 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe New Compiler Stack: A Survey on the Synergy of LLMs and Compilers
Jan 05, 2026This survey has provided a systematic overview of the emerging field of LLM-enabled compilation by addressing several key research questions. We first answered how LLMs are being integrated by proposing a comprehensive, multi-dimensional taxonomy that categorizes works based on their Design Philosophy (Selector, Translator, Generator), LLM Methodology, their operational Level of Code Abstraction, and the specific Task Type they address. In answering what advancements these approaches offer, we identified three primary benefits: the democratization of compiler development, the discovery of novel optimization strategies, and the broadening of the compiler's traditional scope. Finally, in addressing the field's challenges and opportunities, we highlighted the critical hurdles of ensuring correctness and achieving scalability, while identifying the development of hybrid systems as the most promising path forward. By providing these answers, this survey serves as a foundational roadmap for researchers and practitioners, charting the course for a new generation of LLM-powered, intelligent, adaptive and synergistic compilation tools.
LEGO-Compiler: Enhancing Neural Compilation Through Translation Composability
May 26, 2025Large language models (LLMs) have the potential to revolutionize how we design and implement compilers and code translation tools. However, existing LLMs struggle to handle long and complex programs. We introduce LEGO-Compiler, a novel neural compilation system that leverages LLMs to translate high-level languages into assembly code. Our approach centers on three key innovations: LEGO translation, which decomposes the input program into manageable blocks; breaking down the complex compilation process into smaller, simpler verifiable steps by organizing it as a verifiable LLM workflow by external tests; and a feedback mechanism for self-correction. Supported by formal proofs of translation composability, LEGO-Compiler demonstrates high accuracy on multiple datasets, including over 99% on ExeBench and 97.9% on industrial-grade AnsiBench. Additionally, LEGO-Compiler has also acheived near one order-of-magnitude improvement on compilable code size scalability. This work opens new avenues for applying LLMs to system-level tasks, complementing traditional compiler technologies.
Output Constraints as Attack Surface: Exploiting Structured Generation to Bypass LLM Safety Mechanisms
Mar 31, 2025Content Warning: This paper may contain unsafe or harmful content generated by LLMs that may be offensive to readers. Large Language Models (LLMs) are extensively used as tooling platforms through structured output APIs to ensure syntax compliance so that robust integration with existing softwares like agent systems, could be achieved. However, the feature enabling functionality of grammar-guided structured output presents significant security vulnerabilities. In this work, we reveal a critical control-plane attack surface orthogonal to traditional data-plane vulnerabilities. We introduce Constrained Decoding Attack (CDA), a novel jailbreak class that weaponizes structured output constraints to bypass safety mechanisms. Unlike prior attacks focused on input prompts, CDA operates by embedding malicious intent in schema-level grammar rules (control-plane) while maintaining benign surface prompts (data-plane). We instantiate this with a proof-of-concept Chain Enum Attack, achieves 96.2% attack success rates across proprietary and open-weight LLMs on five safety benchmarks with a single query, including GPT-4o and Gemini-2.0-flash. Our findings identify a critical security blind spot in current LLM architectures and urge a paradigm shift in LLM safety to address control-plane vulnerabilities, as current mechanisms focused solely on data-plane threats leave critical systems exposed.
M4: Multi-Proxy Multi-Gate Mixture of Experts Network for Multiple Instance Learning in Histopathology Image Analysis
Jul 24, 2024



Multiple instance learning (MIL) has been successfully applied for whole slide images (WSIs) analysis in computational pathology, enabling a wide range of prediction tasks from tumor subtyping to inferring genetic mutations and multi-omics biomarkers. However, existing MIL methods predominantly focus on single-task learning, resulting in not only overall low efficiency but also the overlook of inter-task relatedness. To address these issues, we proposed an adapted architecture of Multi-gate Mixture-of-experts with Multi-proxy for Multiple instance learning (M4), and applied this framework for simultaneous prediction of multiple genetic mutations from WSIs. The proposed M4 model has two main innovations: (1) utilizing a mixture of experts with multiple gating strategies for multi-genetic mutation prediction on a single pathological slide; (2) constructing multi-proxy expert network and gate network for comprehensive and effective modeling of pathological image information. Our model achieved significant improvements across five tested TCGA datasets in comparison to current state-of-the-art single-task methods. The code is available at:https://github.com/Bigyehahaha/M4.
