 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLoopTune: Optimizing Tensor Computations with Reinforcement Learning
Sep 08, 2023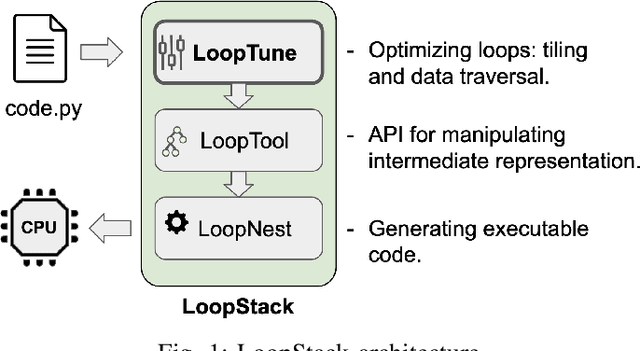
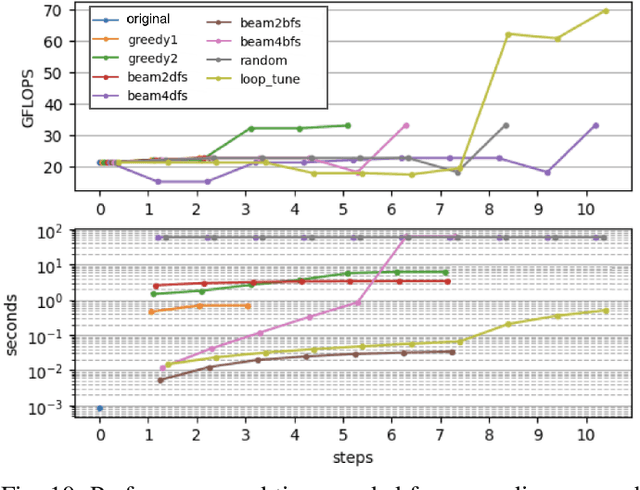
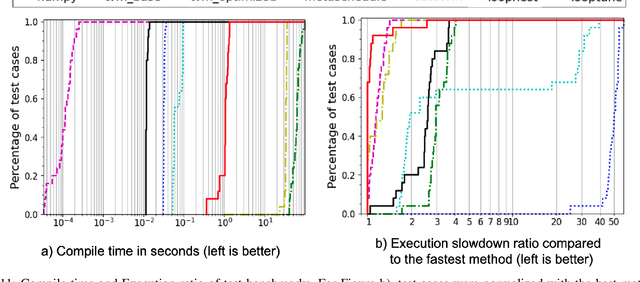
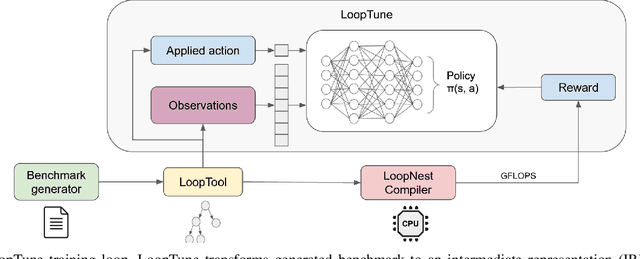
Advanced compiler technology is crucial for enabling machine learning applications to run on novel hardware, but traditional compilers fail to deliver performance, popular auto-tuners have long search times and expert-optimized libraries introduce unsustainable costs. To address this, we developed LoopTune, a deep reinforcement learning compiler that optimizes tensor computations in deep learning models for the CPU. LoopTune optimizes tensor traversal order while using the ultra-fast lightweight code generator LoopNest to perform hardware-specific optimizations. With a novel graph-based representation and action space, LoopTune speeds up LoopNest by 3.2x, generating an order of magnitude faster code than TVM, 2.8x faster than MetaSchedule, and 1.08x faster than AutoTVM, consistently performing at the level of the hand-tuned library Numpy. Moreover, LoopTune tunes code in order of seconds.
