 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZNNi - Maximizing the Inference Throughput of 3D Convolutional Networks on Multi-Core CPUs and GPUs
Paper and Code
Jun 17, 2016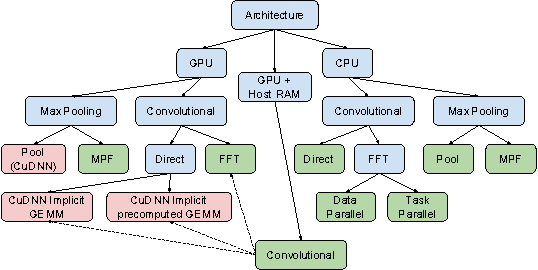
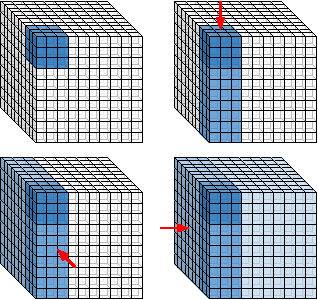
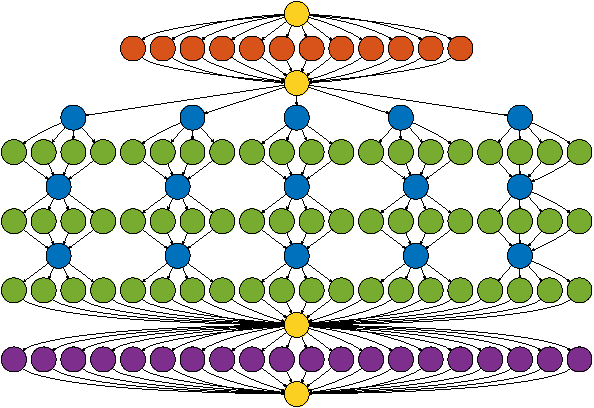
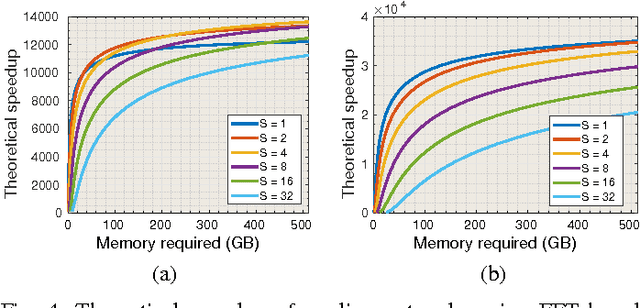
Sliding window convolutional networks (ConvNets) have become a popular approach to computer vision problems such as image segmentation, and object detection and localization. Here we consider the problem of inference, the application of a previously trained ConvNet, with emphasis on 3D images. Our goal is to maximize throughput, defined as average number of output voxels computed per unit time. Other things being equal, processing a larger image tends to increase throughput, because fractionally less computation is wasted on the borders of the image. It follows that an apparently slower algorithm may end up having higher throughput if it can process a larger image within the constraint of the available RAM. We introduce novel CPU and GPU primitives for convolutional and pooling layers, which are designed to minimize memory overhead. The primitives include convolution based on highly efficient pruned FFTs. Our theoretical analyses and empirical tests reveal a number of interesting findings. For some ConvNet architectures, cuDNN is outperformed by our FFT-based GPU primitives, and these in turn can be outperformed by our CPU primitives. The CPU manages to achieve higher throughput because of its fast access to more RAM. A novel primitive in which the GPU accesses host RAM can significantly increase GPU throughput. Finally, a CPU-GPU algorithm achieves the greatest throughput of all, 10x or more than other publicly available implementations of sliding window 3D ConvNets. All of our code has been made available as open source project.