix factorizations (NMF) algorithm is used to split the clusters, which is motivated by convex geometry concepts. The method starts with a single cluster containing all pixels, and, at each step, (i) selects a cluster in such a way that the error at the next step is minimized, and (ii) splits the selected cluster into two disjoint clusters using rank-two NMF in such a way that the clusters are well balanced and stable. The proposed method can also be used as an endmember extraction algorithm in the presence of pure pixels. The effectiveness of this approach is illustrated on several synthetic and real-world hyperspectral images, and shown to outperform standard clustering techniques such as k-means, spherical k-means and standard NMF.
* 29 pages, 19 figures. New experiment on Terrain data set. Accepted in IEEE Trans. Geosci. Remote Sens