 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSparsing Law: Towards Large Language Models with Greater Activation Sparsity
Nov 04, 2024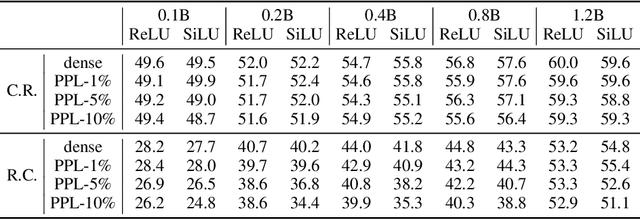
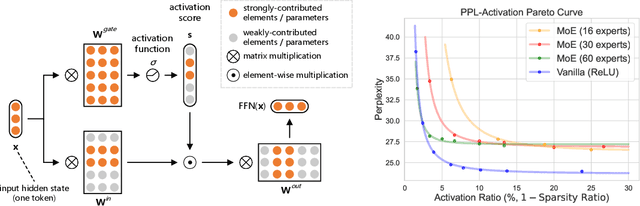

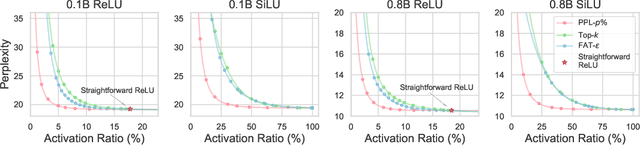
Activation sparsity denotes the existence of substantial weakly-contributed elements within activation outputs that can be eliminated, benefiting many important applications concerned with large language models (LLMs). Although promoting greater activation sparsity within LLMs deserves deep studies, existing works lack comprehensive and quantitative research on the correlation between activation sparsity and potentially influential factors. In this paper, we present a comprehensive study on the quantitative scaling properties and influential factors of the activation sparsity within decoder-only Transformer-based LLMs. Specifically, we propose PPL-$p\%$ sparsity, a precise and performance-aware activation sparsity metric that is applicable to any activation function. Through extensive experiments, we find several important phenomena. Firstly, different activation functions exhibit comparable performance but opposite training-time sparsity trends. The activation ratio (i.e., $1-\mathrm{sparsity\ ratio}$) evolves as a convergent increasing power-law and decreasing logspace power-law with the amount of training data for SiLU-activated and ReLU-activated LLMs, respectively. These demonstrate that ReLU is more efficient as the activation function than SiLU and can leverage more training data to improve activation sparsity. Secondly, the activation ratio linearly increases with the width-depth ratio below a certain bottleneck point, indicating the potential advantage of a deeper architecture at a fixed parameter scale. Finally, at similar width-depth ratios, we surprisingly find that the limit value of activation sparsity varies weakly with the parameter scale, i.e., the activation patterns within LLMs are insensitive to the parameter scale. These empirical laws towards LLMs with greater activation sparsity have important implications for making LLMs more efficient and interpretable.
Configurable Foundation Models: Building LLMs from a Modular Perspective
Sep 04, 2024



Advancements in LLMs have recently unveiled challenges tied to computational efficiency and continual scalability due to their requirements of huge parameters, making the applications and evolution of these models on devices with limited computation resources and scenarios requiring various abilities increasingly cumbersome. Inspired by modularity within the human brain, there is a growing tendency to decompose LLMs into numerous functional modules, allowing for inference with part of modules and dynamic assembly of modules to tackle complex tasks, such as mixture-of-experts. To highlight the inherent efficiency and composability of the modular approach, we coin the term brick to represent each functional module, designating the modularized structure as configurable foundation models. In this paper, we offer a comprehensive overview and investigation of the construction, utilization, and limitation of configurable foundation models. We first formalize modules into emergent bricks - functional neuron partitions that emerge during the pre-training phase, and customized bricks - bricks constructed via additional post-training to improve the capabilities and knowledge of LLMs. Based on diverse functional bricks, we further present four brick-oriented operations: retrieval and routing, merging, updating, and growing. These operations allow for dynamic configuration of LLMs based on instructions to handle complex tasks. To verify our perspective, we conduct an empirical analysis on widely-used LLMs. We find that the FFN layers follow modular patterns with functional specialization of neurons and functional neuron partitions. Finally, we highlight several open issues and directions for future research. Overall, this paper aims to offer a fresh modular perspective on existing LLM research and inspire the future creation of more efficient and scalable foundational models.