A practical framework for multi-domain speech recognition and an instance sampling method to neural language modeling
Mar 09, 2022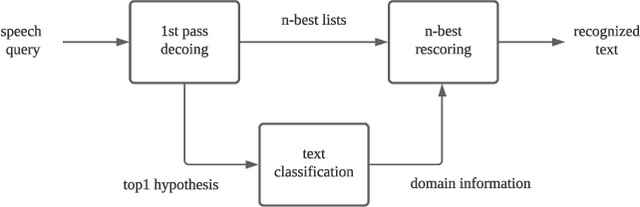


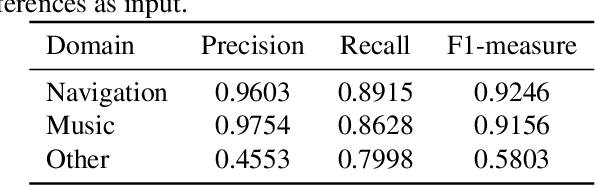
Automatic speech recognition (ASR) systems used on smart phones or vehicles are usually required to process speech queries from very different domains. In such situations, a vanilla ASR system usually fails to perform well on every domain. This paper proposes a multi-domain ASR framework for Tencent Map, a navigation app used on smart phones and in-vehicle infotainment systems. The proposed framework consists of three core parts: a basic ASR module to generate n-best lists of a speech query, a text classification module to determine which domain the speech query belongs to, and a reranking module to rescore n-best lists using domain-specific language models. In addition, an instance sampling based method to training neural network language models (NNLMs) is proposed to address the data imbalance problem in multi-domain ASR. In experiments, the proposed framework was evaluated on navigation domain and music domain, since navigating and playing music are two main features of Tencent Map. Compared to a general ASR system, the proposed framework achieves a relative 13% $\sim$ 22% character error rate reduction on several test sets collected from Tencent Map and our in-car voice assistant.
Improving Speech Recognition Accuracy of Local POI Using Geographical Models
Jul 07, 2021



Nowadays voice search for points of interest (POI) is becoming increasingly popular. However, speech recognition for local POI has remained to be a challenge due to multi-dialect and massive POI. This paper improves speech recognition accuracy for local POI from two aspects. Firstly, a geographic acoustic model (Geo-AM) is proposed. The Geo-AM deals with multi-dialect problem using dialect-specific input feature and dialect-specific top layer. Secondly, a group of geo-specific language models (Geo-LMs) are integrated into our speech recognition system to improve recognition accuracy of long tail and homophone POI. During decoding, specific language models are selected on demand according to users' geographic location. Experiments show that the proposed Geo-AM achieves 6.5%$\sim$10.1% relative character error rate (CER) reduction on an accent testset and the proposed Geo-AM and Geo-LM totally achieve over 18.7% relative CER reduction on Tencent Map task.
