 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSPEAR: Code-Augmented Agentic Prompt Optimization
May 25, 2026Automatic prompt engineering (APE) rewrites prompts to improve downstream task performance, but existing APE loops treat the optimizer itself as a fixed pipeline. We port the code-as-action paradigm of CodeAct (Wang et al., 2024a) to APE and propose SPEAR (Sandboxed Prompt Engineer with Active Roll-back), a free-form agentic optimizer with four tools -- evaluate, python, set_prompt, finish -- that decides autonomously how and when to use them. The distinctive tool is the Python sandbox: the optimizer writes and executes arbitrary Python on the current evaluation DataFrame, performing structural error analysis (confusion matrices, error clustering, per group metrics) the agent itself authors. Two guardrails turn the long-horizon agent into a monotone-improving optimizer: auto-rollback on metric regression, and an optional guard metric floor. We evaluate on three industrial LLM-as-judge suites (13 judge tasks across recruiter-intake, conversational-memory, and query-refinement systems) plus seven BBH tasks and GSM8K. SPEAR wins every industrial task on the primary metric ($κ$ 0.857 vs 0.359 on tool-selection; F1-macro 0.815 vs 0.763 on filter-relevance; $κ$ 0.254 vs 0.218 on the hardest extraction dimension). On BBH-7 SPEAR averages 0.938 accuracy vs GEPA 0.628 and TextGrad 0.484. Ablations show the Python tool is the largest single lever on complex judge tasks ($Δ\approx +0.79κ$ on the 5-class tool-selection judge, $Δ\approx +0.35κ$ on the hardest extraction dimension when removed); its irreplaceable contribution is class-pair confusion aggregation that a long-context LLM cannot extract reliably from the raw eval DataFrame.
Emulating Clinician Cognition via Self-Evolving Deep Clinical Research
Mar 11, 2026Clinical diagnosis is a complex cognitive process, grounded in dynamic cue acquisition and continuous expertise accumulation. Yet most current artificial intelligence (AI) systems are misaligned with this reality, treating diagnosis as single-pass retrospective prediction while lacking auditable mechanisms for governed improvement. We developed DxEvolve, a self-evolving diagnostic agent that bridges these gaps through an interactive deep clinical research workflow. The framework autonomously requisitions examinations and continually externalizes clinical experience from increasing encounter exposure as diagnostic cognition primitives. On the MIMIC-CDM benchmark, DxEvolve improved diagnostic accuracy by 11.2% on average over backbone models and reached 90.4% on a reader-study subset, comparable to the clinician reference (88.8%). DxEvolve improved accuracy on an independent external cohort by 10.2% (categories covered by the source cohort) and 17.1% (uncovered categories) compared to the competitive method. By transforming experience into a governable learning asset, DxEvolve supports an accountable pathway for the continual evolution of clinical AI.