Multi-Modal Multi-Granularity Tokenizer for Chu Bamboo Slip Scripts
Sep 02, 2024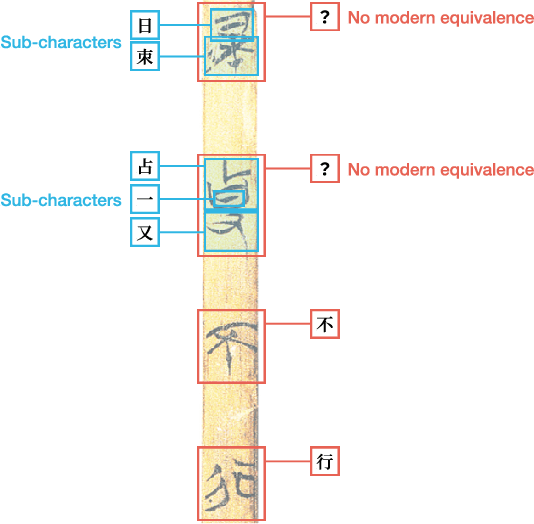
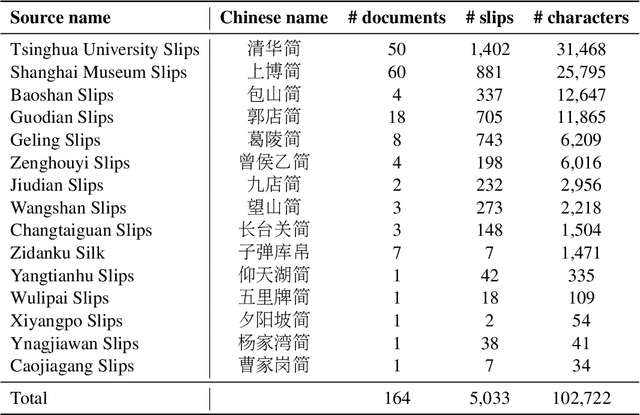
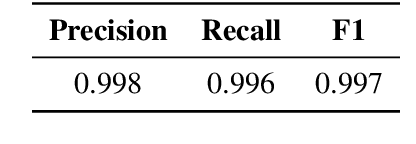
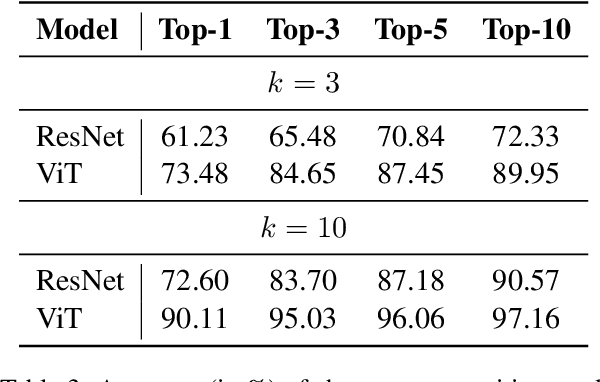
This study presents a multi-modal multi-granularity tokenizer specifically designed for analyzing ancient Chinese scripts, focusing on the Chu bamboo slip (CBS) script used during the Spring and Autumn and Warring States period (771-256 BCE) in Ancient China. Considering the complex hierarchical structure of ancient Chinese scripts, where a single character may be a combination of multiple sub-characters, our tokenizer first adopts character detection to locate character boundaries, and then conducts character recognition at both the character and sub-character levels. Moreover, to support the academic community, we have also assembled the first large-scale dataset of CBSs with over 100K annotated character image scans. On the part-of-speech tagging task built on our dataset, using our tokenizer gives a 5.5% relative improvement in F1-score compared to mainstream sub-word tokenizers. Our work not only aids in further investigations of the specific script but also has the potential to advance research on other forms of ancient Chinese scripts.