LoopStack: a Lightweight Tensor Algebra Compiler Stack
May 02, 2022

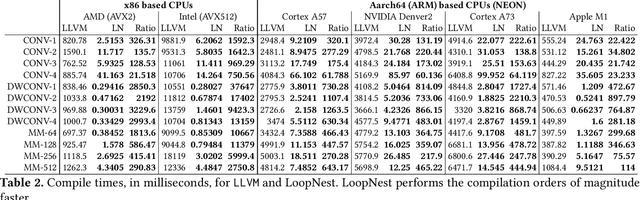
We present LoopStack, a domain specific compiler stack for tensor operations, composed of a frontend, LoopTool, and an efficient optimizing code generator, LoopNest. This stack enables us to compile entire neural networks and generate code targeting the AVX2, AVX512, NEON, and NEONfp16 instruction sets while incorporating optimizations often missing from other machine learning compiler backends. We evaluate our stack on a collection of full neural networks and commonly used network blocks as well as individual operators, and show that LoopStack generates machine code that matches and frequently exceeds the performance of in state-of-the-art machine learning frameworks in both cases. We also show that for a large collection of schedules LoopNest's compilation is orders of magnitude faster than LLVM, while resulting in equal or improved run time performance. Additionally, LoopStack has a very small memory footprint - a binary size of 245KB, and under 30K lines of effective code makes it ideal for use on mobile and embedded devices.
Large-scale image segmentation based on distributed clustering algorithms
Jun 21, 2021
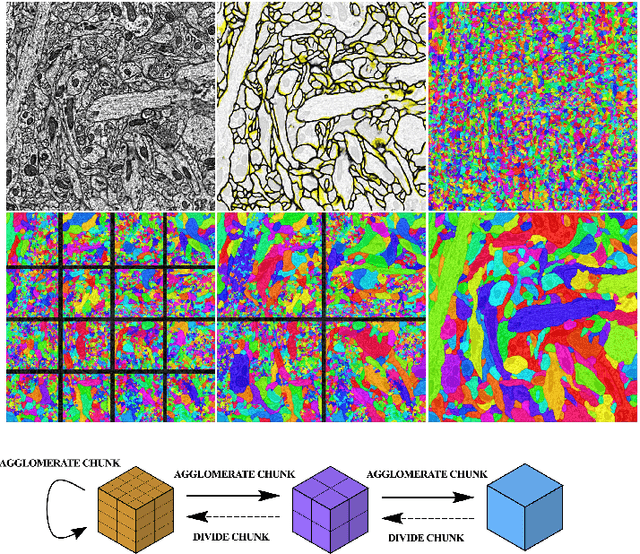
Many approaches to 3D image segmentation are based on hierarchical clustering of supervoxels into image regions. Here we describe a distributed algorithm capable of handling a tremendous number of supervoxels. The algorithm works recursively, the regions are divided into chunks that are processed independently in parallel by multiple workers. At each round of the recursive procedure, the chunk size in all dimensions are doubled until a single chunk encompasses the entire image. The final result is provably independent of the chunking scheme, and the same as if the entire image were processed without division into chunks. This is nontrivial because a pair of adjacent regions is scored by some statistical property (e.g. mean or median) of the affinities at the interface, and the interface may extend over arbitrarily many chunks. The trick is to delay merge decisions for regions that touch chunk boundaries, and only complete them in a later round after the regions are fully contained within a chunk. We demonstrate the algorithm by clustering an affinity graph with over 1.5 trillion edges between 135 billion supervoxels derived from a 3D electron microscopic brain image.