Multi-Modal Multi-Granularity Tokenizer for Chu Bamboo Slip Scripts
Sep 02, 2024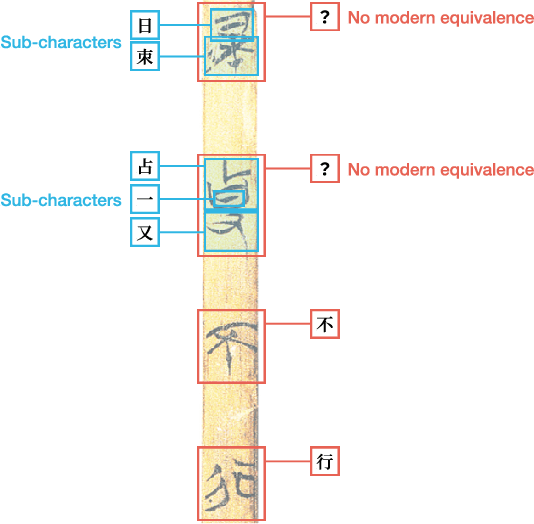
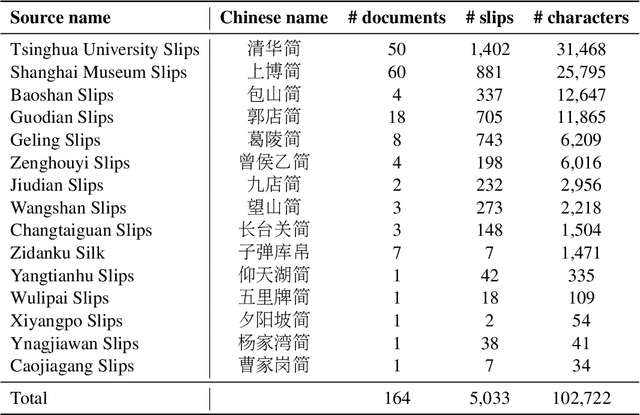
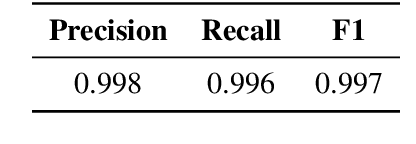
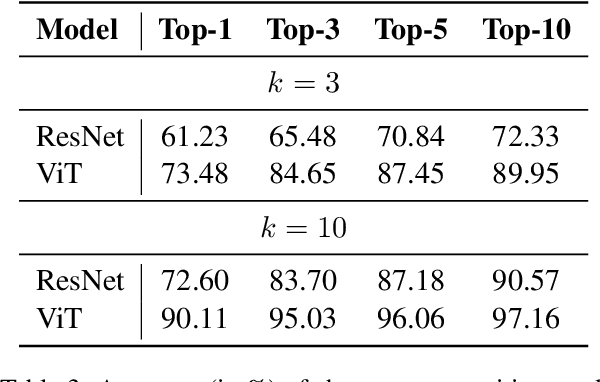
This study presents a multi-modal multi-granularity tokenizer specifically designed for analyzing ancient Chinese scripts, focusing on the Chu bamboo slip (CBS) script used during the Spring and Autumn and Warring States period (771-256 BCE) in Ancient China. Considering the complex hierarchical structure of ancient Chinese scripts, where a single character may be a combination of multiple sub-characters, our tokenizer first adopts character detection to locate character boundaries, and then conducts character recognition at both the character and sub-character levels. Moreover, to support the academic community, we have also assembled the first large-scale dataset of CBSs with over 100K annotated character image scans. On the part-of-speech tagging task built on our dataset, using our tokenizer gives a 5.5% relative improvement in F1-score compared to mainstream sub-word tokenizers. Our work not only aids in further investigations of the specific script but also has the potential to advance research on other forms of ancient Chinese scripts.
FaultProfIT: Hierarchical Fault Profiling of Incident Tickets in Large-scale Cloud Systems
Feb 27, 2024Postmortem analysis is essential in the management of incidents within cloud systems, which provides valuable insights to improve system's reliability and robustness. At CloudA, fault pattern profiling is performed during the postmortem phase, which involves the classification of incidents' faults into unique categories, referred to as fault pattern. By aggregating and analyzing these fault patterns, engineers can discern common faults, vulnerable components and emerging fault trends. However, this process is currently conducted by manual labeling, which has inherent drawbacks. On the one hand, the sheer volume of incidents means only the most severe ones are analyzed, causing a skewed overview of fault patterns. On the other hand, the complexity of the task demands extensive domain knowledge, which leads to errors and inconsistencies. To address these limitations, we propose an automated approach, named FaultProfIT, for Fault pattern Profiling of Incident Tickets. It leverages hierarchy-guided contrastive learning to train a hierarchy-aware incident encoder and predicts fault patterns with enhanced incident representations. We evaluate FaultProfIT using the production incidents from CloudA. The results demonstrate that FaultProfIT outperforms state-of-the-art methods. Our ablation study and analysis also verify the effectiveness of hierarchy-guided contrastive learning. Additionally, we have deployed FaultProfIT at CloudA for six months. To date, FaultProfIT has analyzed 10,000+ incidents from 30+ cloud services, successfully revealing several fault trends that have informed system improvements.
