 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgent-World: Scaling Real-World Environment Synthesis for Evolving General Agent Intelligence
Apr 20, 2026Large language models are increasingly expected to serve as general-purpose agents that interact with external, stateful tool environments. The Model Context Protocol (MCP) and broader agent skills offer a unified interface for connecting agents with scalable real-world services, but training robust agents remains limited by the lack of realistic environments and principled mechanisms for life-long learning. In this paper, we present \textbf{Agent-World}, a self-evolving training arena for advancing general agent intelligence through scalable environments. Agent-World has two main components: (1) Agentic Environment-Task Discovery, which autonomously explores topic-aligned databases and executable tool ecosystems from thousands of real-world environment themes and synthesizes verifiable tasks with controllable difficulty; and (2) Continuous Self-Evolving Agent Training, which combines multi-environment reinforcement learning with a self-evolving agent arena that automatically identifies capability gaps through dynamic task synthesis and drives targeted learning, enabling the co-evolution of agent policies and environments. Across 23 challenging agent benchmarks, Agent-World-8B and 14B consistently outperforms strong proprietary models and environment scaling baselines. Further analyses reveal scaling trends in relation to environment diversity and self-evolution rounds, offering insights for building general agent intelligence.
BPC-Net: Annotation-Free Skin Lesion Segmentation via Boundary Probability Calibration
Apr 07, 2026Annotation-free skin lesion segmentation is attractive for low-resource dermoscopic deployment. However, its performance remains constrained by three coupled challenges: noisy pseudo-label supervision, unstable transfer under limited target-domain data, and boundary probability under-confidence. Most existing annotation-free methods primarily focus on pseudo-label denoising. In contrast, the effect of compressed boundary probabilities on final mask quality has received less explicit attention, although it directly affects contour completeness and cannot be adequately corrected by global threshold adjustment alone. To address this issue, we propose BPC-Net, a boundary probability calibration framework for annotation-free skin lesion segmentation. The core of the framework is Gaussian Probability Smoothing (GPS), which performs localized probability-space calibration before thresholding to recover under-confident lesion boundaries without inducing indiscriminate foreground expansion. To support this calibration under noisy pseudo-supervision and cross-domain transfer, we further incorporate two auxiliary designs: a feature-decoupled decoder that separately handles context suppression, detail recovery, and boundary refinement, and an interaction-branch adaptation strategy that updates only the pseudo-label interaction branch while preserving the deployed image-only segmentation path. Under a strictly annotation-free protocol, no manual masks are used during training or target-domain adaptation, and validation labels, when available, are used only for final operating-point selection. Experiments on ISIC-2017, ISIC-2018, and PH2 show that the proposed framework achieves state-of-the-art performance among published unsupervised methods, reaching a macro-average Dice coefficient and Jaccard index of 85.80\% and 76.97\%, respectively, while approaching supervised reference performance on PH2.
Embodied Science: Closing the Discovery Loop with Agentic Embodied AI
Mar 20, 2026Artificial intelligence has demonstrated remarkable capability in predicting scientific properties, yet scientific discovery remains an inherently physical, long-horizon pursuit governed by experimental cycles. Most current computational approaches are misaligned with this reality, framing discovery as isolated, task-specific predictions rather than continuous interaction with the physical world. Here, we argue for embodied science, a paradigm that reframes scientific discovery as a closed loop tightly coupling agentic reasoning with physical execution. We propose a unified Perception-Language-Action-Discovery (PLAD) framework, wherein embodied agents perceive experimental environments, reason over scientific knowledge, execute physical interventions, and internalize outcomes to drive subsequent exploration. By grounding computational reasoning in robust physical feedback, this approach bridges the gap between digital prediction and empirical validation, offering a roadmap for autonomous discovery systems in the life and chemical sciences.
