 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMutual-Supervised Learning for Sequential-to-Parallel Code Translation
Jun 11, 2025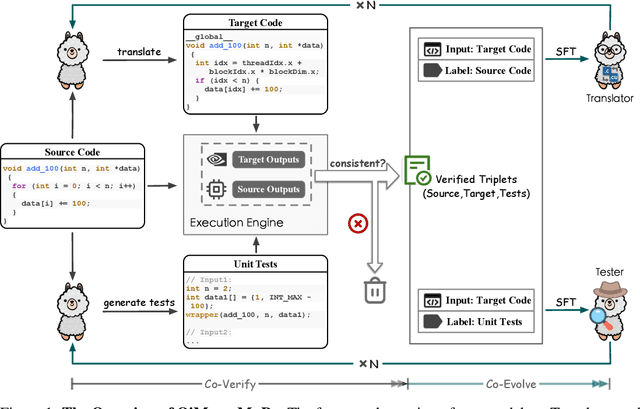
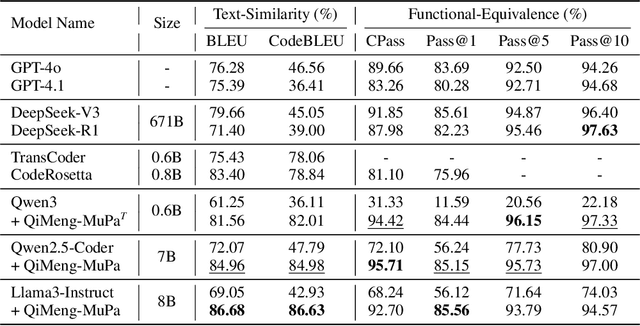
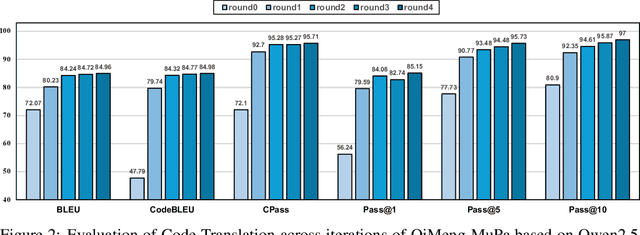
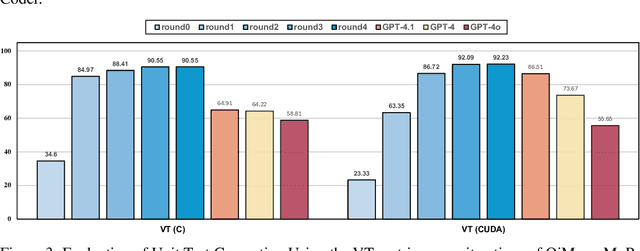
The rise of GPU-based high-performance computing (HPC) has driven the widespread adoption of parallel programming models such as CUDA. Yet, the inherent complexity of parallel programming creates a demand for the automated sequential-to-parallel approaches. However, data scarcity poses a significant challenge for machine learning-based sequential-to-parallel code translation. Although recent back-translation methods show promise, they still fail to ensure functional equivalence in the translated code. In this paper, we propose a novel Mutual-Supervised Learning (MSL) framework for sequential-to-parallel code translation to address the functional equivalence issue. MSL consists of two models, a Translator and a Tester. Through an iterative loop consisting of Co-verify and Co-evolve steps, the Translator and the Tester mutually generate data for each other and improve collectively. The Tester generates unit tests to verify and filter functionally equivalent translated code, thereby evolving the Translator, while the Translator generates translated code as augmented input to evolve the Tester. Experimental results demonstrate that MuSL significantly enhances the performance of the base model: when applied to Qwen2.5-Coder, it not only improves Pass@1 by up to 28.91% and boosts Tester performance by 68.90%, but also outperforms the previous state-of-the-art method CodeRosetta by 1.56 and 6.92 in BLEU and CodeBLEU scores, while achieving performance comparable to DeepSeek-R1 and GPT-4.1. Our code is available at https://github.com/kcxain/musl.