Practical Anomaly Detection over Multivariate Monitoring Metrics for Online Services
Aug 19, 2023



As modern software systems continue to grow in terms of complexity and volume, anomaly detection on multivariate monitoring metrics, which profile systems' health status, becomes more and more critical and challenging. In particular, the dependency between different metrics and their historical patterns plays a critical role in pursuing prompt and accurate anomaly detection. Existing approaches fall short of industrial needs for being unable to capture such information efficiently. To fill this significant gap, in this paper, we propose CMAnomaly, an anomaly detection framework on multivariate monitoring metrics based on collaborative machine. The proposed collaborative machine is a mechanism to capture the pairwise interactions along with feature and temporal dimensions with linear time complexity. Cost-effective models can then be employed to leverage both the dependency between monitoring metrics and their historical patterns for anomaly detection. The proposed framework is extensively evaluated with both public data and industrial data collected from a large-scale online service system of Huawei Cloud. The experimental results demonstrate that compared with state-of-the-art baseline models, CMAnomaly achieves an average F1 score of 0.9494, outperforming baselines by 6.77% to 10.68%, and runs 10X to 20X faster. Furthermore, we also share our experience of deploying CMAnomaly in Huawei Cloud.
Performance Issue Identification in Cloud Systems with Relational-Temporal Anomaly Detection
Aug 01, 2023Performance issues permeate large-scale cloud service systems, which can lead to huge revenue losses. To ensure reliable performance, it's essential to accurately identify and localize these issues using service monitoring metrics. Given the complexity and scale of modern cloud systems, this task can be challenging and may require extensive expertise and resources beyond the capacity of individual humans. Some existing methods tackle this problem by analyzing each metric independently to detect anomalies. However, this could incur overwhelming alert storms that are difficult for engineers to diagnose manually. To pursue better performance, not only the temporal patterns of metrics but also the correlation between metrics (i.e., relational patterns) should be considered, which can be formulated as a multivariate metrics anomaly detection problem. However, most of the studies fall short of extracting these two types of features explicitly. Moreover, there exist some unlabeled anomalies mixed in the training data, which may hinder the detection performance. To address these limitations, we propose the Relational- Temporal Anomaly Detection Model (RTAnomaly) that combines the relational and temporal information of metrics. RTAnomaly employs a graph attention layer to learn the dependencies among metrics, which will further help pinpoint the anomalous metrics that may cause the anomaly effectively. In addition, we exploit the concept of positive unlabeled learning to address the issue of potential anomalies in the training data. To evaluate our method, we conduct experiments on a public dataset and two industrial datasets. RTAnomaly outperforms all the baseline models by achieving an average F1 score of 0.929 and Hit@3 of 0.920, demonstrating its superiority.
Scalable and Adaptive Log-based Anomaly Detection with Expert in the Loop
Jun 08, 2023System logs play a critical role in maintaining the reliability of software systems. Fruitful studies have explored automatic log-based anomaly detection and achieved notable accuracy on benchmark datasets. However, when applied to large-scale cloud systems, these solutions face limitations due to high resource consumption and lack of adaptability to evolving logs. In this paper, we present an accurate, lightweight, and adaptive log-based anomaly detection framework, referred to as SeaLog. Our method introduces a Trie-based Detection Agent (TDA) that employs a lightweight, dynamically-growing trie structure for real-time anomaly detection. To enhance TDA's accuracy in response to evolving log data, we enable it to receive feedback from experts. Interestingly, our findings suggest that contemporary large language models, such as ChatGPT, can provide feedback with a level of consistency comparable to human experts, which can potentially reduce manual verification efforts. We extensively evaluate SeaLog on two public datasets and an industrial dataset. The results show that SeaLog outperforms all baseline methods in terms of effectiveness, runs 2X to 10X faster and only consumes 5% to 41% of the memory resource.
