 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLoopMoE: Unifying Iterative Computation with Mixture-of-Experts for Language Modeling
Jun 03, 2026Mixture-of-Experts (MoE) and looped architectures scale models along two orthogonal axes, namely parameter capacity and effective depth. However, mainstream looped architectures rely on dense backbones that couple parameter count with per-token FLOPs, which makes it impossible to isolate the effect of iterative computation under matched budgets. To this end, we present LoopMoE, a looped MoE language model that integrates sparse routing with iterative weight-shared computation through two designs. The first is IterAdaLN, which resolves weight-sharing symmetry via a modulation signal jointly conditioned on the iteration index and the per-token hidden state. The second is a capacity-balancing strategy that recovers the attention-to-FFN active parameter ratio of well-tuned non-looped references. Together, these designs enable the first strictly controlled, head-to-head evaluation of a looped MoE against a Vanilla MoE under identical total parameters, per-token FLOPs, and active sublayer ratios. At the 3B scale, LoopMoE outperforms the Vanilla MoE on 8 of 9 downstream benchmarks with an average improvement exceeding 1 point. At the 9B scale, LoopMoE continues to outperform the matched Vanilla MoE, indicating that the architectural gain persists at larger scale. Our work establishes a controlled synthesis of sparsity and recurrence, and suggests a promising direction for looped language models.
UniPool: A Globally Shared Expert Pool for Mixture-of-Experts
May 07, 2026Modern Mixture-of-Experts (MoE) architectures allocate expert capacity through a rigid per-layer rule: each transformer layer owns a separate expert set. This convention couples depth scaling with linear expert-parameter growth and assumes that every layer needs isolated expert capacity. However, recent analyses and our routing probe challenge this allocation rule: replacing a deeper layer's learned top-k router with uniform random routing drops downstream accuracy by only 1.0-1.6 points across multiple production MoE models. Motivated by this redundancy, we propose UniPool, an MoE architecture that treats expert capacity as a global architectural budget by replacing per-layer expert ownership with a single shared pool accessed by independent per-layer routers. To enable stable and balanced training under sharing, we introduce a pool-level auxiliary loss that balances expert utilization across the entire pool, and adopt NormRouter to provide sparse and scale-stable routing into the shared expert pool. Across five LLaMA-architecture model scales (182M, 469M, 650M, 830M, and 978M parameters) trained on 30B tokens from the Pile, UniPool consistently improves validation loss and perplexity over the matched vanilla MoE baselines. Across these scales, UniPool reduces validation loss by up to 0.0386 relative to vanilla MoE. Beyond raw loss improvement, our results identify pool size as an explicit depth-scaling hyperparameter: reduced-pool UniPool variants using only 41.6%-66.7% of the vanilla expert-parameter budget match or outperform layer-wise MoE at the tested scales. This shows that, under a shared-pool design, expert parameters need not grow linearly with depth; they can grow sublinearly while remaining more efficient and effective than vanilla MoE. Further analysis shows that UniPool's benefits compose with finer-grained expert decomposition.
Switch Attention: Towards Dynamic and Fine-grained Hybrid Transformers
Mar 27, 2026The attention mechanism has been the core component in modern transformer architectures. However, the computation of standard full attention scales quadratically with the sequence length, serving as a major bottleneck in long-context language modeling. Sliding window attention restricts the context length for better efficiency at the cost of narrower receptive fields. While existing efforts attempt to take the benefits from both sides by building hybrid models, they often resort to static, heuristically designed alternating patterns that limit efficient allocation of computation in various scenarios. In this paper, we propose Switch Attention (SwiAttn), a novel hybrid transformer that enables dynamic and fine-grained routing between full attention and sliding window attention. For each token at each transformer layer, SwiAttn dynamically routes the computation to either a full-attention branch for global information aggregation or a sliding-window branch for efficient local pattern matching. An adaptive regularization objective is designed to encourage the model towards efficiency. Moreover, we adopt continual pretraining to optimize the model, transferring the full attention architecture to the hybrid one. Extensive experiments are conducted on twenty-three benchmark datasets across both regular (4K) and long (32K) context lengths, demonstrating the effectiveness of the proposed method.
Safe: Enhancing Mathematical Reasoning in Large Language Models via Retrospective Step-aware Formal Verification
Jun 05, 2025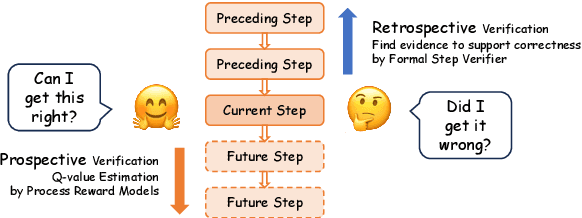



