 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAxonEM Dataset: 3D Axon Instance Segmentation of Brain Cortical Regions
Jul 12, 2021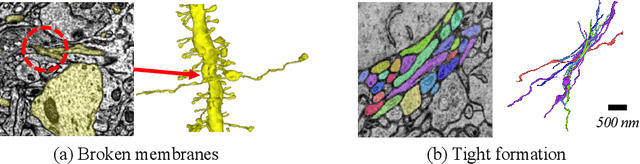

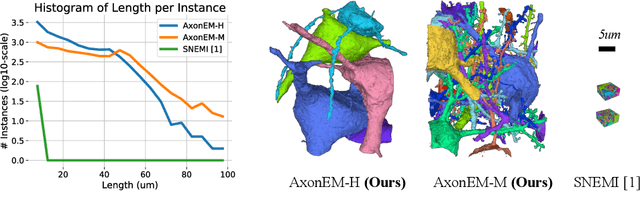

Electron microscopy (EM) enables the reconstruction of neural circuits at the level of individual synapses, which has been transformative for scientific discoveries. However, due to the complex morphology, an accurate reconstruction of cortical axons has become a major challenge. Worse still, there is no publicly available large-scale EM dataset from the cortex that provides dense ground truth segmentation for axons, making it difficult to develop and evaluate large-scale axon reconstruction methods. To address this, we introduce the AxonEM dataset, which consists of two 30x30x30 um^3 EM image volumes from the human and mouse cortex, respectively. We thoroughly proofread over 18,000 axon instances to provide dense 3D axon instance segmentation, enabling large-scale evaluation of axon reconstruction methods. In addition, we densely annotate nine ground truth subvolumes for training, per each data volume. With this, we reproduce two published state-of-the-art methods and provide their evaluation results as a baseline. We publicly release our code and data at https://connectomics-bazaar.github.io/proj/AxonEM/index.html to foster the development of advanced methods.
Learning Dense Voxel Embeddings for 3D Neuron Reconstruction
Sep 21, 2019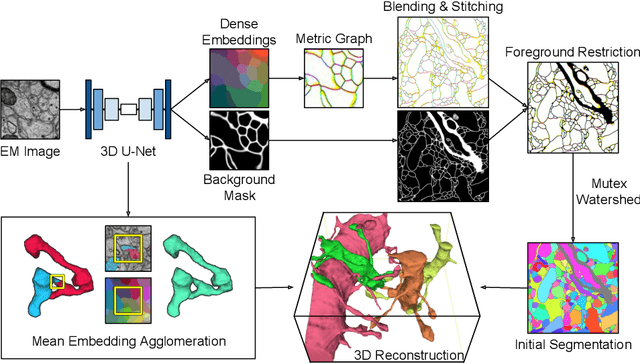
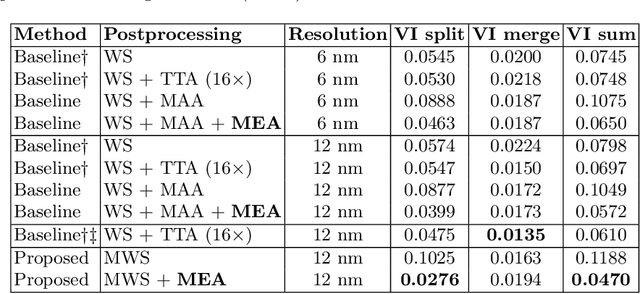

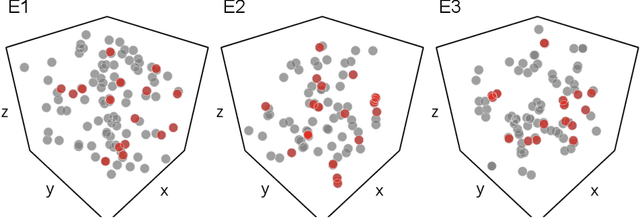
We show dense voxel embeddings learned via deep metric learning can be employed to produce a highly accurate segmentation of neurons from 3D electron microscopy images. A metric graph on an arbitrary set of short and long-range edges can be constructed from the dense embeddings generated by a convolutional network. Partitioning the metric graph with long-range affinities as repulsive constraints can produce an initial segmentation with high precision, with substantial improvements on very thin objects. The convolutional embedding net is reused without any modification to agglomerate the systematic splits caused by complex "self-touching"' objects. Our proposed method achieves state-of-the-art accuracy on the challenging problem of 3D neuron reconstruction from the brain images acquired by serial section electron microscopy. Our alternative, object-centered representation could be more generally useful for other computational tasks in automated neural circuit reconstruction.