Transferrable Operative Difficulty Assessment in Robot-assisted Teleoperation: A Domain Adaptation Approach
Jun 12, 2019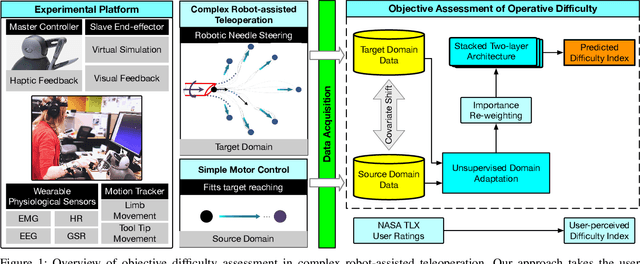
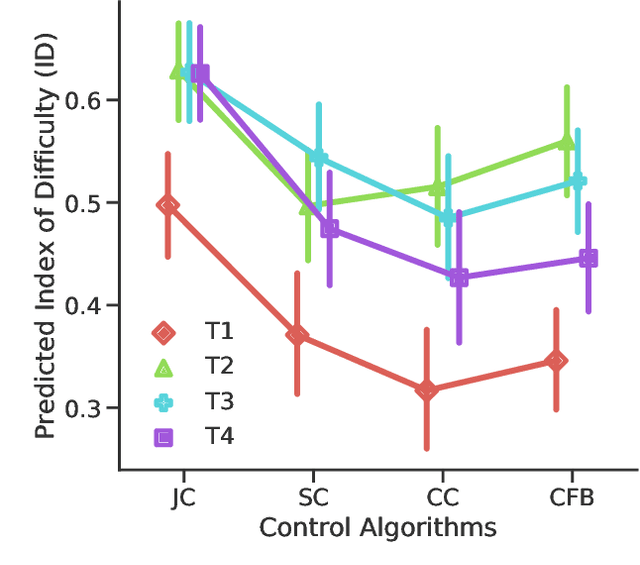
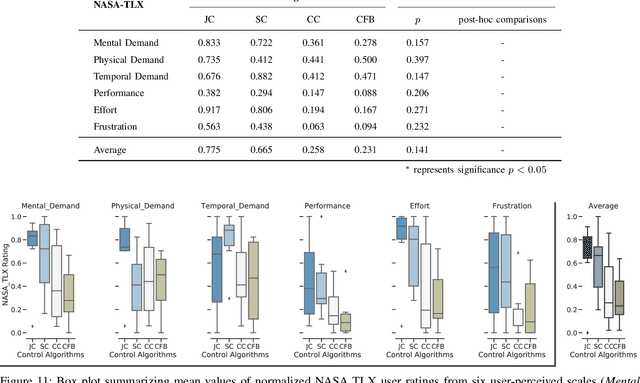
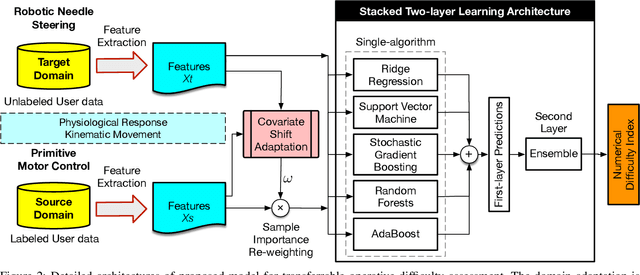
Providing an accurate and efficient assessment of operative difficulty is important for designing robot-assisted teleoperation interfaces that are easy and natural for human operators to use. In this paper, we aim to develop a data-driven approach to numerically characterize the operative difficulty demand of complex teleoperation. In effort to provide an entirely task-independent assessment, we consider using only data collected from the human user including: (1) physiological response, and (2) movement kinematics. By leveraging an unsupervised domain adaptation technique, our approach learns the user information that defines task difficulty in a well-known source, namely, a Fitt's target reaching task, and generalizes that knowledge to a more complex human motor control scenario, namely, the teleoperation of a robotic system. Our approach consists of two main parts: (1) The first part accounts for the inherent variances of user physiological and kinematic response between these cross-domain motor control scenarios that are vastly different. (2) A stacked two-layer learner is designed to improve the overall modeling performance, yielding a 96.6% accuracy in predicting the known difficulty of a Fitts' reaching task when using movement kinematic features. We then validate the effectiveness of our model by investigating teleoperated robotic needle steering as a case study. Compared with a standard NASA TLX user survey, our results indicate significant differences in the difficulty demand for various choices of needle steering control algorithms, p<0.05, as well as the difficulty of steering the needle to different targets, p<0.05. The results highlight the potential of our approach to be used as a design tool to create more intuitive and natural teleoperation interfaces in robot-assisted systems.
