 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFusion-Catalyzed Pruning for Optimizing Deep Learning on Intelligent Edge Devices
Oct 30, 2020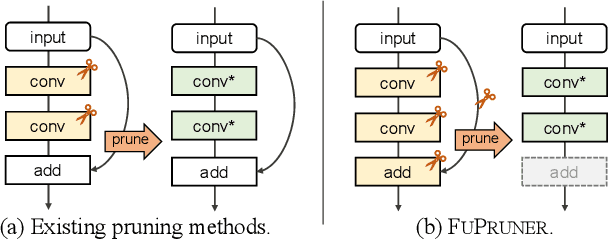

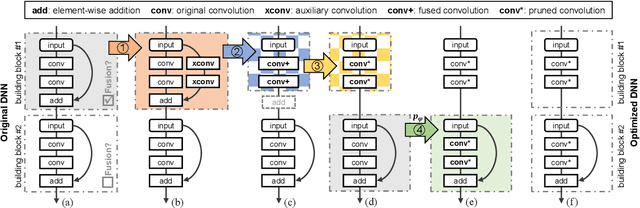
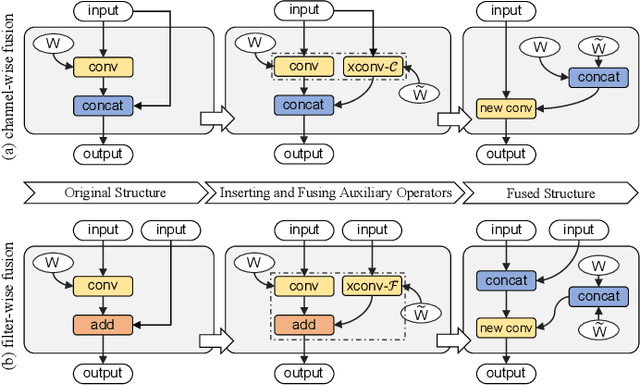
The increasing computational cost of deep neural network models limits the applicability of intelligent applications on resource-constrained edge devices. While a number of neural network pruning methods have been proposed to compress the models, prevailing approaches focus only on parametric operators (e.g., convolution), which may miss optimization opportunities. In this paper, we present a novel fusion-catalyzed pruning approach, called FuPruner, which simultaneously optimizes the parametric and non-parametric operators for accelerating neural networks. We introduce an aggressive fusion method to equivalently transform a model, which extends the optimization space of pruning and enables non-parametric operators to be pruned in a similar manner as parametric operators, and a dynamic filter pruning method is applied to decrease the computational cost of models while retaining the accuracy requirement. Moreover, FuPruner provides configurable optimization options for controlling fusion and pruning, allowing much more flexible performance-accuracy trade-offs to be made. Evaluation with state-of-the-art residual neural networks on five representative intelligent edge platforms, Jetson TX2, Jetson Nano, Edge TPU, NCS, and NCS2, demonstrates the effectiveness of our approach, which can accelerate the inference of models on CIFAR-10 and ImageNet datasets.
LANCE: Efficient Low-Precision Quantized Winograd Convolution for Neural Networks Based on Graphics Processing Units
Mar 20, 2020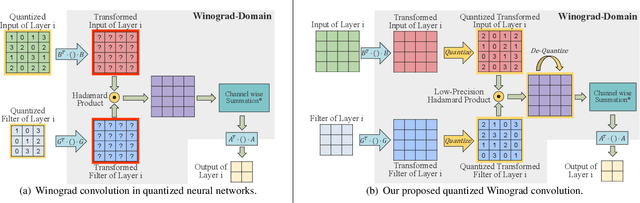

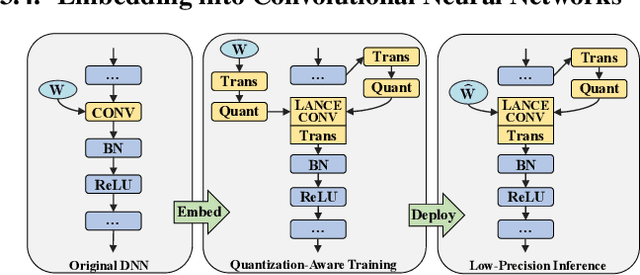
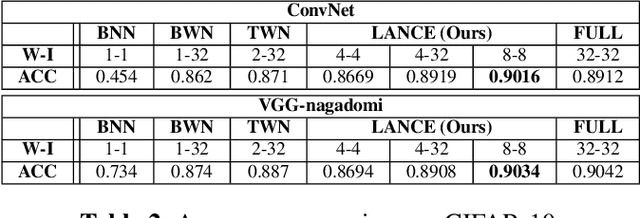
Accelerating deep convolutional neural networks has become an active topic and sparked an interest in academia and industry. In this paper, we propose an efficient low-precision quantized Winograd convolution algorithm, called LANCE, which combines the advantages of fast convolution and quantization techniques. By embedding linear quantization operations into the Winograd-domain, the fast convolution can be performed efficiently under low-precision computation on graphics processing units. We test neural network models with LANCE on representative image classification datasets, including SVHN, CIFAR, and ImageNet. The experimental results show that our 8-bit quantized Winograd convolution improves the performance by up to 2.40x over the full-precision convolution with trivial accuracy loss.