Chunkflow: Distributed Hybrid Cloud Processing of Large 3D Images by Convolutional Nets
May 02, 2019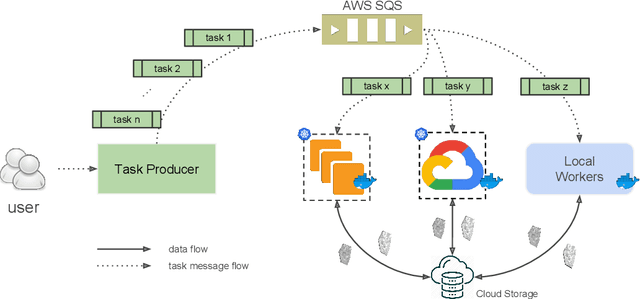
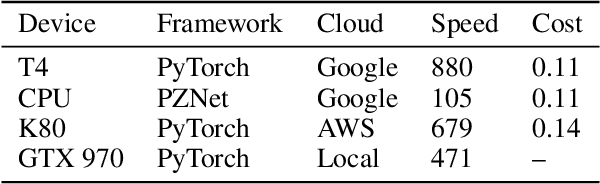
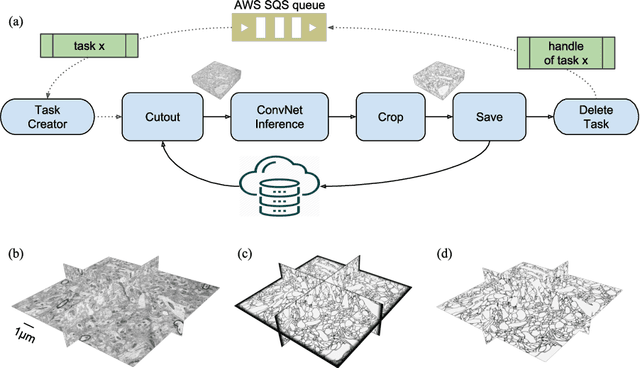
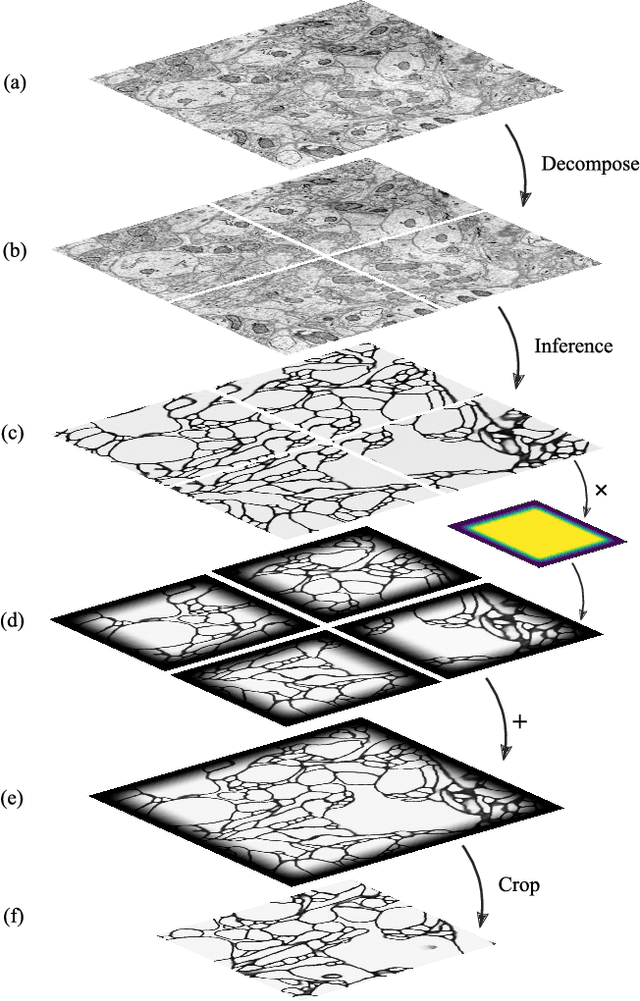
It is now common to process volumetric biomedical images using 3D Convolutional Networks (ConvNets). This can be challenging for the teravoxel and even petavoxel images that are being acquired today by light or electron microscopy. Here we introduce chunkflow, a software framework for distributing ConvNet processing over local and cloud GPUs and CPUs. The image volume is divided into overlapping chunks, each chunk is processed by a ConvNet, and the results are blended together to yield the output image. The frontend submits ConvNet tasks to a cloud queue. The tasks are executed by local and cloud GPUs and CPUs. Thanks to the fault-tolerant architecture of Chunkflow, cost can be greatly reduced by utilizing cheap unstable cloud instances. Chunkflow currently supports PyTorch for GPUs and PZnet for CPUs. To illustrate its usage, a large 3D brain image from serial section electron microscopy was processed by a 3D ConvNet with a U-Net style architecture. Chunkflow provides some chunk operations for general use, and the operations can be composed flexibly in a command line interface.
