 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKnowledge-aware Alert Aggregation in Large-scale Cloud Systems: a Hybrid Approach
Mar 11, 2024Due to the scale and complexity of cloud systems, a system failure would trigger an "alert storm", i.e., massive correlated alerts. Although these alerts can be traced back to a few root causes, the overwhelming number makes it infeasible for manual handling. Alert aggregation is thus critical to help engineers concentrate on the root cause and facilitate failure resolution. Existing methods typically utilize semantic similarity-based methods or statistical methods to aggregate alerts. However, semantic similarity-based methods overlook the causal rationale of alerts, while statistical methods can hardly handle infrequent alerts. To tackle these limitations, we introduce leveraging external knowledge, i.e., Standard Operation Procedure (SOP) of alerts as a supplement. We propose COLA, a novel hybrid approach based on correlation mining and LLM (Large Language Model) reasoning for online alert aggregation. The correlation mining module effectively captures the temporal and spatial relations between alerts, measuring their correlations in an efficient manner. Subsequently, only uncertain pairs with low confidence are forwarded to the LLM reasoning module for detailed analysis. This hybrid design harnesses both statistical evidence for frequent alerts and the reasoning capabilities of computationally intensive LLMs, ensuring the overall efficiency of COLA in handling large volumes of alerts in practical scenarios. We evaluate COLA on three datasets collected from the production environment of a large-scale cloud platform. The experimental results show COLA achieves F1-scores from 0.901 to 0.930, outperforming state-of-the-art methods and achieving comparable efficiency. We also share our experience in deploying COLA in our real-world cloud system, Cloud X.
FaultProfIT: Hierarchical Fault Profiling of Incident Tickets in Large-scale Cloud Systems
Feb 27, 2024Postmortem analysis is essential in the management of incidents within cloud systems, which provides valuable insights to improve system's reliability and robustness. At CloudA, fault pattern profiling is performed during the postmortem phase, which involves the classification of incidents' faults into unique categories, referred to as fault pattern. By aggregating and analyzing these fault patterns, engineers can discern common faults, vulnerable components and emerging fault trends. However, this process is currently conducted by manual labeling, which has inherent drawbacks. On the one hand, the sheer volume of incidents means only the most severe ones are analyzed, causing a skewed overview of fault patterns. On the other hand, the complexity of the task demands extensive domain knowledge, which leads to errors and inconsistencies. To address these limitations, we propose an automated approach, named FaultProfIT, for Fault pattern Profiling of Incident Tickets. It leverages hierarchy-guided contrastive learning to train a hierarchy-aware incident encoder and predicts fault patterns with enhanced incident representations. We evaluate FaultProfIT using the production incidents from CloudA. The results demonstrate that FaultProfIT outperforms state-of-the-art methods. Our ablation study and analysis also verify the effectiveness of hierarchy-guided contrastive learning. Additionally, we have deployed FaultProfIT at CloudA for six months. To date, FaultProfIT has analyzed 10,000+ incidents from 30+ cloud services, successfully revealing several fault trends that have informed system improvements.
An Image is Worth a Thousand Toxic Words: A Metamorphic Testing Framework for Content Moderation Software
Aug 18, 2023


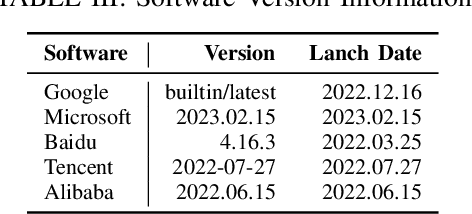
The exponential growth of social media platforms has brought about a revolution in communication and content dissemination in human society. Nevertheless, these platforms are being increasingly misused to spread toxic content, including hate speech, malicious advertising, and pornography, leading to severe negative consequences such as harm to teenagers' mental health. Despite tremendous efforts in developing and deploying textual and image content moderation methods, malicious users can evade moderation by embedding texts into images, such as screenshots of the text, usually with some interference. We find that modern content moderation software's performance against such malicious inputs remains underexplored. In this work, we propose OASIS, a metamorphic testing framework for content moderation software. OASIS employs 21 transform rules summarized from our pilot study on 5,000 real-world toxic contents collected from 4 popular social media applications, including Twitter, Instagram, Sina Weibo, and Baidu Tieba. Given toxic textual contents, OASIS can generate image test cases, which preserve the toxicity yet are likely to bypass moderation. In the evaluation, we employ OASIS to test five commercial textual content moderation software from famous companies (i.e., Google Cloud, Microsoft Azure, Baidu Cloud, Alibaba Cloud and Tencent Cloud), as well as a state-of-the-art moderation research model. The results show that OASIS achieves up to 100% error finding rates. Moreover, through retraining the models with the test cases generated by OASIS, the robustness of the moderation model can be improved without performance degradation.
Performance Issue Identification in Cloud Systems with Relational-Temporal Anomaly Detection
Aug 01, 2023Performance issues permeate large-scale cloud service systems, which can lead to huge revenue losses. To ensure reliable performance, it's essential to accurately identify and localize these issues using service monitoring metrics. Given the complexity and scale of modern cloud systems, this task can be challenging and may require extensive expertise and resources beyond the capacity of individual humans. Some existing methods tackle this problem by analyzing each metric independently to detect anomalies. However, this could incur overwhelming alert storms that are difficult for engineers to diagnose manually. To pursue better performance, not only the temporal patterns of metrics but also the correlation between metrics (i.e., relational patterns) should be considered, which can be formulated as a multivariate metrics anomaly detection problem. However, most of the studies fall short of extracting these two types of features explicitly. Moreover, there exist some unlabeled anomalies mixed in the training data, which may hinder the detection performance. To address these limitations, we propose the Relational- Temporal Anomaly Detection Model (RTAnomaly) that combines the relational and temporal information of metrics. RTAnomaly employs a graph attention layer to learn the dependencies among metrics, which will further help pinpoint the anomalous metrics that may cause the anomaly effectively. In addition, we exploit the concept of positive unlabeled learning to address the issue of potential anomalies in the training data. To evaluate our method, we conduct experiments on a public dataset and two industrial datasets. RTAnomaly outperforms all the baseline models by achieving an average F1 score of 0.929 and Hit@3 of 0.920, demonstrating its superiority.
