 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInterveneBench: Benchmarking LLMs for Intervention Reasoning and Causal Study Design in Real Social Systems
Mar 16, 2026Causal inference in social science relies on end-to-end, intervention-centered research-design reasoning grounded in real-world policy interventions, but current benchmarks fail to evaluate this capability of large language models (LLMs). We present InterveneBench, a benchmark designed to assess such reasoning in realistic social settings. Each instance in InterveneBench is derived from an empirical social science study and requires models to reason about policy interventions and identification assumptions without access to predefined causal graphs or structural equations. InterveneBench comprises 744 peer-reviewed studies across diverse policy domains. Experimental results show that state-of-the-art LLMs struggle under this setting. To address this limitation, we further propose a multi-agent framework, STRIDES. It achieves significant performance improvements over state-of-the-art reasoning models. Our code and data are available at https://github.com/Sii-yuning/STRIDES.
Pangu Ultra MoE: How to Train Your Big MoE on Ascend NPUs
May 07, 2025



Sparse large language models (LLMs) with Mixture of Experts (MoE) and close to a trillion parameters are dominating the realm of most capable language models. However, the massive model scale poses significant challenges for the underlying software and hardware systems. In this paper, we aim to uncover a recipe to harness such scale on Ascend NPUs. The key goals are better usage of the computing resources under the dynamic sparse model structures and materializing the expected performance gain on the actual hardware. To select model configurations suitable for Ascend NPUs without repeatedly running the expensive experiments, we leverage simulation to compare the trade-off of various model hyperparameters. This study led to Pangu Ultra MoE, a sparse LLM with 718 billion parameters, and we conducted experiments on the model to verify the simulation results. On the system side, we dig into Expert Parallelism to optimize the communication between NPU devices to reduce the synchronization overhead. We also optimize the memory efficiency within the devices to further reduce the parameter and activation management overhead. In the end, we achieve an MFU of 30.0% when training Pangu Ultra MoE, with performance comparable to that of DeepSeek R1, on 6K Ascend NPUs, and demonstrate that the Ascend system is capable of harnessing all the training stages of the state-of-the-art language models. Extensive experiments indicate that our recipe can lead to efficient training of large-scale sparse language models with MoE. We also study the behaviors of such models for future reference.
Pangu Ultra: Pushing the Limits of Dense Large Language Models on Ascend NPUs
Apr 10, 2025



We present Pangu Ultra, a Large Language Model (LLM) with 135 billion parameters and dense Transformer modules trained on Ascend Neural Processing Units (NPUs). Although the field of LLM has been witnessing unprecedented advances in pushing the scale and capability of LLM in recent years, training such a large-scale model still involves significant optimization and system challenges. To stabilize the training process, we propose depth-scaled sandwich normalization, which effectively eliminates loss spikes during the training process of deep models. We pre-train our model on 13.2 trillion diverse and high-quality tokens and further enhance its reasoning capabilities during post-training. To perform such large-scale training efficiently, we utilize 8,192 Ascend NPUs with a series of system optimizations. Evaluations on multiple diverse benchmarks indicate that Pangu Ultra significantly advances the state-of-the-art capabilities of dense LLMs such as Llama 405B and Mistral Large 2, and even achieves competitive results with DeepSeek-R1, whose sparse model structure contains much more parameters. Our exploration demonstrates that Ascend NPUs are capable of efficiently and effectively training dense models with more than 100 billion parameters. Our model and system will be available for our commercial customers.