Chain-of-Thought (CoT) prompting has become the de facto method to elicit reasoning capabilities from large language models (LLMs). However, to mitigate hallucinations in CoT that are notoriously difficult to detect, current methods such as process reward models (PRMs) or self-consistency operate as opaque boxes and do not provide checkable evidence for their judgments, possibly limiting their effectiveness. To address this issue, we draw inspiration from the idea that "the gold standard for supporting a mathematical claim is to provide a proof". We propose a retrospective, step-aware formal verification framework $Safe$. Rather than assigning arbitrary scores, we strive to articulate mathematical claims in formal mathematical language Lean 4 at each reasoning step and provide formal proofs to identify hallucinations. We evaluate our framework $Safe$ across multiple language models and various mathematical datasets, demonstrating a significant performance improvement while offering interpretable and verifiable evidence. We also propose $FormalStep$ as a benchmark for step correctness theorem proving with $30,809$ formal statements. To the best of our knowledge, our work represents the first endeavor to utilize formal mathematical language Lean 4 for verifying natural language content generated by LLMs, aligning with the reason why formal mathematical languages were created in the first place: to provide a robust foundation for hallucination-prone human-written proofs.
Pangu Light: Weight Re-Initialization for Pruning and Accelerating LLMs
May 26, 2025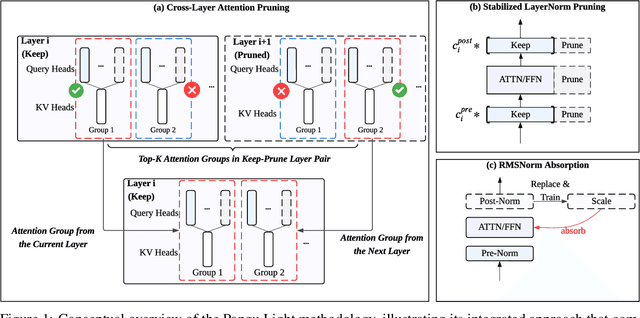

