 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReMiT: RL-Guided Mid-Training for Iterative LLM Evolution
Feb 03, 2026Standard training pipelines for large language models (LLMs) are typically unidirectional, progressing from pre-training to post-training. However, the potential for a bidirectional process--where insights from post-training retroactively improve the pre-trained foundation--remains unexplored. We aim to establish a self-reinforcing flywheel: a cycle in which reinforcement learning (RL)-tuned model strengthens the base model, which in turn enhances subsequent post-training performance, requiring no specially trained teacher or reference model. To realize this, we analyze training dynamics and identify the mid-training (annealing) phase as a critical turning point for model capabilities. This phase typically occurs at the end of pre-training, utilizing high-quality corpora under a rapidly decaying learning rate. Building upon this insight, we introduce ReMiT (Reinforcement Learning-Guided Mid-Training). Specifically, ReMiT leverages the reasoning priors of RL-tuned models to dynamically reweight tokens during the mid-training phase, prioritizing those pivotal for reasoning. Empirically, ReMiT achieves an average improvement of 3\% on 10 pre-training benchmarks, spanning math, code, and general reasoning, and sustains these gains by over 2\% throughout the post-training pipeline. These results validate an iterative feedback loop, enabling continuous and self-reinforcing evolution of LLMs.
Youtu-VL: Unleashing Visual Potential via Unified Vision-Language Supervision
Jan 27, 2026Despite the significant advancements represented by Vision-Language Models (VLMs), current architectures often exhibit limitations in retaining fine-grained visual information, leading to coarse-grained multimodal comprehension. We attribute this deficiency to a suboptimal training paradigm inherent in prevailing VLMs, which exhibits a text-dominant optimization bias by conceptualizing visual signals merely as passive conditional inputs rather than supervisory targets. To mitigate this, we introduce Youtu-VL, a framework leveraging the Vision-Language Unified Autoregressive Supervision (VLUAS) paradigm, which fundamentally shifts the optimization objective from ``vision-as-input'' to ``vision-as-target.'' By integrating visual tokens directly into the prediction stream, Youtu-VL applies unified autoregressive supervision to both visual details and linguistic content. Furthermore, we extend this paradigm to encompass vision-centric tasks, enabling a standard VLM to perform vision-centric tasks without task-specific additions. Extensive empirical evaluations demonstrate that Youtu-VL achieves competitive performance on both general multimodal tasks and vision-centric tasks, establishing a robust foundation for the development of comprehensive generalist visual agents.
Youtu-LLM: Unlocking the Native Agentic Potential for Lightweight Large Language Models
Dec 31, 2025We introduce Youtu-LLM, a lightweight yet powerful language model that harmonizes high computational efficiency with native agentic intelligence. Unlike typical small models that rely on distillation, Youtu-LLM (1.96B) is pre-trained from scratch to systematically cultivate reasoning and planning capabilities. The key technical advancements are as follows: (1) Compact Architecture with Long-Context Support: Built on a dense Multi-Latent Attention (MLA) architecture with a novel STEM-oriented vocabulary, Youtu-LLM supports a 128k context window. This design enables robust long-context reasoning and state tracking within a minimal memory footprint, making it ideal for long-horizon agent and reasoning tasks. (2) Principled "Commonsense-STEM-Agent" Curriculum: We curated a massive corpus of approximately 11T tokens and implemented a multi-stage training strategy. By progressively shifting the pre-training data distribution from general commonsense to complex STEM and agentic tasks, we ensure the model acquires deep cognitive abilities rather than superficial alignment. (3) Scalable Agentic Mid-training: Specifically for the agentic mid-training, we employ diverse data construction schemes to synthesize rich and varied trajectories across math, coding, and tool-use domains. This high-quality data enables the model to internalize planning and reflection behaviors effectively. Extensive evaluations show that Youtu-LLM sets a new state-of-the-art for sub-2B LLMs. On general benchmarks, it achieves competitive performance against larger models, while on agent-specific tasks, it significantly surpasses existing SOTA baselines, demonstrating that lightweight models can possess strong intrinsic agentic capabilities.
Pangu Light: Weight Re-Initialization for Pruning and Accelerating LLMs
May 26, 2025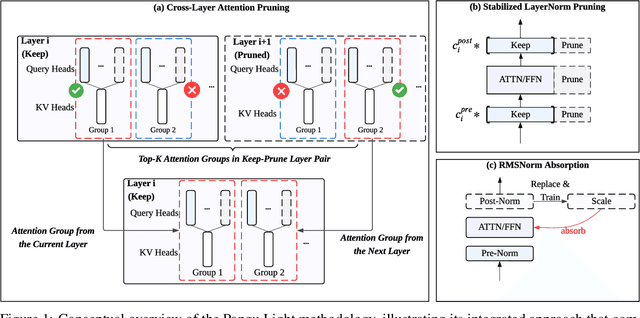