Pinpointing the Memory Behaviors of DNN Training
Apr 01, 2021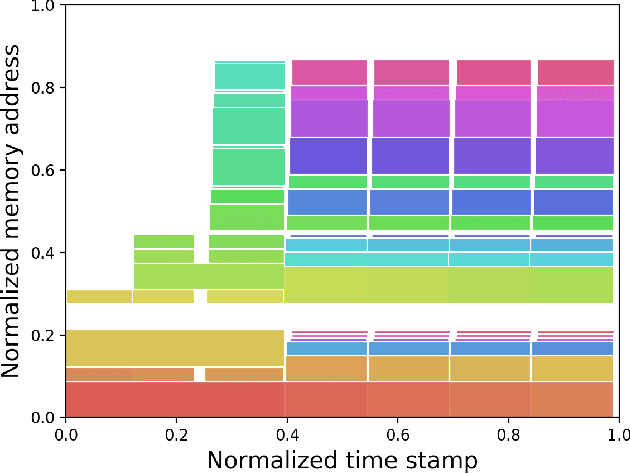
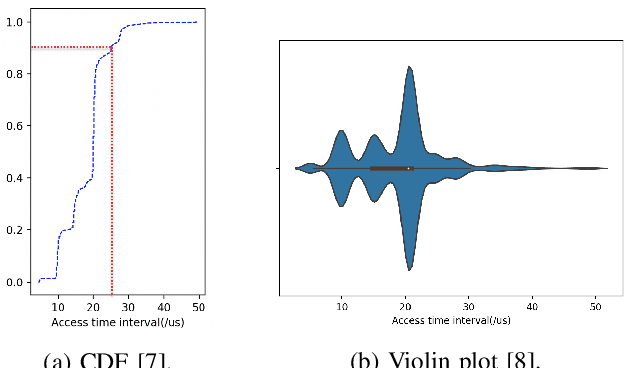
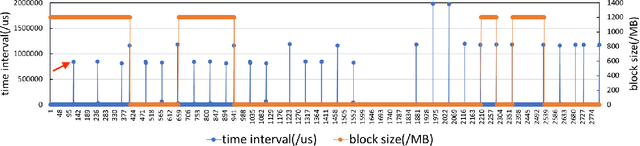
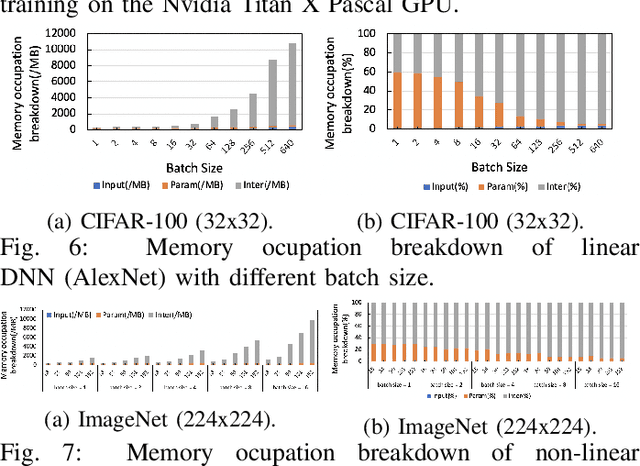
The training of deep neural networks (DNNs) is usually memory-hungry due to the limited device memory capacity of DNN accelerators. Characterizing the memory behaviors of DNN training is critical to optimize the device memory pressures. In this work, we pinpoint the memory behaviors of each device memory block of GPU during training by instrumenting the memory allocators of the runtime system. Our results show that the memory access patterns of device memory blocks are stable and follow an iterative fashion. These observations are useful for the future optimization of memory-efficient training from the perspective of raw memory access patterns.
Fusion-Catalyzed Pruning for Optimizing Deep Learning on Intelligent Edge Devices
Oct 30, 2020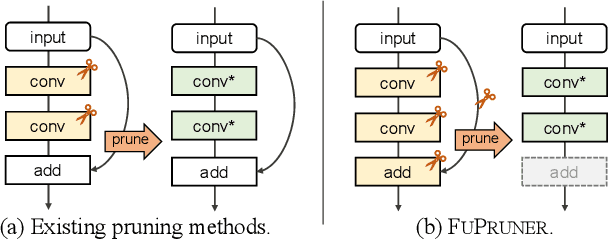

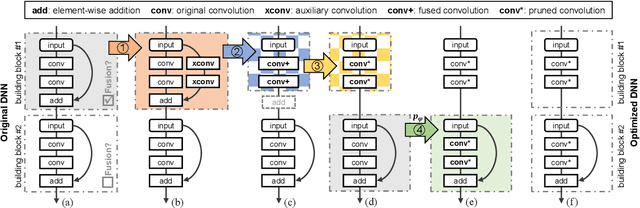
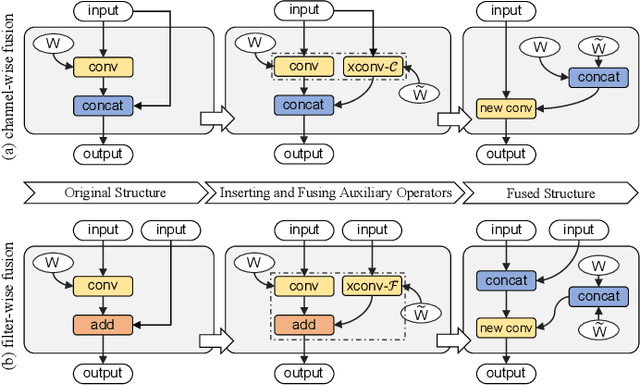
The increasing computational cost of deep neural network models limits the applicability of intelligent applications on resource-constrained edge devices. While a number of neural network pruning methods have been proposed to compress the models, prevailing approaches focus only on parametric operators (e.g., convolution), which may miss optimization opportunities. In this paper, we present a novel fusion-catalyzed pruning approach, called FuPruner, which simultaneously optimizes the parametric and non-parametric operators for accelerating neural networks. We introduce an aggressive fusion method to equivalently transform a model, which extends the optimization space of pruning and enables non-parametric operators to be pruned in a similar manner as parametric operators, and a dynamic filter pruning method is applied to decrease the computational cost of models while retaining the accuracy requirement. Moreover, FuPruner provides configurable optimization options for controlling fusion and pruning, allowing much more flexible performance-accuracy trade-offs to be made. Evaluation with state-of-the-art residual neural networks on five representative intelligent edge platforms, Jetson TX2, Jetson Nano, Edge TPU, NCS, and NCS2, demonstrates the effectiveness of our approach, which can accelerate the inference of models on CIFAR-10 and ImageNet datasets.