Reinforcement Learning based Dynamic Model Selection for Short-Term Load Forecasting
Nov 05, 2018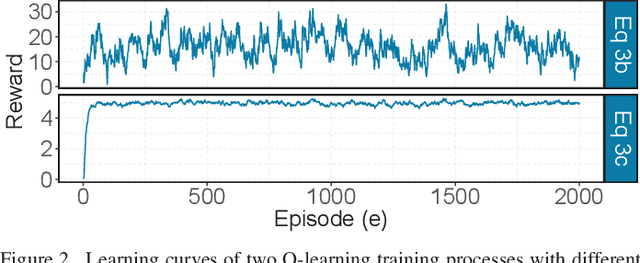
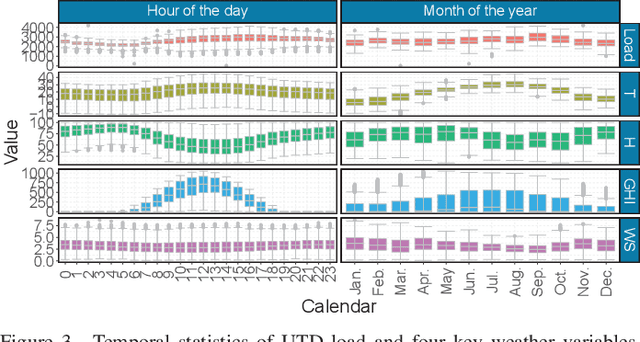
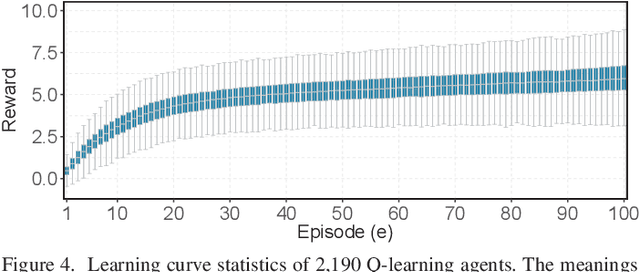
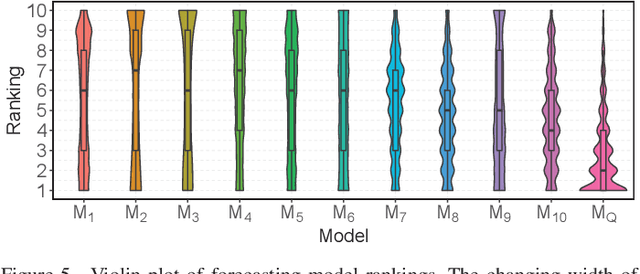
With the growing prevalence of smart grid technology, short-term load forecasting (STLF) becomes particularly important in power system operations. There is a large collection of methods developed for STLF, but selecting a suitable method under varying conditions is still challenging. This paper develops a novel reinforcement learning based dynamic model selection (DMS) method for STLF. A forecasting model pool is first built, including ten state-of-the-art machine learning based forecasting models. Then a Q-learning agent learns the optimal policy of selecting the best forecasting model for the next time step, based on the model performance. The optimal DMS policy is applied to select the best model at each time step with a moving window. Numerical simulations on two-year load and weather data show that the Q-learning algorithm converges fast, resulting in effective and efficient DMS. The developed STLF model with Q-learning based DMS improves the forecasting accuracy by approximately 50%, compared to the state-of-the-art machine learning based STLF models.
