 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProbing the Critical Point (CritPt) of AI Reasoning: a Frontier Physics Research Benchmark
Oct 01, 2025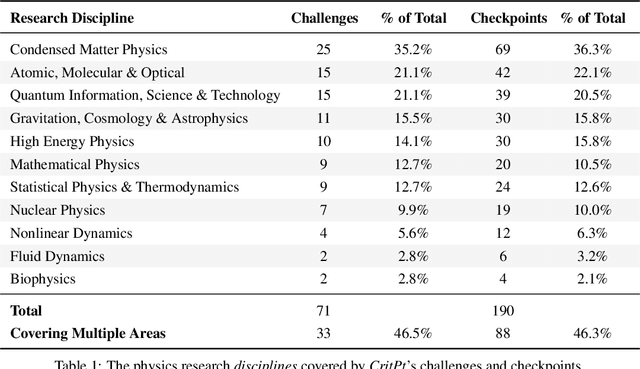
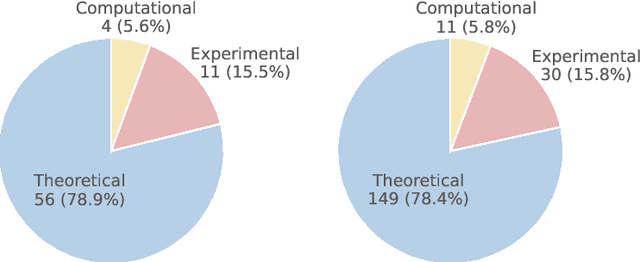
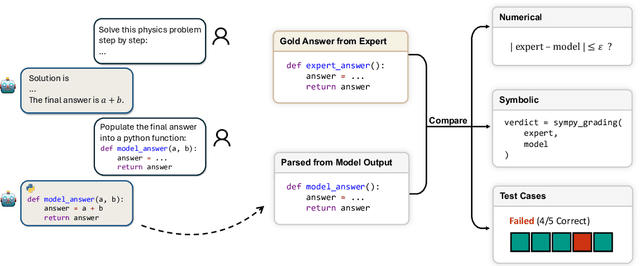

While large language models (LLMs) with reasoning capabilities are progressing rapidly on high-school math competitions and coding, can they reason effectively through complex, open-ended challenges found in frontier physics research? And crucially, what kinds of reasoning tasks do physicists want LLMs to assist with? To address these questions, we present the CritPt (Complex Research using Integrated Thinking - Physics Test, pronounced "critical point"), the first benchmark designed to test LLMs on unpublished, research-level reasoning tasks that broadly covers modern physics research areas, including condensed matter, quantum physics, atomic, molecular & optical physics, astrophysics, high energy physics, mathematical physics, statistical physics, nuclear physics, nonlinear dynamics, fluid dynamics and biophysics. CritPt consists of 71 composite research challenges designed to simulate full-scale research projects at the entry level, which are also decomposed to 190 simpler checkpoint tasks for more fine-grained insights. All problems are newly created by 50+ active physics researchers based on their own research. Every problem is hand-curated to admit a guess-resistant and machine-verifiable answer and is evaluated by an automated grading pipeline heavily customized for advanced physics-specific output formats. We find that while current state-of-the-art LLMs show early promise on isolated checkpoints, they remain far from being able to reliably solve full research-scale challenges: the best average accuracy among base models is only 4.0% , achieved by GPT-5 (high), moderately rising to around 10% when equipped with coding tools. Through the realistic yet standardized evaluation offered by CritPt, we highlight a large disconnect between current model capabilities and realistic physics research demands, offering a foundation to guide the development of scientifically grounded AI tools.
PDeepPP:A Deep learning framework with Pretrained Protein language for peptide classification
Feb 21, 2025Protein post-translational modifications (PTMs) and bioactive peptides (BPs) play critical roles in various biological processes and have significant therapeutic potential. However, identifying PTM sites and bioactive peptides through experimental methods is often labor-intensive, costly, and time-consuming. As a result, computational tools, particularly those based on deep learning, have become effective solutions for predicting PTM sites and peptide bioactivity. Despite progress in this field, existing methods still struggle with the complexity of protein sequences and the challenge of requiring high-quality predictions across diverse datasets. To address these issues, we propose a deep learning framework that integrates pretrained protein language models with a neural network combining transformer and CNN for peptide classification. By leveraging the ability of pretrained models to capture complex relationships within protein sequences, combined with the predictive power of parallel networks, our approach improves feature extraction while enhancing prediction accuracy. This framework was applied to multiple tasks involving PTM site and bioactive peptide prediction, utilizing large-scale datasets to enhance the model's robustness. In the comparison across 33 tasks, the model achieved state-of-the-art (SOTA) performance in 25 of them, surpassing existing methods and demonstrating its versatility across different datasets. Our results suggest that this approach provides a scalable and effective solution for large-scale peptide discovery and PTM analysis, paving the way for more efficient peptide classification and functional annotation.
FlashSparse: Minimizing Computation Redundancy for Fast Sparse Matrix Multiplications on Tensor Cores
Dec 15, 2024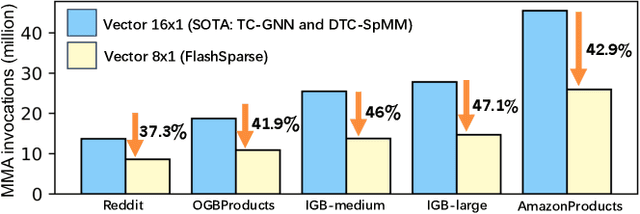