Fundamental Limits of Communication Efficiency for Model Aggregation in Distributed Learning: A Rate-Distortion Approach
Jun 28, 2022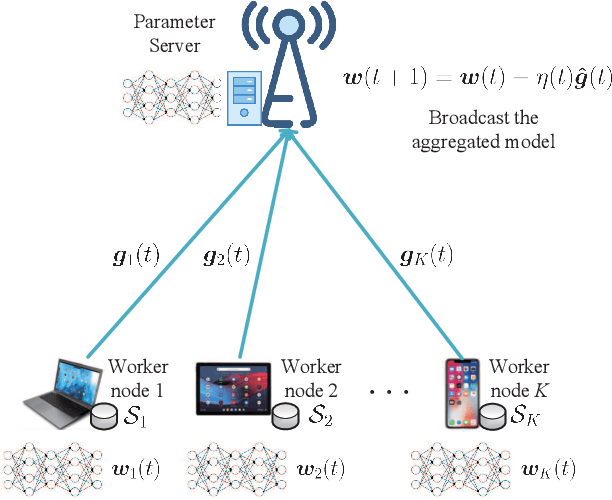
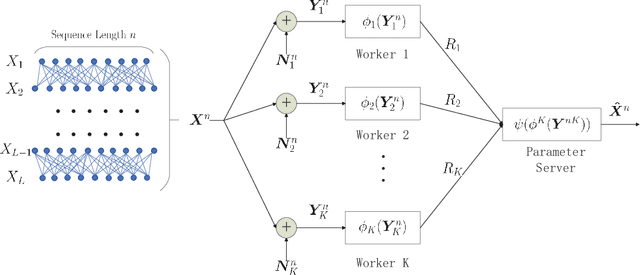
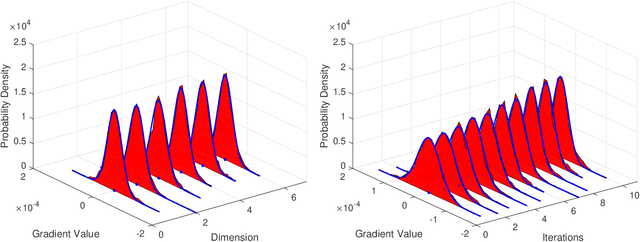
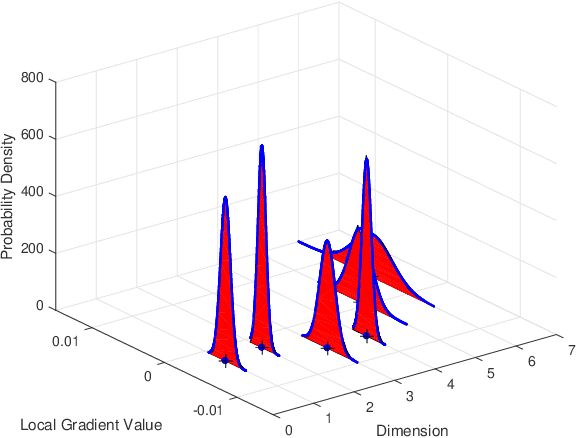
One of the main focuses in distributed learning is communication efficiency, since model aggregation at each round of training can consist of millions to billions of parameters. Several model compression methods, such as gradient quantization and sparsification, have been proposed to improve the communication efficiency of model aggregation. However, the information-theoretic minimum communication cost for a given distortion of gradient estimators is still unknown. In this paper, we study the fundamental limit of communication cost of model aggregation in distributed learning from a rate-distortion perspective. By formulating the model aggregation as a vector Gaussian CEO problem, we derive the rate region bound and sum-rate-distortion function for the model aggregation problem, which reveals the minimum communication rate at a particular gradient distortion upper bound. We also analyze the communication cost at each iteration and total communication cost based on the sum-rate-distortion function with the gradient statistics of real-world datasets. It is found that the communication gain by exploiting the correlation between worker nodes is significant for SignSGD, and a high distortion of gradient estimator can achieve low total communication cost in gradient compression.
Rate Region for Indirect Multiterminal Source Coding in Federated Learning
Jan 26, 2021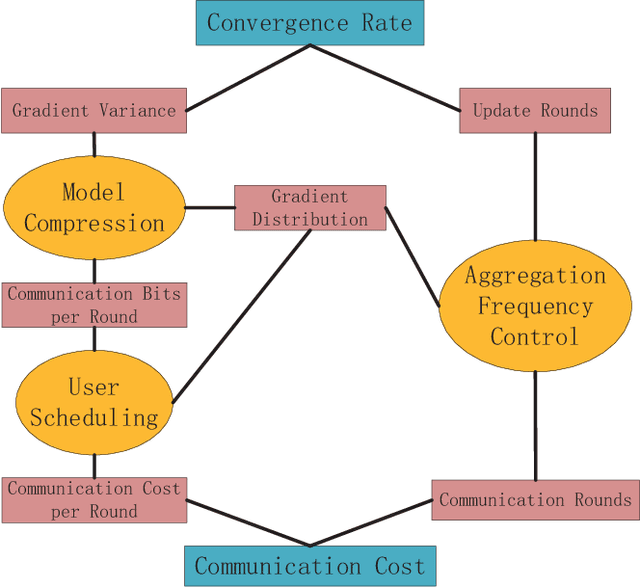
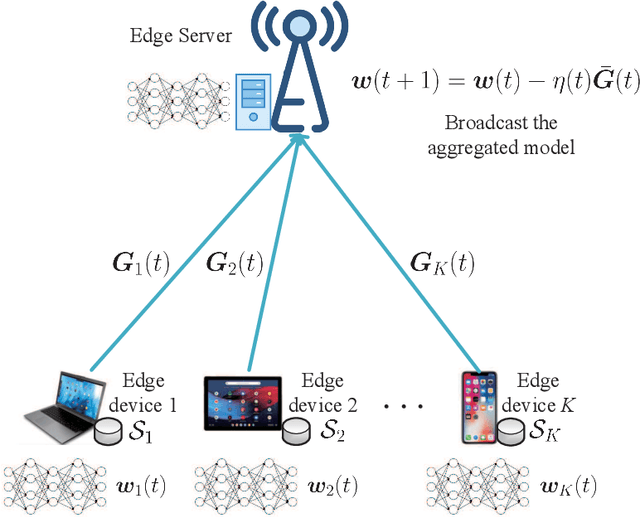
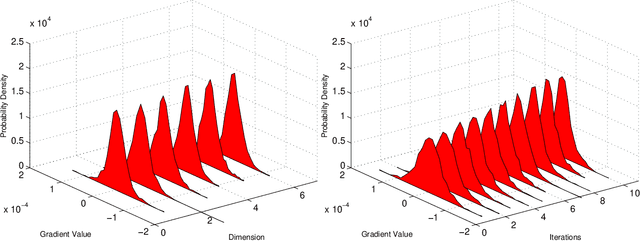
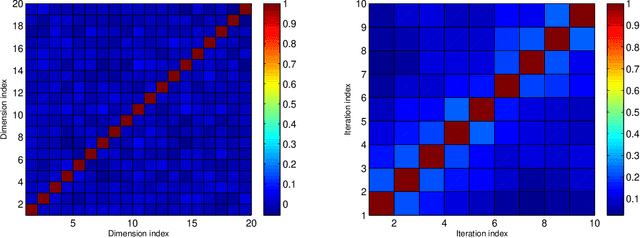