Convolutional nets for reconstructing neural circuits from brain images acquired by serial section electron microscopy
Apr 29, 2019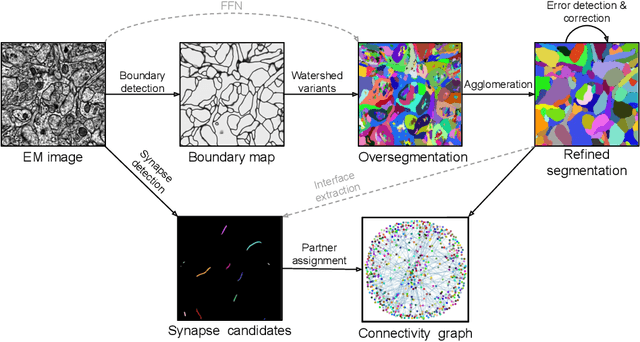
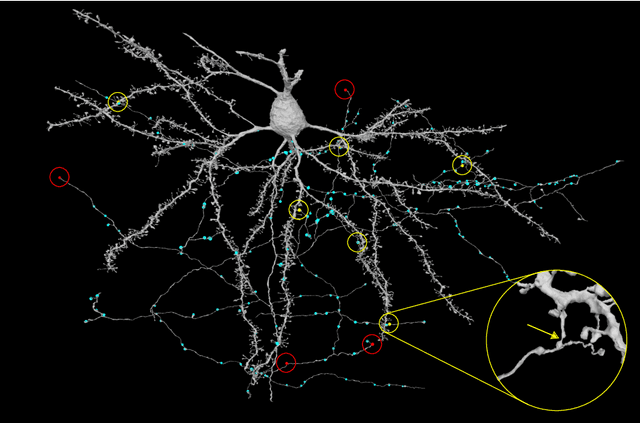

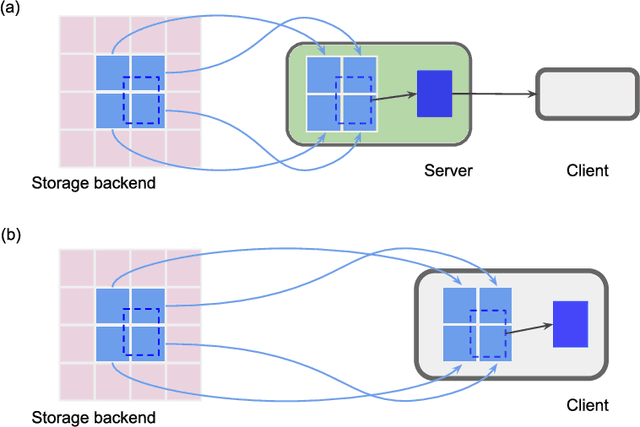
Neural circuits can be reconstructed from brain images acquired by serial section electron microscopy. Image analysis has been performed by manual labor for half a century, and efforts at automation date back almost as far. Convolutional nets were first applied to neuronal boundary detection a dozen years ago, and have now achieved impressive accuracy on clean images. Robust handling of image defects is a major outstanding challenge. Convolutional nets are also being employed for other tasks in neural circuit reconstruction: finding synapses and identifying synaptic partners, extending or pruning neuronal reconstructions, and aligning serial section images to create a 3D image stack. Computational systems are being engineered to handle petavoxel images of cubic millimeter brain volumes.