Dual Prototyping with Domain and Class Prototypes for Affective Brain-Computer Interface in Unseen Target Conditions
Nov 27, 2024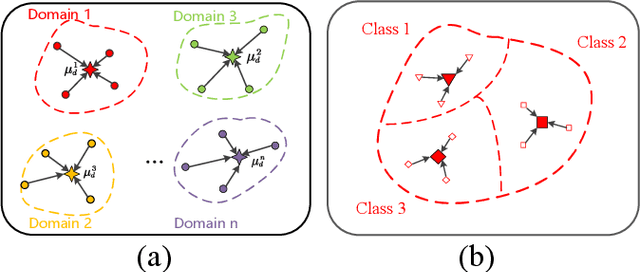
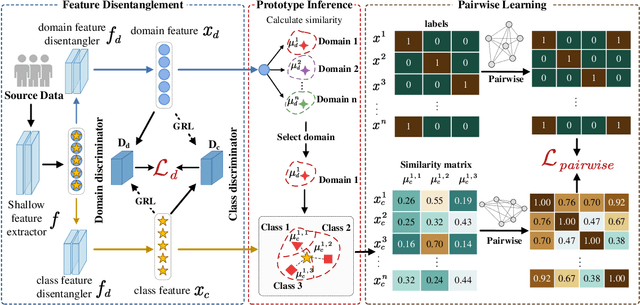
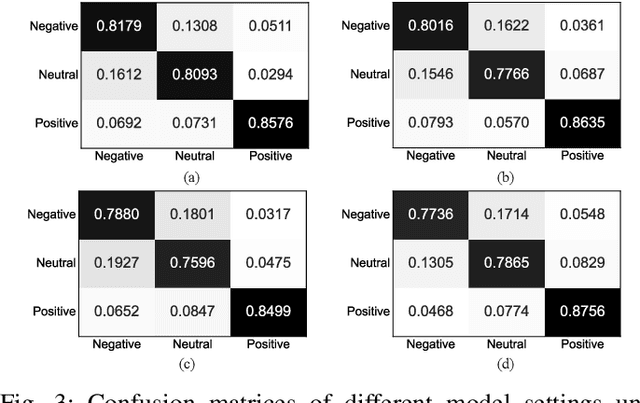
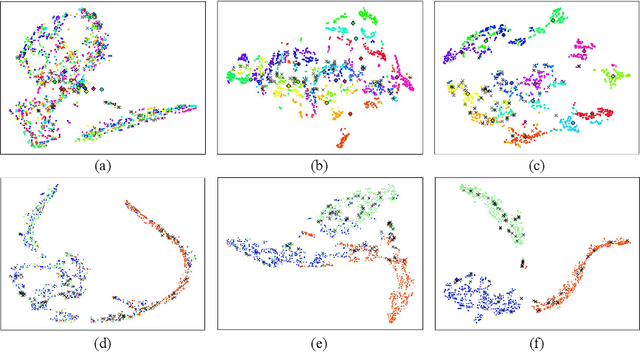
EEG signals have emerged as a powerful tool in affective brain-computer interfaces, playing a crucial role in emotion recognition. However, current deep transfer learning-based methods for EEG recognition face challenges due to the reliance of both source and target data in model learning, which significantly affect model performance and generalization. To overcome this limitation, we propose a novel framework (PL-DCP) and introduce the concepts of feature disentanglement and prototype inference. The dual prototyping mechanism incorporates both domain and class prototypes: domain prototypes capture individual variations across subjects, while class prototypes represent the ideal class distributions within their respective domains. Importantly, the proposed PL-DCP framework operates exclusively with source data during training, meaning that target data remains completely unseen throughout the entire process. To address label noise, we employ a pairwise learning strategy that encodes proximity relationships between sample pairs, effectively reducing the influence of mislabeled data. Experimental validation on the SEED and SEED-IV datasets demonstrates that PL-DCP, despite not utilizing target data during training, achieves performance comparable to deep transfer learning methods that require both source and target data. This highlights the potential of PL-DCP as an effective and robust approach for EEG-based emotion recognition.
ProSparse: Introducing and Enhancing Intrinsic Activation Sparsity within Large Language Models
Feb 27, 2024Activation sparsity refers to the existence of considerable weakly-contributed elements among activation outputs. As a prevalent property of the models using the ReLU activation function, it has been proven a promising paradigm to boost model inference efficiency. Nevertheless, most large language models (LLMs) adopt activation functions without intrinsic activation sparsity (e.g., GELU and Swish). Some recent efforts have explored introducing ReLU or its variants as the substitutive activation function to help LLMs achieve activation sparsity and inference acceleration, but few can simultaneously obtain high sparsity and comparable model performance. This paper introduces an effective sparsification method named "ProSparse" to push LLMs for higher activation sparsity without decreasing model performance. Specifically, after substituting the activation function of LLMs with ReLU, ProSparse adopts progressive sparsity regularization with a factor smoothly increasing along sine curves in multiple stages. This can enhance activation sparsity and alleviate performance degradation by avoiding radical shifts in activation distribution. With ProSparse, we obtain high sparsity of 89.32% and 88.80% for LLaMA2-7B and LLaMA2-13B, respectively, achieving comparable performance to their original Swish-activated versions. Our inference acceleration experiments further demonstrate the practical acceleration brought by higher activation sparsity.