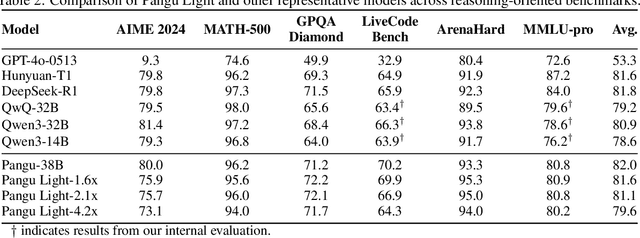
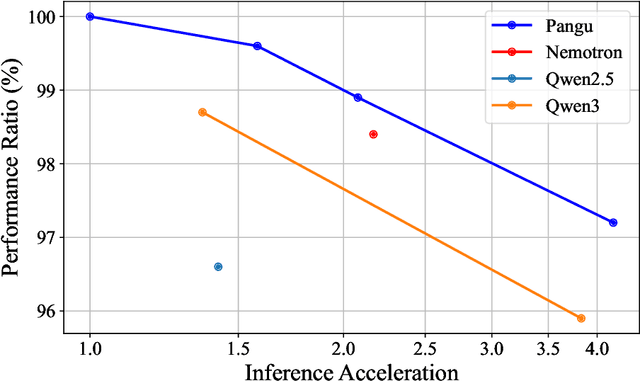
Large Language Models (LLMs) deliver state-of-the-art capabilities across numerous tasks, but their immense size and inference costs pose significant computational challenges for practical deployment. While structured pruning offers a promising avenue for model compression, existing methods often struggle with the detrimental effects of aggressive, simultaneous width and depth reductions, leading to substantial performance degradation. This paper argues that a critical, often overlooked, aspect in making such aggressive joint pruning viable is the strategic re-initialization and adjustment of remaining weights to improve the model post-pruning training accuracies. We introduce Pangu Light, a framework for LLM acceleration centered around structured pruning coupled with novel weight re-initialization techniques designed to address this ``missing piece''. Our framework systematically targets multiple axes, including model width, depth, attention heads, and RMSNorm, with its effectiveness rooted in novel re-initialization methods like Cross-Layer Attention Pruning (CLAP) and Stabilized LayerNorm Pruning (SLNP) that mitigate performance drops by providing the network a better training starting point. Further enhancing efficiency, Pangu Light incorporates specialized optimizations such as absorbing Post-RMSNorm computations and tailors its strategies to Ascend NPU characteristics. The Pangu Light models consistently exhibit a superior accuracy-efficiency trade-off, outperforming prominent baseline pruning methods like Nemotron and established LLMs like Qwen3 series. For instance, on Ascend NPUs, Pangu Light-32B's 81.6 average score and 2585 tokens/s throughput exceed Qwen3-32B's 80.9 average score and 2225 tokens/s.
Pangu Ultra MoE: How to Train Your Big MoE on Ascend NPUs
May 07, 2025



Sparse large language models (LLMs) with Mixture of Experts (MoE) and close to a trillion parameters are dominating the realm of most capable language models. However, the massive model scale poses significant challenges for the underlying software and hardware systems. In this paper, we aim to uncover a recipe to harness such scale on Ascend NPUs. The key goals are better usage of the computing resources under the dynamic sparse model structures and materializing the expected performance gain on the actual hardware. To select model configurations suitable for Ascend NPUs without repeatedly running the expensive experiments, we leverage simulation to compare the trade-off of various model hyperparameters. This study led to Pangu Ultra MoE, a sparse LLM with 718 billion parameters, and we conducted experiments on the model to verify the simulation results. On the system side, we dig into Expert Parallelism to optimize the communication between NPU devices to reduce the synchronization overhead. We also optimize the memory efficiency within the devices to further reduce the parameter and activation management overhead. In the end, we achieve an MFU of 30.0% when training Pangu Ultra MoE, with performance comparable to that of DeepSeek R1, on 6K Ascend NPUs, and demonstrate that the Ascend system is capable of harnessing all the training stages of the state-of-the-art language models. Extensive experiments indicate that our recipe can lead to efficient training of large-scale sparse language models with MoE. We also study the behaviors of such models for future reference.
Pangu Ultra: Pushing the Limits of Dense Large Language Models on Ascend NPUs
Apr 10, 2025



We present Pangu Ultra, a Large Language Model (LLM) with 135 billion parameters and dense Transformer modules trained on Ascend Neural Processing Units (NPUs). Although the field of LLM has been witnessing unprecedented advances in pushing the scale and capability of LLM in recent years, training such a large-scale model still involves significant optimization and system challenges. To stabilize the training process, we propose depth-scaled sandwich normalization, which effectively eliminates loss spikes during the training process of deep models. We pre-train our model on 13.2 trillion diverse and high-quality tokens and further enhance its reasoning capabilities during post-training. To perform such large-scale training efficiently, we utilize 8,192 Ascend NPUs with a series of system optimizations. Evaluations on multiple diverse benchmarks indicate that Pangu Ultra significantly advances the state-of-the-art capabilities of dense LLMs such as Llama 405B and Mistral Large 2, and even achieves competitive results with DeepSeek-R1, whose sparse model structure contains much more parameters. Our exploration demonstrates that Ascend NPUs are capable of efficiently and effectively training dense models with more than 100 billion parameters. Our model and system will be available for our commercial customers.
Teaching LLMs According to Their Aptitude: Adaptive Reasoning for Mathematical Problem Solving
Feb 17, 2025