Accelerating Benchmarking of Functional Connectivity Modeling via Structure-aware Core-set Selection
Feb 05, 2026Benchmarking the hundreds of functional connectivity (FC) modeling methods on large-scale fMRI datasets is critical for reproducible neuroscience. However, the combinatorial explosion of model-data pairings makes exhaustive evaluation computationally prohibitive, preventing such assessments from becoming a routine pre-analysis step. To break this bottleneck, we reframe the challenge of FC benchmarking by selecting a small, representative core-set whose sole purpose is to preserve the relative performance ranking of FC operators. We formalize this as a ranking-preserving subset selection problem and propose Structure-aware Contrastive Learning for Core-set Selection (SCLCS), a self-supervised framework to select these core-sets. SCLCS first uses an adaptive Transformer to learn each sample's unique FC structure. It then introduces a novel Structural Perturbation Score (SPS) to quantify the stability of these learned structures during training, identifying samples that represent foundational connectivity archetypes. Finally, while SCLCS identifies stable samples via a top-k ranking, we further introduce a density-balanced sampling strategy as a necessary correction to promote diversity, ensuring the final core-set is both structurally robust and distributionally representative. On the large-scale REST-meta-MDD dataset, SCLCS preserves the ground-truth model ranking with just 10% of the data, outperforming state-of-the-art (SOTA) core-set selection methods by up to 23.2% in ranking consistency (nDCG@k). To our knowledge, this is the first work to formalize core-set selection for FC operator benchmarking, thereby making large-scale operators comparisons a feasible and integral part of computational neuroscience. Code is publicly available on https://github.com/lzhan94swu/SCLCS
ReMiT: RL-Guided Mid-Training for Iterative LLM Evolution
Feb 03, 2026Standard training pipelines for large language models (LLMs) are typically unidirectional, progressing from pre-training to post-training. However, the potential for a bidirectional process--where insights from post-training retroactively improve the pre-trained foundation--remains unexplored. We aim to establish a self-reinforcing flywheel: a cycle in which reinforcement learning (RL)-tuned model strengthens the base model, which in turn enhances subsequent post-training performance, requiring no specially trained teacher or reference model. To realize this, we analyze training dynamics and identify the mid-training (annealing) phase as a critical turning point for model capabilities. This phase typically occurs at the end of pre-training, utilizing high-quality corpora under a rapidly decaying learning rate. Building upon this insight, we introduce ReMiT (Reinforcement Learning-Guided Mid-Training). Specifically, ReMiT leverages the reasoning priors of RL-tuned models to dynamically reweight tokens during the mid-training phase, prioritizing those pivotal for reasoning. Empirically, ReMiT achieves an average improvement of 3\% on 10 pre-training benchmarks, spanning math, code, and general reasoning, and sustains these gains by over 2\% throughout the post-training pipeline. These results validate an iterative feedback loop, enabling continuous and self-reinforcing evolution of LLMs.
Youtu-LLM: Unlocking the Native Agentic Potential for Lightweight Large Language Models
Dec 31, 2025We introduce Youtu-LLM, a lightweight yet powerful language model that harmonizes high computational efficiency with native agentic intelligence. Unlike typical small models that rely on distillation, Youtu-LLM (1.96B) is pre-trained from scratch to systematically cultivate reasoning and planning capabilities. The key technical advancements are as follows: (1) Compact Architecture with Long-Context Support: Built on a dense Multi-Latent Attention (MLA) architecture with a novel STEM-oriented vocabulary, Youtu-LLM supports a 128k context window. This design enables robust long-context reasoning and state tracking within a minimal memory footprint, making it ideal for long-horizon agent and reasoning tasks. (2) Principled "Commonsense-STEM-Agent" Curriculum: We curated a massive corpus of approximately 11T tokens and implemented a multi-stage training strategy. By progressively shifting the pre-training data distribution from general commonsense to complex STEM and agentic tasks, we ensure the model acquires deep cognitive abilities rather than superficial alignment. (3) Scalable Agentic Mid-training: Specifically for the agentic mid-training, we employ diverse data construction schemes to synthesize rich and varied trajectories across math, coding, and tool-use domains. This high-quality data enables the model to internalize planning and reflection behaviors effectively. Extensive evaluations show that Youtu-LLM sets a new state-of-the-art for sub-2B LLMs. On general benchmarks, it achieves competitive performance against larger models, while on agent-specific tasks, it significantly surpasses existing SOTA baselines, demonstrating that lightweight models can possess strong intrinsic agentic capabilities.
MCI-Net: A Robust Multi-Domain Context Integration Network for Point Cloud Registration
Dec 29, 2025Robust and discriminative feature learning is critical for high-quality point cloud registration. However, existing deep learning-based methods typically rely on Euclidean neighborhood-based strategies for feature extraction, which struggle to effectively capture the implicit semantics and structural consistency in point clouds. To address these issues, we propose a multi-domain context integration network (MCI-Net) that improves feature representation and registration performance by aggregating contextual cues from diverse domains. Specifically, we propose a graph neighborhood aggregation module, which constructs a global graph to capture the overall structural relationships within point clouds. We then propose a progressive context interaction module to enhance feature discriminability by performing intra-domain feature decoupling and inter-domain context interaction. Finally, we design a dynamic inlier selection method that optimizes inlier weights using residual information from multiple iterations of pose estimation, thereby improving the accuracy and robustness of registration. Extensive experiments on indoor RGB-D and outdoor LiDAR datasets show that the proposed MCI-Net significantly outperforms existing state-of-the-art methods, achieving the highest registration recall of 96.4\% on 3DMatch. Source code is available at http://www.linshuyuan.com.
SC-Net: Robust Correspondence Learning via Spatial and Cross-Channel Context
Dec 29, 2025Recent research has focused on using convolutional neural networks (CNNs) as the backbones in two-view correspondence learning, demonstrating significant superiority over methods based on multilayer perceptrons. However, CNN backbones that are not tailored to specific tasks may fail to effectively aggregate global context and oversmooth dense motion fields in scenes with large disparity. To address these problems, we propose a novel network named SC-Net, which effectively integrates bilateral context from both spatial and channel perspectives. Specifically, we design an adaptive focused regularization module (AFR) to enhance the model's position-awareness and robustness against spurious motion samples, thereby facilitating the generation of a more accurate motion field. We then propose a bilateral field adjustment module (BFA) to refine the motion field by simultaneously modeling long-range relationships and facilitating interaction across spatial and channel dimensions. Finally, we recover the motion vectors from the refined field using a position-aware recovery module (PAR) that ensures consistency and precision. Extensive experiments demonstrate that SC-Net outperforms state-of-the-art methods in relative pose estimation and outlier removal tasks on YFCC100M and SUN3D datasets. Source code is available at http://www.linshuyuan.com.