Pinpointing the Memory Behaviors of DNN Training
Apr 01, 2021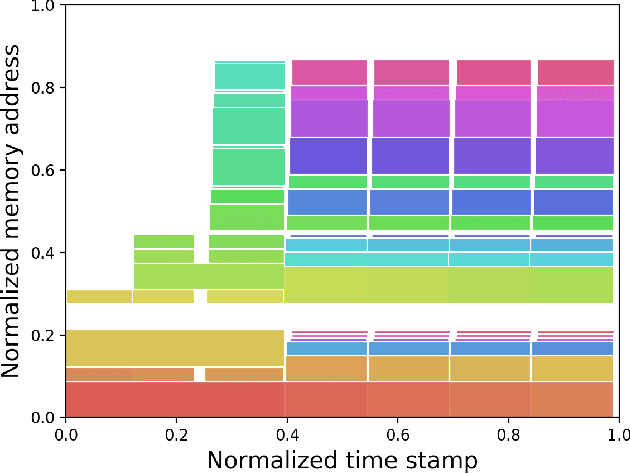
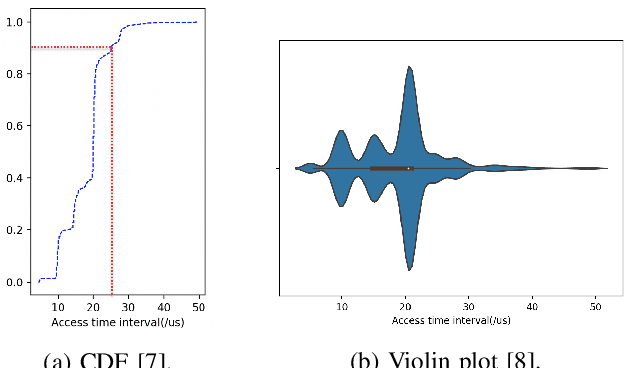
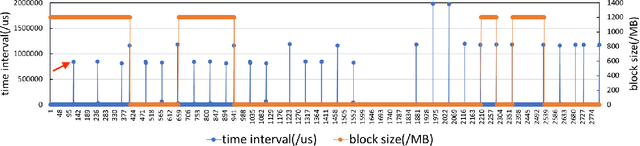
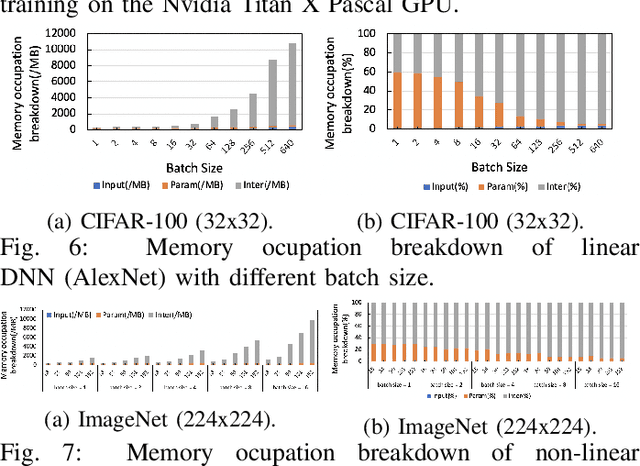
The training of deep neural networks (DNNs) is usually memory-hungry due to the limited device memory capacity of DNN accelerators. Characterizing the memory behaviors of DNN training is critical to optimize the device memory pressures. In this work, we pinpoint the memory behaviors of each device memory block of GPU during training by instrumenting the memory allocators of the runtime system. Our results show that the memory access patterns of device memory blocks are stable and follow an iterative fashion. These observations are useful for the future optimization of memory-efficient training from the perspective of raw memory access patterns.