One of the main focus in federated learning (FL) is the communication efficiency since a large number of participating edge devices send their updates to the edge server at each round of the model training. Existing works reconstruct each model update from edge devices and implicitly assume that the local model updates are independent over edge device. In FL, however, the model update is an indirect multi-terminal source coding problem where each edge device cannot observe directly the source that is to be reconstructed at the decoder, but is rather provided only with a noisy version. The existing works do not leverage the redundancy in the information transmitted by different edges. This paper studies the rate region for the indirect multiterminal source coding problem in FL. The goal is to obtain the minimum achievable rate at a particular upper bound of gradient variance. We obtain the rate region for multiple edge devices in general case and derive an explicit formula of the sum-rate distortion function in the special case where gradient are identical over edge device and dimension. Finally, we analysis communication efficiency of convex Mini-batched SGD and non-convex Minibatched SGD based on the sum-rate distortion function, respectively.
Extended Radial Basis Function Controller for Reinforcement Learning
Sep 12, 2020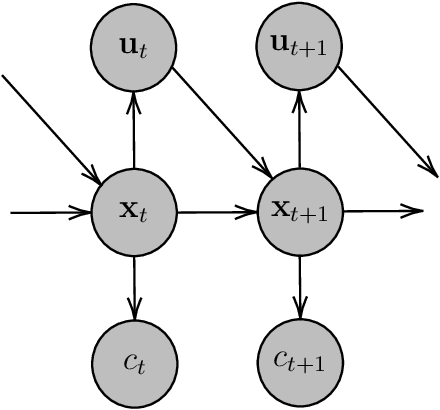


There have been attempts in model-based reinforcement learning to exploit a priori knowledge about the structure of the system. This paper introduces the extended radial basis function (RBF) controller design. In addition to traditional RBF controllers, our controller comprises of an engineered linear controller inside an operating region. We show that the learnt extended RBF controller takes on the desirable characteristics of both the linear and non-linear controller models. The extended controller is shown to retain the ability for universal function approximation of the non-linear RBF functions. At the same time, it demonstrates desirable stability criteria on par with the linear controller. Learning has been done in a probabilistic inference framework (PILCO), but could generalise to other reinforcement learning frameworks. Experimental results from the Swing-up pendulum, Cartpole, and Mountain car environments are reported.