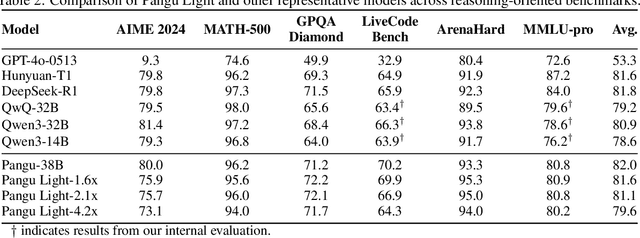
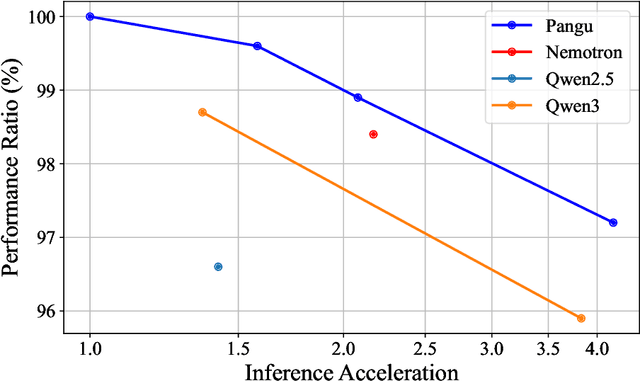
Large Language Models (LLMs) deliver state-of-the-art capabilities across numerous tasks, but their immense size and inference costs pose significant computational challenges for practical deployment. While structured pruning offers a promising avenue for model compression, existing methods often struggle with the detrimental effects of aggressive, simultaneous width and depth reductions, leading to substantial performance degradation. This paper argues that a critical, often overlooked, aspect in making such aggressive joint pruning viable is the strategic re-initialization and adjustment of remaining weights to improve the model post-pruning training accuracies. We introduce Pangu Light, a framework for LLM acceleration centered around structured pruning coupled with novel weight re-initialization techniques designed to address this ``missing piece''. Our framework systematically targets multiple axes, including model width, depth, attention heads, and RMSNorm, with its effectiveness rooted in novel re-initialization methods like Cross-Layer Attention Pruning (CLAP) and Stabilized LayerNorm Pruning (SLNP) that mitigate performance drops by providing the network a better training starting point. Further enhancing efficiency, Pangu Light incorporates specialized optimizations such as absorbing Post-RMSNorm computations and tailors its strategies to Ascend NPU characteristics. The Pangu Light models consistently exhibit a superior accuracy-efficiency trade-off, outperforming prominent baseline pruning methods like Nemotron and established LLMs like Qwen3 series. For instance, on Ascend NPUs, Pangu Light-32B's 81.6 average score and 2585 tokens/s throughput exceed Qwen3-32B's 80.9 average score and 2225 tokens/s.
The Real Barrier to LLM Agent Usability is Agentic ROI
May 23, 2025Large Language Model (LLM) agents represent a promising shift in human-AI interaction, moving beyond passive prompt-response systems to autonomous agents capable of reasoning, planning, and goal-directed action. Despite the widespread application in specialized, high-effort tasks like coding and scientific research, we highlight a critical usability gap in high-demand, mass-market applications. This position paper argues that the limited real-world adoption of LLM agents stems not only from gaps in model capabilities, but also from a fundamental tradeoff between the value an agent can provide and the costs incurred during real-world use. Hence, we call for a shift from solely optimizing model performance to a broader, utility-driven perspective: evaluating agents through the lens of the overall agentic return on investment (Agent ROI). By identifying key factors that determine Agentic ROI--information quality, agent time, and cost--we posit a zigzag development trajectory in optimizing agentic ROI: first scaling up to improve the information quality, then scaling down to minimize the time and cost. We outline the roadmap across different development stages to bridge the current usability gaps, aiming to make LLM agents truly scalable, accessible, and effective in real-world contexts.
Pangu Ultra MoE: How to Train Your Big MoE on Ascend NPUs
May 07, 2025



Sparse large language models (LLMs) with Mixture of Experts (MoE) and close to a trillion parameters are dominating the realm of most capable language models. However, the massive model scale poses significant challenges for the underlying software and hardware systems. In this paper, we aim to uncover a recipe to harness such scale on Ascend NPUs. The key goals are better usage of the computing resources under the dynamic sparse model structures and materializing the expected performance gain on the actual hardware. To select model configurations suitable for Ascend NPUs without repeatedly running the expensive experiments, we leverage simulation to compare the trade-off of various model hyperparameters. This study led to Pangu Ultra MoE, a sparse LLM with 718 billion parameters, and we conducted experiments on the model to verify the simulation results. On the system side, we dig into Expert Parallelism to optimize the communication between NPU devices to reduce the synchronization overhead. We also optimize the memory efficiency within the devices to further reduce the parameter and activation management overhead. In the end, we achieve an MFU of 30.0% when training Pangu Ultra MoE, with performance comparable to that of DeepSeek R1, on 6K Ascend NPUs, and demonstrate that the Ascend system is capable of harnessing all the training stages of the state-of-the-art language models. Extensive experiments indicate that our recipe can lead to efficient training of large-scale sparse language models with MoE. We also study the behaviors of such models for future reference.
Pangu Ultra: Pushing the Limits of Dense Large Language Models on Ascend NPUs
Apr 10, 2025