Synaptic Partner Assignment Using Attentional Voxel Association Networks
Apr 22, 2019

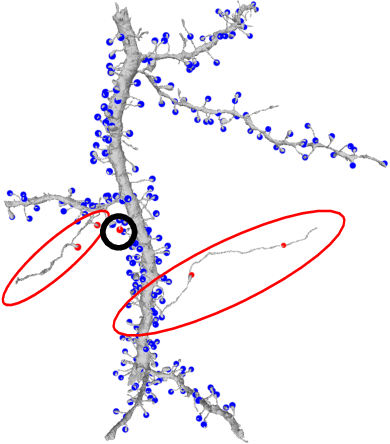
Connectomics aims to recover a complete set of synaptic connections within a dataset imaged by electron microscopy. Most systems for locating synapses use voxelwise classifier models, and train these classifiers to reproduce binary masks of synaptic clefts. However, only recent work has included a way to identify the synaptic partners that communicate at synaptic cleft segments. Here, we present a novel method for associating synaptic cleft segments with their synaptic partners using a convolutional network trained to associate the mask of a cleft with the voxels of its synaptic partners. The network takes the local image context and a mask of a single cleft segment as input. It is trained to produce two volumes of output: one which labels the voxels of the presynaptic partner within the input image, and another similar volume for the postsynaptic partner. The cleft mask acts as an attentional gating signal for the network, in that two clefts with the same local image context often have different partners. We find that an implementation of this approach performs well on a dataset of mouse somatosensory cortex, and evaluate it as part of a combined system to predict both clefts and connections.
Reconstructing neuronal anatomy from whole-brain images
Mar 17, 2019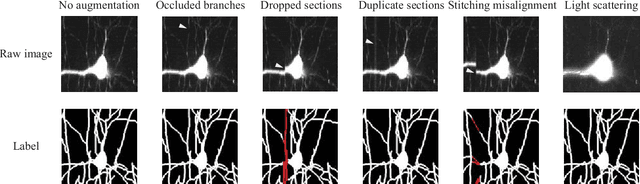
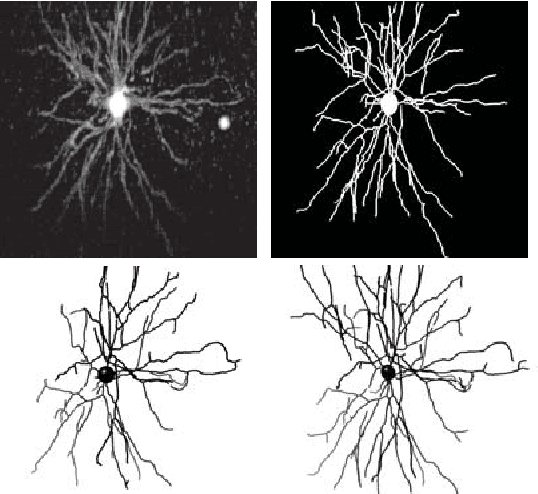
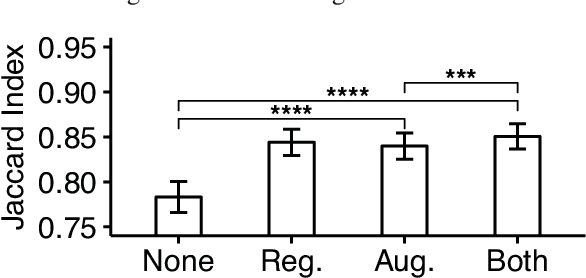
Reconstructing multiple molecularly defined neurons from individual brains and across multiple brain regions can reveal organizational principles of the nervous system. However, high resolution imaging of the whole brain is a technically challenging and slow process. Recently, oblique light sheet microscopy has emerged as a rapid imaging method that can provide whole brain fluorescence microscopy at a voxel size of 0.4 by 0.4 by 2.5 cubic microns. On the other hand, complex image artifacts due to whole-brain coverage produce apparent discontinuities in neuronal arbors. Here, we present connectivity-preserving methods and data augmentation strategies for supervised learning of neuroanatomy from light microscopy using neural networks. We quantify the merit of our approach by implementing an end-to-end automated tracing pipeline. Lastly, we demonstrate a scalable, distributed implementation that can reconstruct the large datasets that sub-micron whole-brain images produce.