Fusion-Catalyzed Pruning for Optimizing Deep Learning on Intelligent Edge Devices
Oct 30, 2020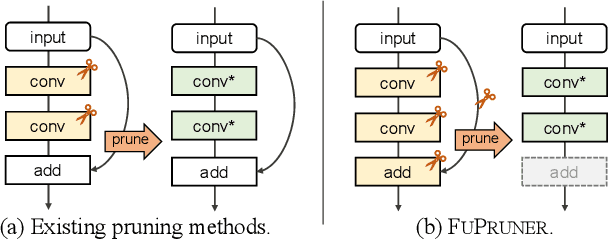

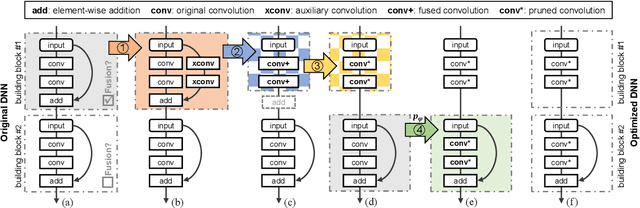
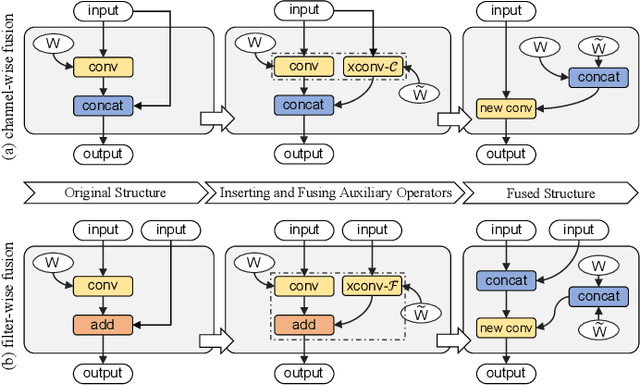
The increasing computational cost of deep neural network models limits the applicability of intelligent applications on resource-constrained edge devices. While a number of neural network pruning methods have been proposed to compress the models, prevailing approaches focus only on parametric operators (e.g., convolution), which may miss optimization opportunities. In this paper, we present a novel fusion-catalyzed pruning approach, called FuPruner, which simultaneously optimizes the parametric and non-parametric operators for accelerating neural networks. We introduce an aggressive fusion method to equivalently transform a model, which extends the optimization space of pruning and enables non-parametric operators to be pruned in a similar manner as parametric operators, and a dynamic filter pruning method is applied to decrease the computational cost of models while retaining the accuracy requirement. Moreover, FuPruner provides configurable optimization options for controlling fusion and pruning, allowing much more flexible performance-accuracy trade-offs to be made. Evaluation with state-of-the-art residual neural networks on five representative intelligent edge platforms, Jetson TX2, Jetson Nano, Edge TPU, NCS, and NCS2, demonstrates the effectiveness of our approach, which can accelerate the inference of models on CIFAR-10 and ImageNet datasets.
LANCE: Efficient Low-Precision Quantized Winograd Convolution for Neural Networks Based on Graphics Processing Units
Mar 20, 2020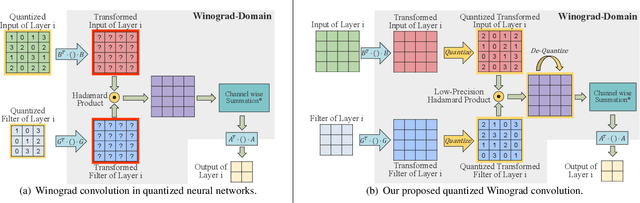

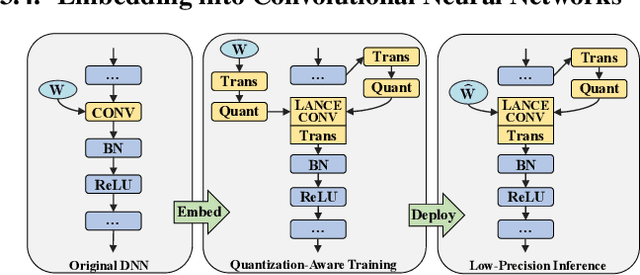
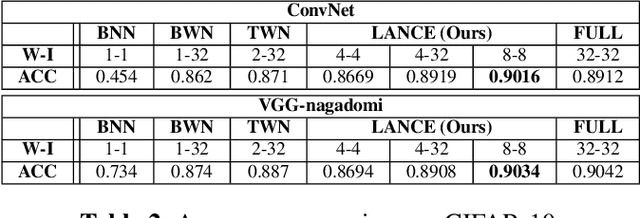
Accelerating deep convolutional neural networks has become an active topic and sparked an interest in academia and industry. In this paper, we propose an efficient low-precision quantized Winograd convolution algorithm, called LANCE, which combines the advantages of fast convolution and quantization techniques. By embedding linear quantization operations into the Winograd-domain, the fast convolution can be performed efficiently under low-precision computation on graphics processing units. We test neural network models with LANCE on representative image classification datasets, including SVHN, CIFAR, and ImageNet. The experimental results show that our 8-bit quantized Winograd convolution improves the performance by up to 2.40x over the full-precision convolution with trivial accuracy loss.