MQA: Answering the Question via Robotic Manipulation
Mar 10, 2020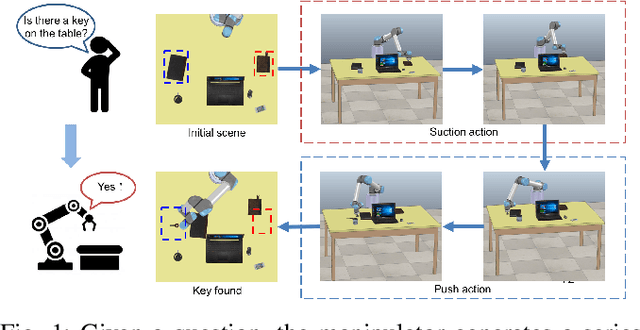
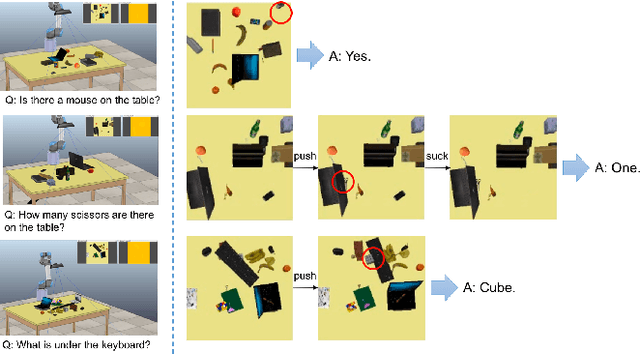
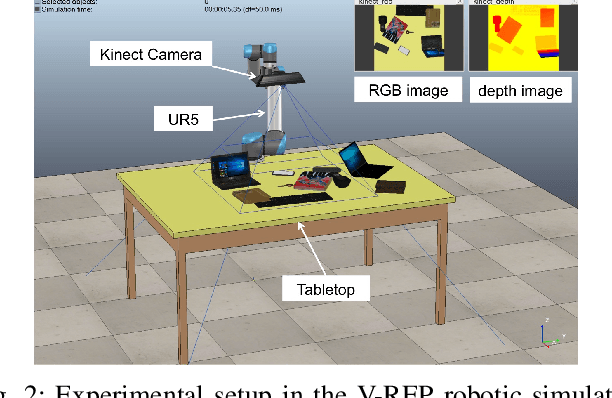
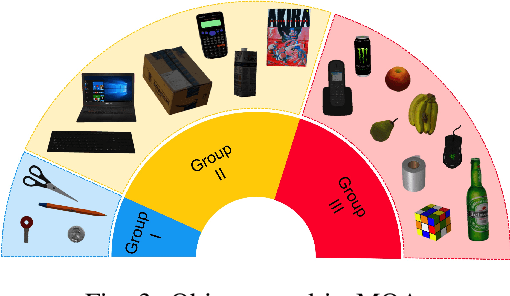
In this paper,we propose a novel task of Manipulation Question Answering(MQA),a class of Question Answering (QA) task, where the robot is required to find the answer to the question by actively interacting with the environment via manipulation. Considering the tabletop scenario, a heatmap of the scene is generated to facilitate the robot to have a semantic understanding of the scene and an imitation learning approach with semantic understanding metric is proposed to generate manipulation actions which guide the manipulator to explore the tabletop to find the answer to the question. Besides, a novel dataset which contains a variety of tabletop scenarios and corresponding question-answer pairs is established. Extensive experiments have been conducted to validate the effectiveness of the proposed framework.
Gradient Statistics Aware Power Control for Over-the-Air Federated Learning in Fading Channels
Mar 04, 2020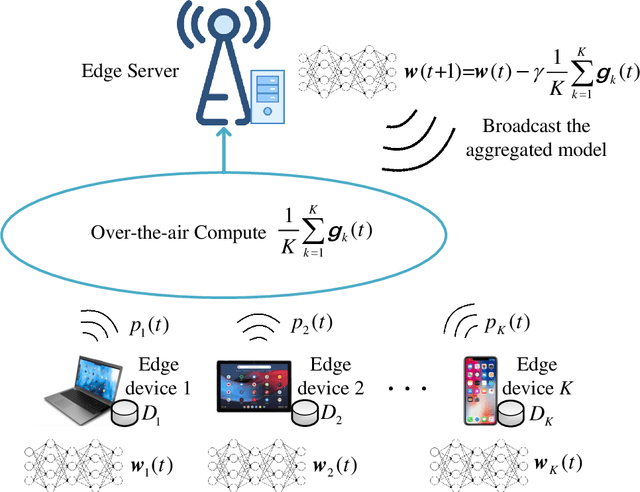



To enable communication-efficient federated learning, fast model aggregation can be designed using over-the-air computation (AirComp). In order to implement a reliable and high-performance AirComp over fading channels, power control at edge devices is crucial. Existing works focus on the traditional data aggregation which often assumes that the local data collected at different devices are identically distributed and can be normalized with zero mean and unit variance. This assumption, however, does not hold for gradient aggregation in machine learning. In this paper, we study the optimal power control problem for efficient over-the-air FL by taking gradient statistics into account. Our goal is to minimize the model aggregation error measured by mean square error (MSE) by jointly optimizing the transmit power of each device and the denoising factor at the edge server. We first derive the optimal solution in closed form where the gradient first-order and second-order statistics are known. The derived optimal power control structure depends on multivariate coefficient of variation of gradient. We then propose a method to estimate the gradient statistics based on the historical aggregated gradients and then dynamically adjust the transmit power on devices over each training iteration. Experiment results show that our proposed power control is better than full power transmission and threshold-based power control in both model accuracy and convergence rate.