Scalable and Adaptive Log-based Anomaly Detection with Expert in the Loop
Jun 08, 2023System logs play a critical role in maintaining the reliability of software systems. Fruitful studies have explored automatic log-based anomaly detection and achieved notable accuracy on benchmark datasets. However, when applied to large-scale cloud systems, these solutions face limitations due to high resource consumption and lack of adaptability to evolving logs. In this paper, we present an accurate, lightweight, and adaptive log-based anomaly detection framework, referred to as SeaLog. Our method introduces a Trie-based Detection Agent (TDA) that employs a lightweight, dynamically-growing trie structure for real-time anomaly detection. To enhance TDA's accuracy in response to evolving log data, we enable it to receive feedback from experts. Interestingly, our findings suggest that contemporary large language models, such as ChatGPT, can provide feedback with a level of consistency comparable to human experts, which can potentially reduce manual verification efforts. We extensively evaluate SeaLog on two public datasets and an industrial dataset. The results show that SeaLog outperforms all baseline methods in terms of effectiveness, runs 2X to 10X faster and only consumes 5% to 41% of the memory resource.
Validating Multimedia Content Moderation Software via Semantic Fusion
May 23, 2023The exponential growth of social media platforms, such as Facebook and TikTok, has revolutionized communication and content publication in human society. Users on these platforms can publish multimedia content that delivers information via the combination of text, audio, images, and video. Meanwhile, the multimedia content release facility has been increasingly exploited to propagate toxic content, such as hate speech, malicious advertisements, and pornography. To this end, content moderation software has been widely deployed on these platforms to detect and blocks toxic content. However, due to the complexity of content moderation models and the difficulty of understanding information across multiple modalities, existing content moderation software can fail to detect toxic content, which often leads to extremely negative impacts. We introduce Semantic Fusion, a general, effective methodology for validating multimedia content moderation software. Our key idea is to fuse two or more existing single-modal inputs (e.g., a textual sentence and an image) into a new input that combines the semantics of its ancestors in a novel manner and has toxic nature by construction. This fused input is then used for validating multimedia content moderation software. We realized Semantic Fusion as DUO, a practical content moderation software testing tool. In our evaluation, we employ DUO to test five commercial content moderation software and two state-of-the-art models against three kinds of toxic content. The results show that DUO achieves up to 100% error finding rate (EFR) when testing moderation software. In addition, we leverage the test cases generated by DUO to retrain the two models we explored, which largely improves model robustness while maintaining the accuracy on the original test set.
BiasAsker: Measuring the Bias in Conversational AI System
May 21, 2023Powered by advanced Artificial Intelligence (AI) techniques, conversational AI systems, such as ChatGPT and digital assistants like Siri, have been widely deployed in daily life. However, such systems may still produce content containing biases and stereotypes, causing potential social problems. Due to the data-driven, black-box nature of modern AI techniques, comprehensively identifying and measuring biases in conversational systems remains a challenging task. Particularly, it is hard to generate inputs that can comprehensively trigger potential bias due to the lack of data containing both social groups as well as biased properties. In addition, modern conversational systems can produce diverse responses (e.g., chatting and explanation), which makes existing bias detection methods simply based on the sentiment and the toxicity hardly being adopted. In this paper, we propose BiasAsker, an automated framework to identify and measure social bias in conversational AI systems. To obtain social groups and biased properties, we construct a comprehensive social bias dataset, containing a total of 841 groups and 8,110 biased properties. Given the dataset, BiasAsker automatically generates questions and adopts a novel method based on existence measurement to identify two types of biases (i.e., absolute bias and related bias) in conversational systems. Extensive experiments on 8 commercial systems and 2 famous research models, such as ChatGPT and GPT-3, show that 32.83% of the questions generated by BiasAsker can trigger biased behaviors in these widely deployed conversational systems. All the code, data, and experimental results have been released to facilitate future research.
Detecting Deep Neural Network Defects with Data Flow Analysis
Sep 30, 2019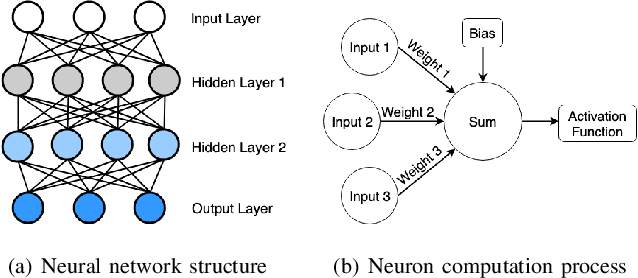


Deep neural networks (DNNs) are shown to be promising solutions in many challenging artificial intelligence tasks. However, it is very hard to figure out whether the low precision of a DNN model is an inevitable result, or caused by defects. This paper aims at addressing this challenging problem. We find that the internal data flow footprints of a DNN model can provide insights to locate the root cause effectively. We develop DeepMorph (DNN Tomography) to analyze the root cause, which can guide a DNN developer to improve the model.