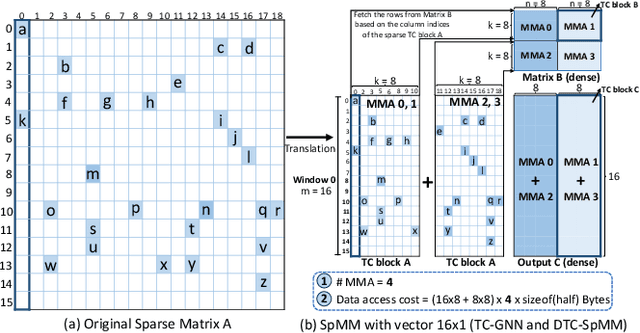

Sparse Matrix-matrix Multiplication (SpMM) and Sampled Dense-dense Matrix Multiplication (SDDMM) are important sparse operators in scientific computing and deep learning. Tensor Core Units (TCUs) enhance modern accelerators with superior computing power, which is promising to boost the performance of matrix operators to a higher level. However, due to the irregularity of unstructured sparse data, it is difficult to deliver practical speedups on TCUs. To this end, we propose FlashSparse, a novel approach to bridge the gap between sparse workloads and the TCU architecture. Specifically, FlashSparse minimizes the sparse granularity for SpMM and SDDMM on TCUs through a novel swap-and-transpose matrix multiplication strategy. Benefiting from the minimum sparse granularity, the computation redundancy is remarkably reduced while the computing power of TCUs is fully utilized. Besides, FlashSparse is equipped with a memory-efficient thread mapping strategy for coalesced data access and a sparse matrix storage format to save memory footprint. Extensive experimental results on H100 and RTX 4090 GPUs show that FlashSparse sets a new state-of-the-art for sparse matrix multiplications (geometric mean 5.5x speedup over DTC-SpMM and 3.22x speedup over RoDe).
BeSimulator: A Large Language Model Powered Text-based Behavior Simulator
Sep 24, 2024



Traditional robot simulators focus on physical process modeling and realistic rendering, often suffering from high computational costs, inefficiencies, and limited adaptability. To handle this issue, we propose Behavior Simulation in robotics to emphasize checking the behavior logic of robots and achieving sufficient alignment between the outcome of robot actions and real scenarios. In this paper, we introduce BeSimulator, a modular and novel LLM-powered framework, as an attempt towards behavior simulation in the context of text-based environments. By constructing text-based virtual environments and performing semantic-level simulation, BeSimulator can generalize across scenarios and achieve long-horizon complex simulation. Inspired by human cognition processes, it employs a "consider-decide-capture-transfer" methodology, termed Chain of Behavior Simulation, which excels at analyzing action feasibility and state transitions. Additionally, BeSimulator incorporates code-driven reasoning to enable arithmetic operations and enhance reliability, as well as integrates reflective feedback to refine simulation. Based on our manually constructed behavior-tree-based simulation benchmark BTSIMBENCH, our experiments show a significant performance improvement in behavior simulation compared to baselines, ranging from 14.7% to 26.6%.
A Study on Training and Developing Large Language Models for Behavior Tree Generation
Jan 16, 2024This paper presents an innovative exploration of the application potential of large language models (LLM) in addressing the challenging task of automatically generating behavior trees (BTs) for complex tasks. The conventional manual BT generation method is inefficient and heavily reliant on domain expertise. On the other hand, existing automatic BT generation technologies encounter bottlenecks related to task complexity, model adaptability, and reliability. In order to overcome these challenges, we propose a novel methodology that leverages the robust representation and reasoning abilities of LLMs. The core contribution of this paper lies in the design of a BT generation framework based on LLM, which encompasses the entire process, from data synthesis and model training to application developing and data verification. Synthetic data is introduced to train the BT generation model (BTGen model), enhancing its understanding and adaptability to various complex tasks, thereby significantly improving its overall performance. In order to ensure the effectiveness and executability of the generated BTs, we emphasize the importance of data verification and introduce a multilevel verification strategy. Additionally, we explore a range of agent design and development schemes with LLM as the central element. We hope that the work in this paper may provide a reference for the researchers who are interested in BT generation based on LLMs.
HeadRecon: High-Fidelity 3D Head Reconstruction from Monocular Video
Dec 14, 2023