Background subtraction on depth videos with convolutional neural networks
Jan 17, 2019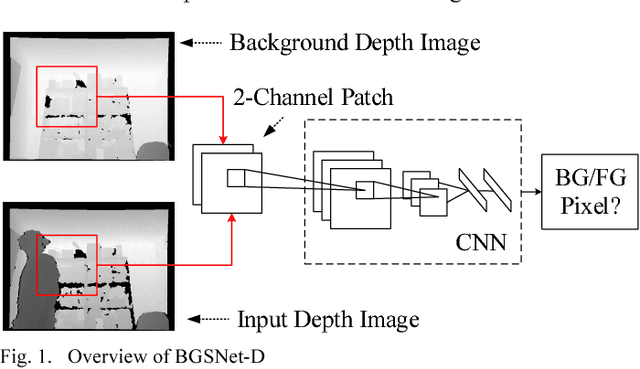
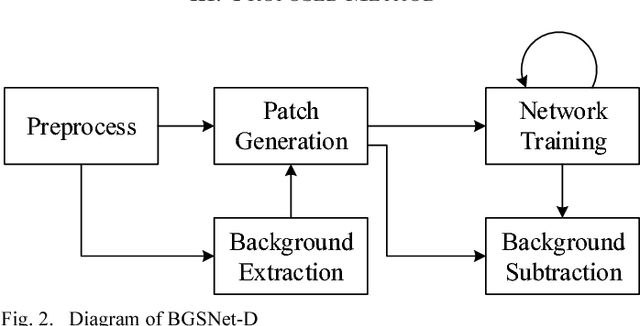


Background subtraction is a significant component of computer vision systems. It is widely used in video surveillance, object tracking, anomaly detection, etc. A new data source for background subtraction appeared as the emergence of low-cost depth sensors like Microsof t Kinect, Asus Xtion PRO, etc. In this paper, we propose a background subtraction approach on depth videos, which is based on convolutional neural networks (CNNs), called BGSNet-D (BackGround Subtraction neural Networks for Depth videos). The method can be used in color unavailable scenarios like poor lighting situations, and can also be applied to combine with existing RGB background subtraction methods. A preprocessing strategy is designed to reduce the influences incurred by noise from depth sensors. The experimental results on the SBM-RGBD dataset show that the proposed method outperforms existing methods on depth data.
Auto-tuning Neural Network Quantization Framework for Collaborative Inference Between the Cloud and Edge
Dec 16, 2018
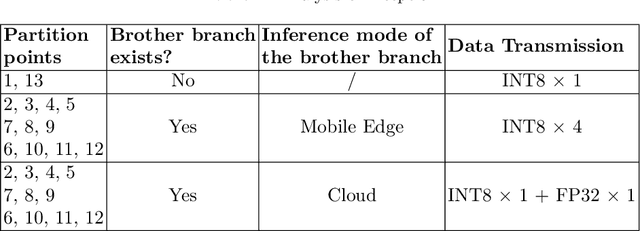
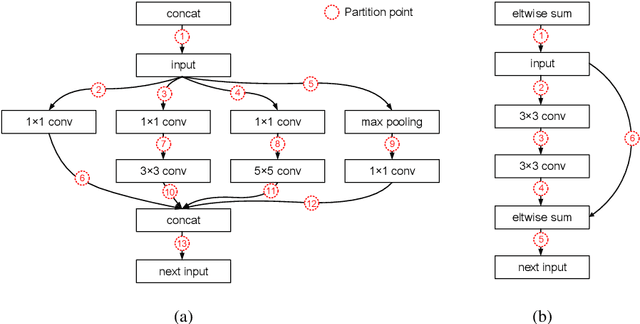

Recently, deep neural networks (DNNs) have been widely applied in mobile intelligent applications. The inference for the DNNs is usually performed in the cloud. However, it leads to a large overhead of transmitting data via wireless network. In this paper, we demonstrate the advantages of the cloud-edge collaborative inference with quantization. By analyzing the characteristics of layers in DNNs, an auto-tuning neural network quantization framework for collaborative inference is proposed. We study the effectiveness of mixed-precision collaborative inference of state-of-the-art DNNs by using ImageNet dataset. The experimental results show that our framework can generate reasonable network partitions and reduce the storage on mobile devices with trivial loss of accuracy.