ProSparse: Introducing and Enhancing Intrinsic Activation Sparsity within Large Language Models
Feb 27, 2024Activation sparsity refers to the existence of considerable weakly-contributed elements among activation outputs. As a prevalent property of the models using the ReLU activation function, it has been proven a promising paradigm to boost model inference efficiency. Nevertheless, most large language models (LLMs) adopt activation functions without intrinsic activation sparsity (e.g., GELU and Swish). Some recent efforts have explored introducing ReLU or its variants as the substitutive activation function to help LLMs achieve activation sparsity and inference acceleration, but few can simultaneously obtain high sparsity and comparable model performance. This paper introduces an effective sparsification method named "ProSparse" to push LLMs for higher activation sparsity without decreasing model performance. Specifically, after substituting the activation function of LLMs with ReLU, ProSparse adopts progressive sparsity regularization with a factor smoothly increasing along sine curves in multiple stages. This can enhance activation sparsity and alleviate performance degradation by avoiding radical shifts in activation distribution. With ProSparse, we obtain high sparsity of 89.32% and 88.80% for LLaMA2-7B and LLaMA2-13B, respectively, achieving comparable performance to their original Swish-activated versions. Our inference acceleration experiments further demonstrate the practical acceleration brought by higher activation sparsity.
ReLU$^2$ Wins: Discovering Efficient Activation Functions for Sparse LLMs
Feb 06, 2024Sparse computation offers a compelling solution for the inference of Large Language Models (LLMs) in low-resource scenarios by dynamically skipping the computation of inactive neurons. While traditional approaches focus on ReLU-based LLMs, leveraging zeros in activation values, we broaden the scope of sparse LLMs beyond zero activation values. We introduce a general method that defines neuron activation through neuron output magnitudes and a tailored magnitude threshold, demonstrating that non-ReLU LLMs also exhibit sparse activation. To find the most efficient activation function for sparse computation, we propose a systematic framework to examine the sparsity of LLMs from three aspects: the trade-off between sparsity and performance, the predictivity of sparsity, and the hardware affinity. We conduct thorough experiments on LLMs utilizing different activation functions, including ReLU, SwiGLU, ReGLU, and ReLU$^2$. The results indicate that models employing ReLU$^2$ excel across all three evaluation aspects, highlighting its potential as an efficient activation function for sparse LLMs. We will release the code to facilitate future research.
ConPET: Continual Parameter-Efficient Tuning for Large Language Models
Sep 26, 2023Continual learning necessitates the continual adaptation of models to newly emerging tasks while minimizing the catastrophic forgetting of old ones. This is extremely challenging for large language models (LLMs) with vanilla full-parameter tuning due to high computation costs, memory consumption, and forgetting issue. Inspired by the success of parameter-efficient tuning (PET), we propose Continual Parameter-Efficient Tuning (ConPET), a generalizable paradigm for continual task adaptation of LLMs with task-number-independent training complexity. ConPET includes two versions with different application scenarios. First, Static ConPET can adapt former continual learning methods originally designed for relatively smaller models to LLMs through PET and a dynamic replay strategy, which largely reduces the tuning costs and alleviates the over-fitting and forgetting issue. Furthermore, to maintain scalability, Dynamic ConPET adopts separate PET modules for different tasks and a PET module selector for dynamic optimal selection. In our extensive experiments, the adaptation of Static ConPET helps multiple former methods reduce the scale of tunable parameters by over 3,000 times and surpass the PET-only baseline by at least 5 points on five smaller benchmarks, while Dynamic ConPET gains its advantage on the largest dataset. The codes and datasets are available at https://github.com/Raincleared-Song/ConPET.