Recently, the reconstruction of high-fidelity 3D head models from static portrait image has made great progress. However, most methods require multi-view or multi-illumination information, which therefore put forward high requirements for data acquisition. In this paper, we study the reconstruction of high-fidelity 3D head models from arbitrary monocular videos. Non-rigid structure from motion (NRSFM) methods have been widely used to solve such problems according to the two-dimensional correspondence between different frames. However, the inaccurate correspondence caused by high-complex hair structures and various facial expression changes would heavily influence the reconstruction accuracy. To tackle these problems, we propose a prior-guided dynamic implicit neural network. Specifically, we design a two-part dynamic deformation field to transform the current frame space to the canonical one. We further model the head geometry in the canonical space with a learnable signed distance field (SDF) and optimize it using the volumetric rendering with the guidance of two-main head priors to improve the reconstruction accuracy and robustness. Extensive ablation studies and comparisons with state-of-the-art methods demonstrate the effectiveness and robustness of our proposed method.
DARDet: A Dense Anchor-free Rotated Object Detector in Aerial Images
Oct 03, 2021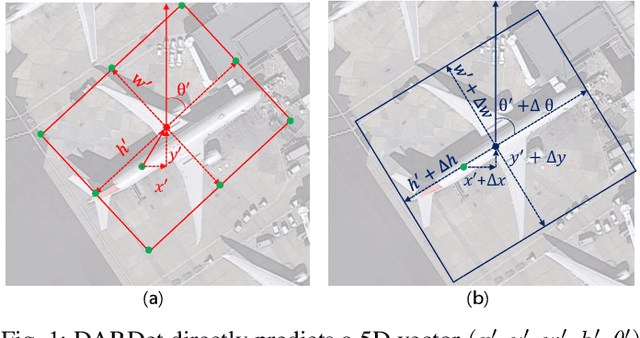
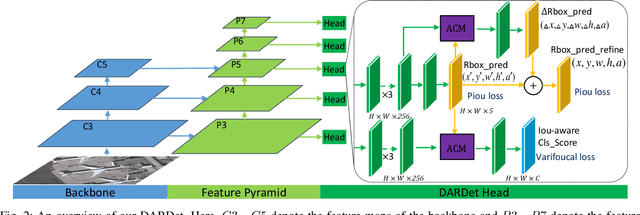
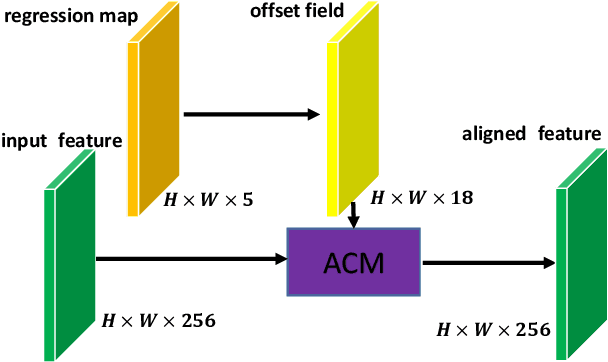
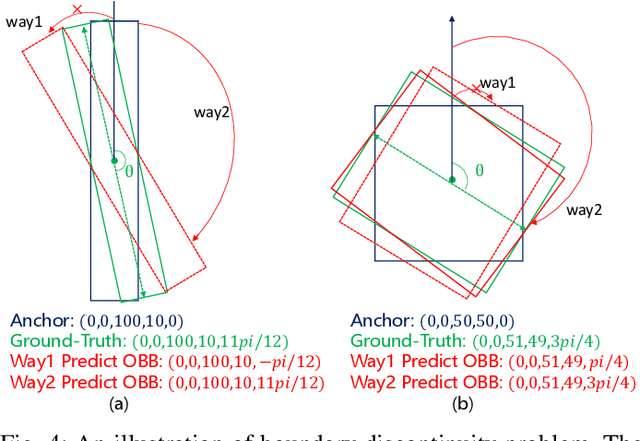
Rotated object detection in aerial images has received increasing attention for a wide range of applications. However, it is also a challenging task due to the huge variations of scale, rotation, aspect ratio, and densely arranged targets. Most existing methods heavily rely on a large number of pre-defined anchors with different scales, angles, and aspect ratios, and are optimized with a distance loss. Therefore, these methods are sensitive to anchor hyper-parameters and easily suffer from performance degradation caused by boundary discontinuity. To handle this problem, in this paper, we propose a dense anchor-free rotated object detector (DARDet) for rotated object detection in aerial images. Our DARDet directly predicts five parameters of rotated boxes at each foreground pixel of feature maps. We design a new alignment convolution module to extracts aligned features and introduce a PIoU loss for precise and stable regression. Our method achieves state-of-the-art performance on three commonly used aerial objects datasets (i.e., DOTA, HRSC2016, and UCAS-AOD) while keeping high efficiency. Code is available at https://github.com/zf020114/DARDet.
NucMM Dataset: 3D Neuronal Nuclei Instance Segmentation at Sub-Cubic Millimeter Scale
Jul 13, 2021