An Error Detection and Correction Framework for Connectomics
Dec 03, 2017
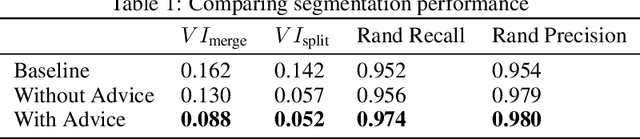

We define and study error detection and correction tasks that are useful for 3D reconstruction of neurons from electron microscopic imagery, and for image segmentation more generally. Both tasks take as input the raw image and a binary mask representing a candidate object. For the error detection task, the desired output is a map of split and merge errors in the object. For the error correction task, the desired output is the true object. We call this object mask pruning, because the candidate object mask is assumed to be a superset of the true object. We train multiscale 3D convolutional networks to perform both tasks. We find that the error-detecting net can achieve high accuracy. The accuracy of the error-correcting net is enhanced if its input object mask is "advice" (union of erroneous objects) from the error-detecting net.
Superhuman Accuracy on the SNEMI3D Connectomics Challenge
May 31, 2017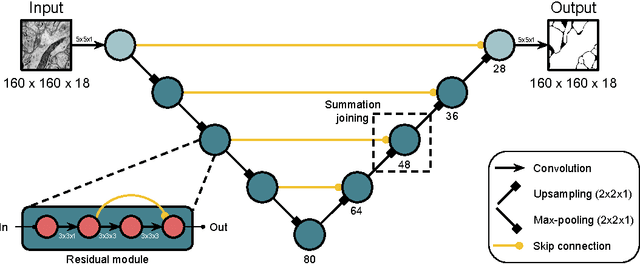
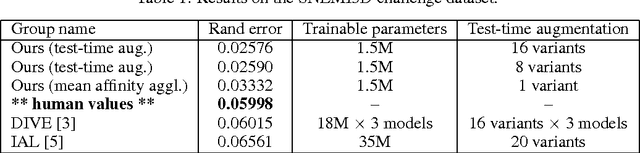
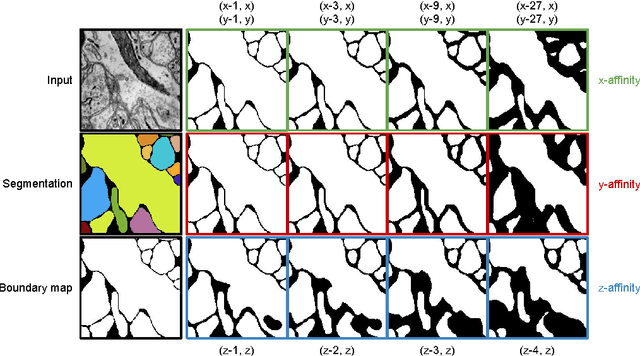
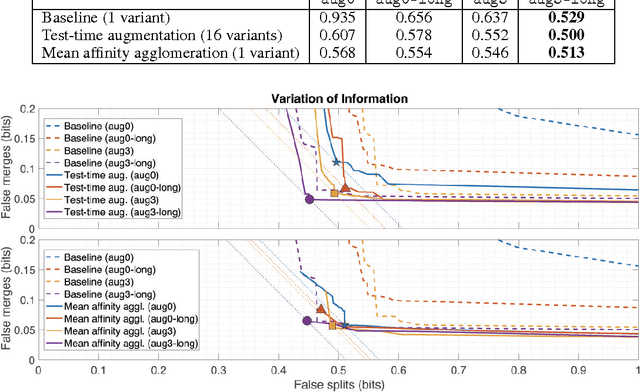
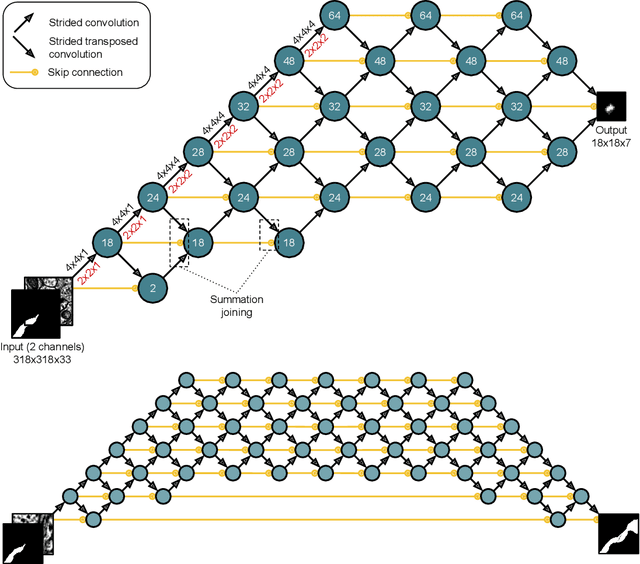
For the past decade, convolutional networks have been used for 3D reconstruction of neurons from electron microscopic (EM) brain images. Recent years have seen great improvements in accuracy, as evidenced by submissions to the SNEMI3D benchmark challenge. Here we report the first submission to surpass the estimate of human accuracy provided by the SNEMI3D leaderboard. A variant of 3D U-Net is trained on a primary task of predicting affinities between nearest neighbor voxels, and an auxiliary task of predicting long-range affinities. The training data is augmented by simulated image defects. The nearest neighbor affinities are used to create an oversegmentation, and then supervoxels are greedily agglomerated based on mean affinity. The resulting SNEMI3D score exceeds the estimate of human accuracy by a large margin. While one should be cautious about extrapolating from the SNEMI3D benchmark to real-world accuracy of large-scale neural circuit reconstruction, our result inspires optimism that the goal of full automation may be realizable in the future.