We present Pangu Ultra, a Large Language Model (LLM) with 135 billion parameters and dense Transformer modules trained on Ascend Neural Processing Units (NPUs). Although the field of LLM has been witnessing unprecedented advances in pushing the scale and capability of LLM in recent years, training such a large-scale model still involves significant optimization and system challenges. To stabilize the training process, we propose depth-scaled sandwich normalization, which effectively eliminates loss spikes during the training process of deep models. We pre-train our model on 13.2 trillion diverse and high-quality tokens and further enhance its reasoning capabilities during post-training. To perform such large-scale training efficiently, we utilize 8,192 Ascend NPUs with a series of system optimizations. Evaluations on multiple diverse benchmarks indicate that Pangu Ultra significantly advances the state-of-the-art capabilities of dense LLMs such as Llama 405B and Mistral Large 2, and even achieves competitive results with DeepSeek-R1, whose sparse model structure contains much more parameters. Our exploration demonstrates that Ascend NPUs are capable of efficiently and effectively training dense models with more than 100 billion parameters. Our model and system will be available for our commercial customers.
Beyond Graph Convolution: Multimodal Recommendation with Topology-aware MLPs
Dec 16, 2024



Given the large volume of side information from different modalities, multimodal recommender systems have become increasingly vital, as they exploit richer semantic information beyond user-item interactions. Recent works highlight that leveraging Graph Convolutional Networks (GCNs) to explicitly model multimodal item-item relations can significantly enhance recommendation performance. However, due to the inherent over-smoothing issue of GCNs, existing models benefit only from shallow GCNs with limited representation power. This drawback is especially pronounced when facing complex and high-dimensional patterns such as multimodal data, as it requires large-capacity models to accommodate complicated correlations. To this end, in this paper, we investigate bypassing GCNs when modeling multimodal item-item relationship. More specifically, we propose a Topology-aware Multi-Layer Perceptron (TMLP), which uses MLPs instead of GCNs to model the relationships between items. TMLP enhances MLPs with topological pruning to denoise item-item relations and intra (inter)-modality learning to integrate higher-order modality correlations. Extensive experiments on three real-world datasets verify TMLP's superiority over nine baselines. We also find that by discarding the internal message passing in GCNs, which is sensitive to node connections, TMLP achieves significant improvements in both training efficiency and robustness against existing models.
Unleashing the Potential of Multi-Channel Fusion in Retrieval for Personalized Recommendations
Oct 21, 2024



Recommender systems (RS) are pivotal in managing information overload in modern digital services. A key challenge in RS is efficiently processing vast item pools to deliver highly personalized recommendations under strict latency constraints. Multi-stage cascade ranking addresses this by employing computationally efficient retrieval methods to cover diverse user interests, followed by more precise ranking models to refine the results. In the retrieval stage, multi-channel retrieval is often used to generate distinct item subsets from different candidate generators, leveraging the complementary strengths of these methods to maximize coverage. However, forwarding all retrieved items overwhelms downstream rankers, necessitating truncation. Despite advancements in individual retrieval methods, multi-channel fusion, the process of efficiently merging multi-channel retrieval results, remains underexplored. We are the first to identify and systematically investigate multi-channel fusion in the retrieval stage. Current industry practices often rely on heuristic approaches and manual designs, which often lead to suboptimal performance. Moreover, traditional gradient-based methods like SGD are unsuitable for this task due to the non-differentiable nature of the selection process. In this paper, we explore advanced channel fusion strategies by assigning systematically optimized weights to each channel. We utilize black-box optimization techniques, including the Cross Entropy Method and Bayesian Optimization for global weight optimization, alongside policy gradient-based approaches for personalized merging. Our methods enhance both personalization and flexibility, achieving significant performance improvements across multiple datasets and yielding substantial gains in real-world deployments, offering a scalable solution for optimizing multi-channel fusion in retrieval.
All Roads Lead to Rome: Unveiling the Trajectory of Recommender Systems Across the LLM Era
Jul 14, 2024



Recommender systems (RS) are vital for managing information overload and delivering personalized content, responding to users' diverse information needs. The emergence of large language models (LLMs) offers a new horizon for redefining recommender systems with vast general knowledge and reasoning capabilities. Standing across this LLM era, we aim to integrate recommender systems into a broader picture, and pave the way for more comprehensive solutions for future research. Therefore, we first offer a comprehensive overview of the technical progression of recommender systems, particularly focusing on language foundation models and their applications in recommendation. We identify two evolution paths of modern recommender systems -- via list-wise recommendation and conversational recommendation. These two paths finally converge at LLM agents with superior capabilities of long-term memory, reflection, and tool intelligence. Along these two paths, we point out that the information effectiveness of the recommendation is increased, while the user's acquisition cost is decreased. Technical features, research methodologies, and inherent challenges for each milestone along the path are carefully investigated -- from traditional list-wise recommendation to LLM-enhanced recommendation to recommendation with LLM agents. Finally, we highlight several unresolved challenges crucial for the development of future personalization technologies and interfaces and discuss the future prospects.