Segmenting 3D cell nuclei from microscopy image volumes is critical for biological and clinical analysis, enabling the study of cellular expression patterns and cell lineages. However, current datasets for neuronal nuclei usually contain volumes smaller than $10^{\text{-}3}\ mm^3$ with fewer than 500 instances per volume, unable to reveal the complexity in large brain regions and restrict the investigation of neuronal structures. In this paper, we have pushed the task forward to the sub-cubic millimeter scale and curated the NucMM dataset with two fully annotated volumes: one $0.1\ mm^3$ electron microscopy (EM) volume containing nearly the entire zebrafish brain with around 170,000 nuclei; and one $0.25\ mm^3$ micro-CT (uCT) volume containing part of a mouse visual cortex with about 7,000 nuclei. With two imaging modalities and significantly increased volume size and instance numbers, we discover a great diversity of neuronal nuclei in appearance and density, introducing new challenges to the field. We also perform a statistical analysis to illustrate those challenges quantitatively. To tackle the challenges, we propose a novel hybrid-representation learning model that combines the merits of foreground mask, contour map, and signed distance transform to produce high-quality 3D masks. The benchmark comparisons on the NucMM dataset show that our proposed method significantly outperforms state-of-the-art nuclei segmentation approaches. Code and data are available at https://connectomics-bazaar.github.io/proj/nucMM/index.html.
AxonEM Dataset: 3D Axon Instance Segmentation of Brain Cortical Regions
Jul 12, 2021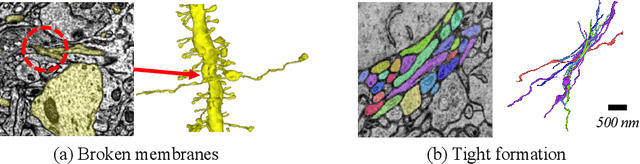

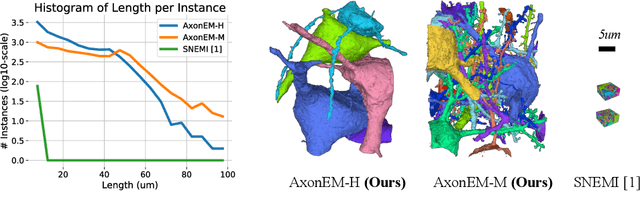

Electron microscopy (EM) enables the reconstruction of neural circuits at the level of individual synapses, which has been transformative for scientific discoveries. However, due to the complex morphology, an accurate reconstruction of cortical axons has become a major challenge. Worse still, there is no publicly available large-scale EM dataset from the cortex that provides dense ground truth segmentation for axons, making it difficult to develop and evaluate large-scale axon reconstruction methods. To address this, we introduce the AxonEM dataset, which consists of two 30x30x30 um^3 EM image volumes from the human and mouse cortex, respectively. We thoroughly proofread over 18,000 axon instances to provide dense 3D axon instance segmentation, enabling large-scale evaluation of axon reconstruction methods. In addition, we densely annotate nine ground truth subvolumes for training, per each data volume. With this, we reproduce two published state-of-the-art methods and provide their evaluation results as a baseline. We publicly release our code and data at https://connectomics-bazaar.github.io/proj/AxonEM/index.html to foster the development of advanced methods.
Prior-Guided Multi-View 3D Head Reconstruction
Jul 09, 2021



Recovering a 3D head model including the complete face and hair regions is still a challenging problem in computer vision and graphics. In this paper, we consider this problem with a few multi-view portrait images as input. Previous multi-view stereo methods, either based on the optimization strategies or deep learning techniques, suffer from low-frequency geometric structures such as unclear head structures and inaccurate reconstruction in hair regions. To tackle this problem, we propose a prior-guided implicit neural rendering network. Specifically, we model the head geometry with a learnable signed distance field (SDF) and optimize it via an implicit differentiable renderer with the guidance of some human head priors, including the facial prior knowledge, head semantic segmentation information and 2D hair orientation maps. The utilization of these priors can improve the reconstruction accuracy and robustness, leading to a high-quality integrated 3D head model. Extensive ablation studies and comparisons with state-of-the-art methods demonstrate that our method could produce high-fidelity 3D head geometries with the guidance of these priors.