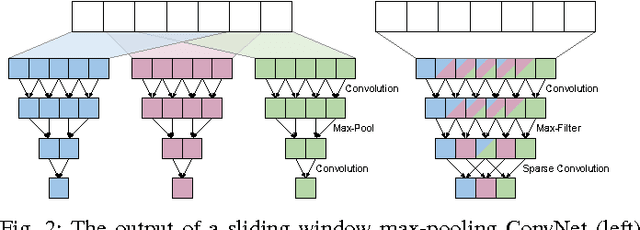
ZNNi - Maximizing the Inference Throughput of 3D Convolutional Networks on Multi-Core CPUs and GPUs
Jun 17, 2016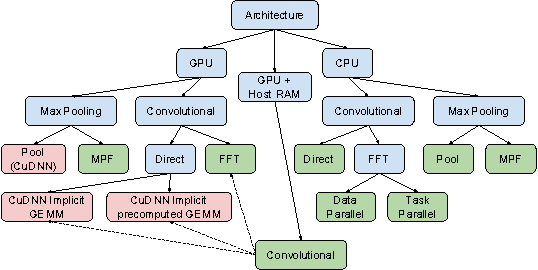
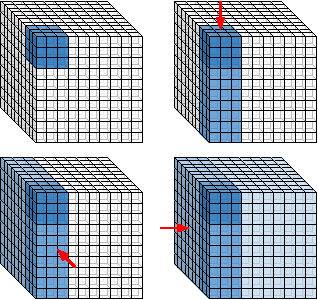
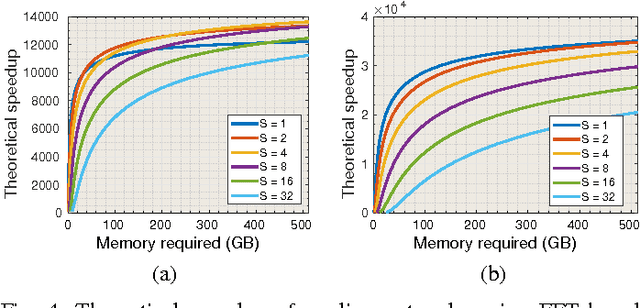
Sliding window convolutional networks (ConvNets) have become a popular approach to computer vision problems such as image segmentation, and object detection and localization. Here we consider the problem of inference, the application of a previously trained ConvNet, with emphasis on 3D images. Our goal is to maximize throughput, defined as average number of output voxels computed per unit time. Other things being equal, processing a larger image tends to increase throughput, because fractionally less computation is wasted on the borders of the image. It follows that an apparently slower algorithm may end up having higher throughput if it can process a larger image within the constraint of the available RAM. We introduce novel CPU and GPU primitives for convolutional and pooling layers, which are designed to minimize memory overhead. The primitives include convolution based on highly efficient pruned FFTs. Our theoretical analyses and empirical tests reveal a number of interesting findings. For some ConvNet architectures, cuDNN is outperformed by our FFT-based GPU primitives, and these in turn can be outperformed by our CPU primitives. The CPU manages to achieve higher throughput because of its fast access to more RAM. A novel primitive in which the GPU accesses host RAM can significantly increase GPU throughput. Finally, a CPU-GPU algorithm achieves the greatest throughput of all, 10x or more than other publicly available implementations of sliding window 3D ConvNets. All of our code has been made available as open source project.