An Unsupervised Clustering-Based Short-Term Solar Forecasting Methodology Using Multi-Model Machine Learning Blending
May 10, 2018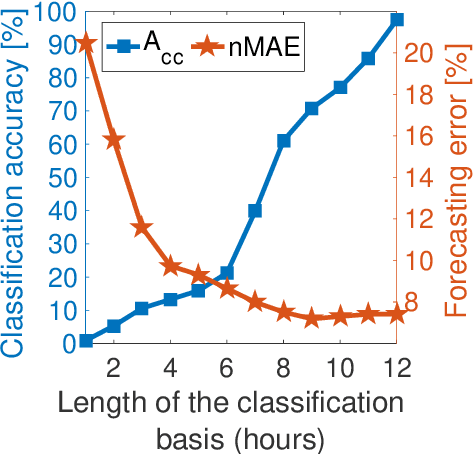
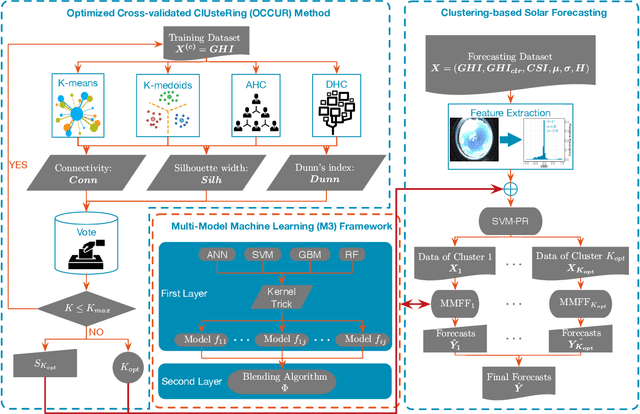
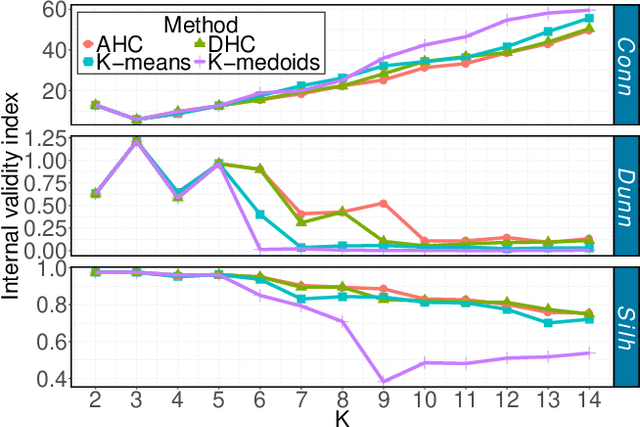
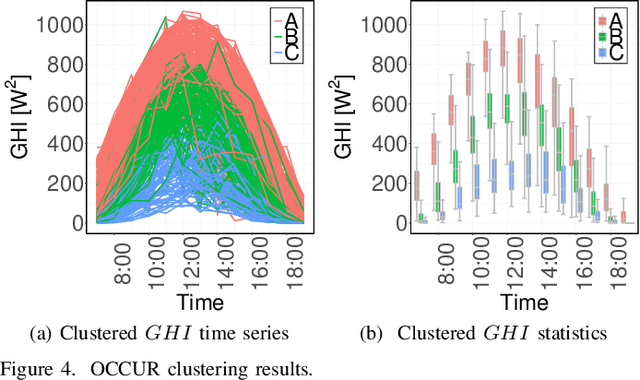
Solar forecasting accuracy is affected by weather conditions, and weather awareness forecasting models are expected to improve the performance. However, it may not be available and reliable to classify different forecasting tasks by using only meteorological weather categorization. In this paper, an unsupervised clustering-based (UC-based) solar forecasting methodology is developed for short-term (1-hour-ahead) global horizontal irradiance (GHI) forecasting. This methodology consists of three parts: GHI time series unsupervised clustering, pattern recognition, and UC-based forecasting. The daily GHI time series is first clustered by an Optimized Cross-validated ClUsteRing (OCCUR) method, which determines the optimal number of clusters and best clustering results. Then, support vector machine pattern recognition (SVM-PR) is adopted to recognize the category of a certain day using the first few hours' data in the forecasting stage. GHI forecasts are generated by the most suitable models in different clusters, which are built by a two-layer Machine learning based Multi-Model (M3) forecasting framework. The developed UC-based methodology is validated by using 1-year of data with six solar features. Numerical results show that (i) UC-based models outperform non-UC (all-in-one) models with the same M3 architecture by approximately 20%; (ii) M3-based models also outperform the single-algorithm machine learning (SAML) models by approximately 20%.