LIR$^3$AG: A Lightweight Rerank Reasoning Strategy Framework for Retrieval-Augmented Generation
Dec 20, 2025Retrieval-Augmented Generation (RAG) effectively enhances Large Language Models (LLMs) by incorporating retrieved external knowledge into the generation process. Reasoning models improve LLM performance in multi-hop QA tasks, which require integrating and reasoning over multiple pieces of evidence across different documents to answer a complex question. However, they often introduce substantial computational costs, including increased token consumption and inference latency. To better understand and mitigate this trade-off, we conduct a comprehensive study of reasoning strategies for reasoning models in RAG multi-hop QA tasks. Our findings reveal that reasoning models adopt structured strategies to integrate retrieved and internal knowledge, primarily following two modes: Context-Grounded Reasoning, which relies directly on retrieved content, and Knowledge-Reconciled Reasoning, which resolves conflicts or gaps using internal knowledge. To this end, we propose a novel Lightweight Rerank Reasoning Strategy Framework for RAG (LiR$^3$AG) to enable non-reasoning models to transfer reasoning strategies by restructuring retrieved evidence into coherent reasoning chains. LiR$^3$AG significantly reduce the average 98% output tokens overhead and 58.6% inferencing time while improving 8B non-reasoning model's F1 performance ranging from 6.2% to 22.5% to surpass the performance of 32B reasoning model in RAG, offering a practical and efficient path forward for RAG systems.
Data Trajectory Alignment for LLM Domain Adaptation: A Two-Phase Synthesis Framework for Telecommunications Mathematics
Nov 10, 2025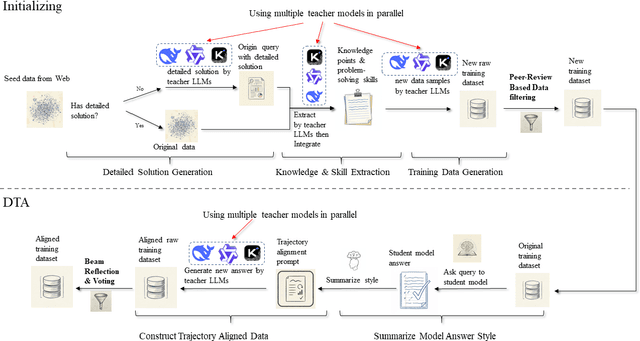


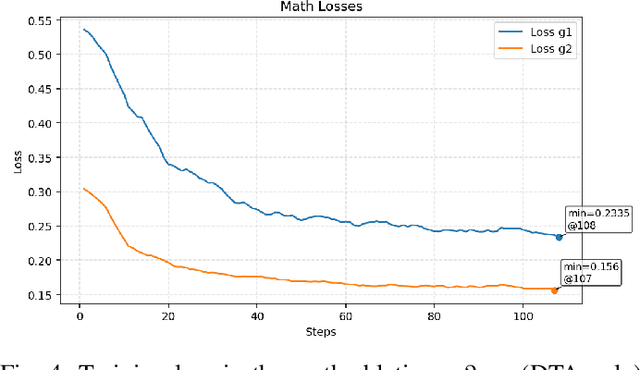
General-purpose large language models (LLMs) are increasingly deployed in verticals such as telecommunications, where adaptation is hindered by scarce, low-information-density corpora and tight mobile/edge constraints. We propose Data Trajectory Alignment (DTA), a two-phase, model-agnostic data curation framework that treats solution processes - not only final answers - as first-class supervision. Phase I (Initializing) synthesizes diverse, high-coverage candidates using an ensemble of strong teachers. Phase II (DTA) rewrites teacher solutions to align intermediate steps and presentation style with the target student's inductive biases and then performs signal-aware exemplar selection via agreement checks and reflection-based judging. Instantiated on telecommunications mathematics (e.g., link budgets, SNR/AMC selection, and power-control feasibility), DTA yields state-of-the-art (SOTA) accuracy on TELEMATH without enabling explicit "thinking" modes: 72.45% pass@1, surpassing distilled-only training by +17.65 points and outperforming a strong baseline (Qwen3-32B with thinking enabled) by +2.94 points. Token-shift analyses indicate that DTA concentrates gains on logical-structural discourse markers rather than merely amplifying domain nouns, indicating improved reasoning scaffolding. Under edge-like inference settings, DTA improves efficiency by reducing reliance on multi-sample voting and disabling expensive reasoning heuristics, cutting energy per output token by ~42% versus Qwen3-32B (thinking mode enabled) and end-to-end latency by ~60% versus Qwen3-32B (thinking mode disabled). These results demonstrate that aligning how solutions are produced enables compact, high-yield supervision that is effective for both accuracy and efficiency, offering a practical recipe for domain adaptation in low-resource verticals beyond telecom.