Existing approaches to mathematical reasoning with large language models (LLMs) rely on Chain-of-Thought (CoT) for generalizability or Tool-Integrated Reasoning (TIR) for precise computation. While efforts have been made to combine these methods, they primarily rely on post-selection or predefined strategies, leaving an open question: whether LLMs can autonomously adapt their reasoning strategy based on their inherent capabilities. In this work, we propose TATA (Teaching LLMs According to Their Aptitude), an adaptive framework that enables LLMs to personalize their reasoning strategy spontaneously, aligning it with their intrinsic aptitude. TATA incorporates base-LLM-aware data selection during supervised fine-tuning (SFT) to tailor training data to the model's unique abilities. This approach equips LLMs to autonomously determine and apply the appropriate reasoning strategy at test time. We evaluate TATA through extensive experiments on six mathematical reasoning benchmarks, using both general-purpose and math-specialized LLMs. Empirical results demonstrate that TATA effectively combines the complementary strengths of CoT and TIR, achieving superior or comparable performance with improved inference efficiency compared to TIR alone. Further analysis underscores the critical role of aptitude-aware data selection in enabling LLMs to make effective and adaptive reasoning decisions and align reasoning strategies with model capabilities.
CoIR: A Comprehensive Benchmark for Code Information Retrieval Models
Jul 03, 2024



Despite the substantial success of Information Retrieval (IR) in various NLP tasks, most IR systems predominantly handle queries and corpora in natural language, neglecting the domain of code retrieval. Code retrieval is critically important yet remains under-explored, with existing methods and benchmarks inadequately representing the diversity of code in various domains and tasks. Addressing this gap, we present \textbf{\name} (\textbf{Co}de \textbf{I}nformation \textbf{R}etrieval Benchmark), a robust and comprehensive benchmark specifically designed to assess code retrieval capabilities. \name comprises \textbf{ten} meticulously curated code datasets, spanning \textbf{eight} distinctive retrieval tasks across \textbf{seven} diverse domains. We first discuss the construction of \name and its diverse dataset composition. Further, we evaluate nine widely used retrieval models using \name, uncovering significant difficulties in performing code retrieval tasks even with state-of-the-art systems. To facilitate easy adoption and integration within existing research workflows, \name has been developed as a user-friendly Python framework, readily installable via pip. It shares same data schema as other popular benchmarks like MTEB and BEIR, enabling seamless cross-benchmark evaluations. Through \name, we aim to invigorate research in the code retrieval domain, providing a versatile benchmarking tool that encourages further development and exploration of code retrieval systems\footnote{\url{ https://github.com/CoIR-team/coir}}.
Preparing Lessons for Progressive Training on Language Models
Jan 18, 2024



The rapid progress of Transformers in artificial intelligence has come at the cost of increased resource consumption and greenhouse gas emissions due to growing model sizes. Prior work suggests using pretrained small models to improve training efficiency, but this approach may not be suitable for new model structures. On the other hand, training from scratch can be slow, and progressively stacking layers often fails to achieve significant acceleration. To address these challenges, we propose a novel method called Apollo, which prep\textbf{a}res lessons for ex\textbf{p}anding \textbf{o}perations by \textbf{l}earning high-\textbf{l}ayer functi\textbf{o}nality during training of low layers. Our approach involves low-value-prioritized sampling (LVPS) to train different depths and weight sharing to facilitate efficient expansion. We also introduce an interpolation method for stable model depth extension. Experiments demonstrate that Apollo achieves state-of-the-art acceleration ratios, even rivaling methods using pretrained models, making it a universal and efficient solution for training deep models while reducing time, financial, and environmental costs.