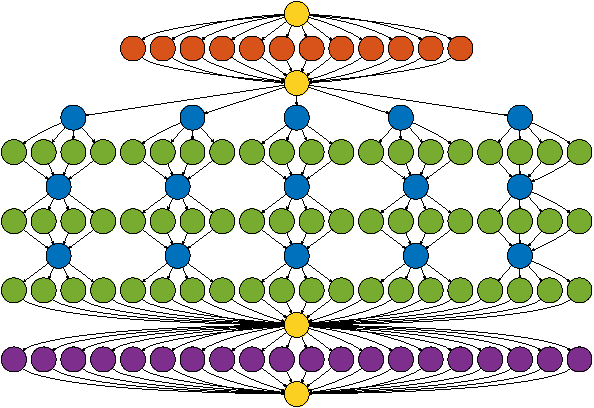
ZNN - A Fast and Scalable Algorithm for Training 3D Convolutional Networks on Multi-Core and Many-Core Shared Memory Machines
Oct 22, 2015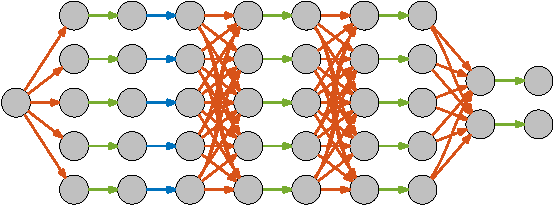
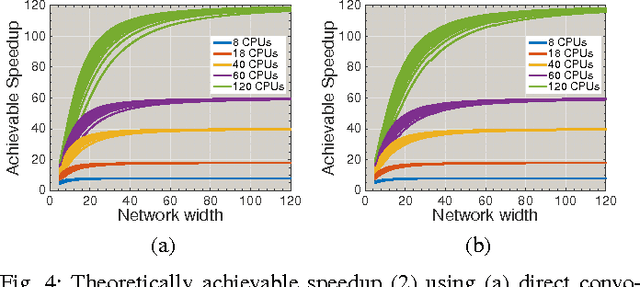
Convolutional networks (ConvNets) have become a popular approach to computer vision. It is important to accelerate ConvNet training, which is computationally costly. We propose a novel parallel algorithm based on decomposition into a set of tasks, most of which are convolutions or FFTs. Applying Brent's theorem to the task dependency graph implies that linear speedup with the number of processors is attainable within the PRAM model of parallel computation, for wide network architectures. To attain such performance on real shared-memory machines, our algorithm computes convolutions converging on the same node of the network with temporal locality to reduce cache misses, and sums the convergent convolution outputs via an almost wait-free concurrent method to reduce time spent in critical sections. We implement the algorithm with a publicly available software package called ZNN. Benchmarking with multi-core CPUs shows that ZNN can attain speedup roughly equal to the number of physical cores. We also show that ZNN can attain over 90x speedup on a many-core CPU (Xeon Phi Knights Corner). These speedups are achieved for network architectures with widths that are in common use. The task parallelism of the ZNN algorithm is suited to CPUs, while the SIMD parallelism of previous algorithms is compatible with GPUs. Through examples, we show that ZNN can be either faster or slower than certain GPU implementations depending on specifics of the network architecture, kernel sizes, and density and size of the output patch. ZNN may be less costly to develop and maintain, due to the relative ease of general-purpose CPU programming.