LANCE: Efficient Low-Precision Quantized Winograd Convolution for Neural Networks Based on Graphics Processing Units
Mar 20, 2020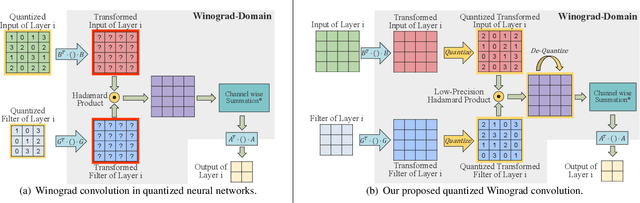

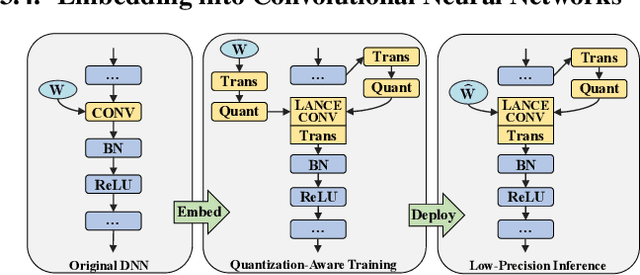
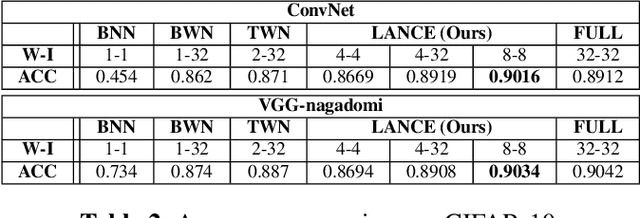
Accelerating deep convolutional neural networks has become an active topic and sparked an interest in academia and industry. In this paper, we propose an efficient low-precision quantized Winograd convolution algorithm, called LANCE, which combines the advantages of fast convolution and quantization techniques. By embedding linear quantization operations into the Winograd-domain, the fast convolution can be performed efficiently under low-precision computation on graphics processing units. We test neural network models with LANCE on representative image classification datasets, including SVHN, CIFAR, and ImageNet. The experimental results show that our 8-bit quantized Winograd convolution improves the performance by up to 2.40x over the full-precision convolution with trivial accuracy loss.
Background subtraction on depth videos with convolutional neural networks
Jan 17, 2019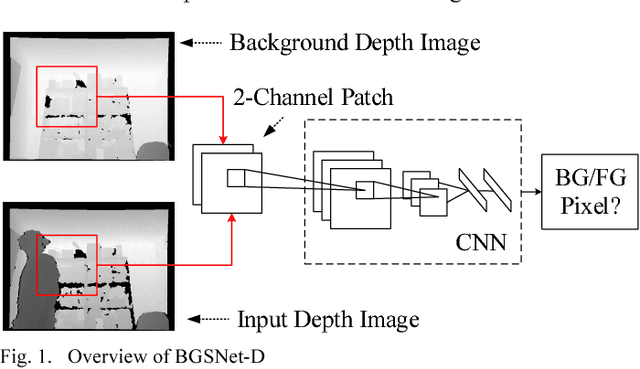
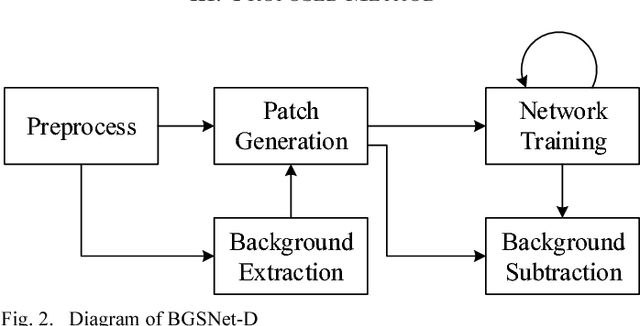


Background subtraction is a significant component of computer vision systems. It is widely used in video surveillance, object tracking, anomaly detection, etc. A new data source for background subtraction appeared as the emergence of low-cost depth sensors like Microsof t Kinect, Asus Xtion PRO, etc. In this paper, we propose a background subtraction approach on depth videos, which is based on convolutional neural networks (CNNs), called BGSNet-D (BackGround Subtraction neural Networks for Depth videos). The method can be used in color unavailable scenarios like poor lighting situations, and can also be applied to combine with existing RGB background subtraction methods. A preprocessing strategy is designed to reduce the influences incurred by noise from depth sensors. The experimental results on the SBM-RGBD dataset show that the proposed method outperforms existing methods on depth data.