L3 Fusion: Fast Transformed Convolutions on CPUs
Dec 04, 2019
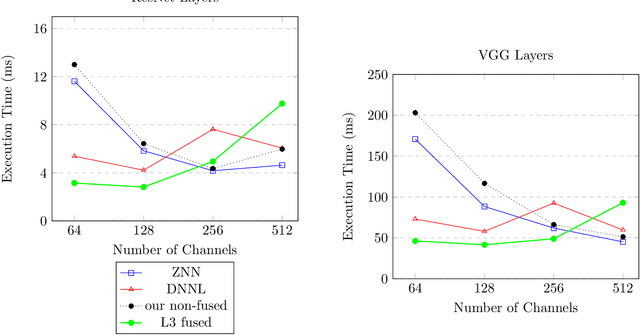
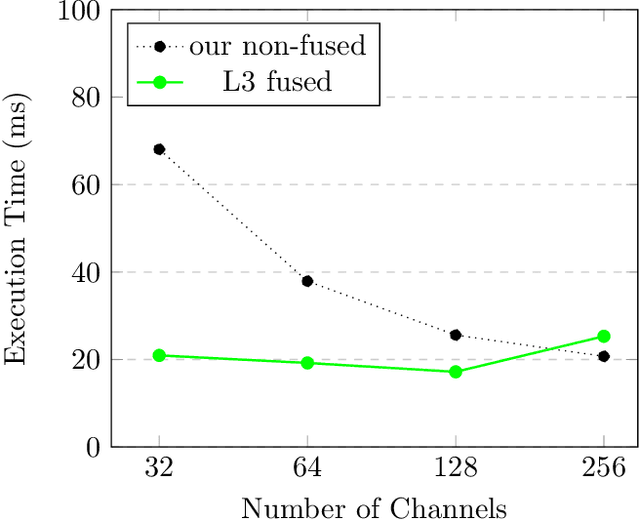
Fast convolutions via transforms, either Winograd or FFT, had emerged as a preferred way of performing the computation of convolutional layers, as it greatly reduces the number of required operations. Recent work shows that, for many layer structures, a well--designed implementation of fast convolutions can greatly utilize modern CPUs, significantly reducing the compute time. However, the generous amount of shared L3 cache present on modern CPUs is often neglected, and the algorithms are optimized solely for the private L2 cache. In this paper we propose an efficient `L3 Fusion` algorithm that is specifically designed for CPUs with significant amount of shared L3 cache. Using the hierarchical roofline model, we show that in many cases, especially for layers with fewer channels, the `L3 fused` approach can greatly outperform standard 3 stage one provided by big vendors such as Intel. We validate our theoretical findings, by benchmarking our `L3 fused` implementation against publicly available state of the art.
PZnet: Efficient 3D ConvNet Inference on Manycore CPUs
Mar 18, 2019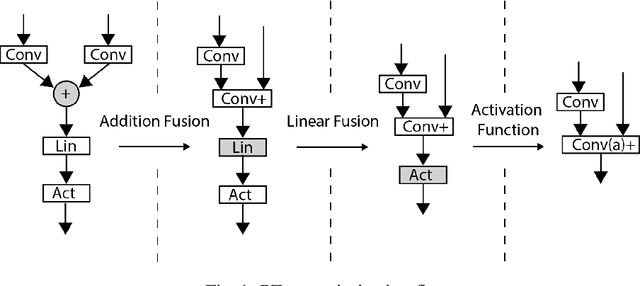
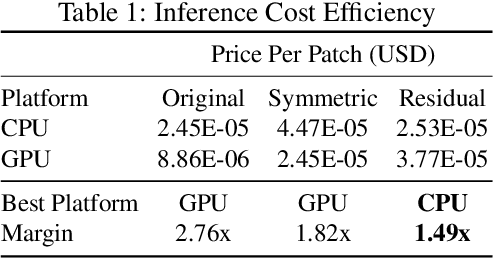

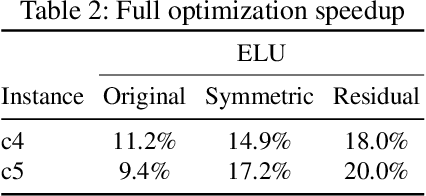
Convolutional nets have been shown to achieve state-of-the-art accuracy in many biomedical image analysis tasks. Many tasks within biomedical analysis domain involve analyzing volumetric (3D) data acquired by CT, MRI and Microscopy acquisition methods. To deploy convolutional nets in practical working systems, it is important to solve the efficient inference problem. Namely, one should be able to apply an already-trained convolutional network to many large images using limited computational resources. In this paper we present PZnet, a CPU-only engine that can be used to perform inference for a variety of 3D convolutional net architectures. PZNet outperforms MKL-based CPU implementations of PyTorch and Tensorflow by more than 3.5x for the popular U-net architecture. Moreover, for 3D convolutions with low featuremap numbers, cloud CPU inference with PZnet outperfroms cloud GPU inference in terms of cost efficiency.
ZNNi - Maximizing the Inference Throughput of 3D Convolutional Networks on Multi-Core CPUs and GPUs
Jun 17, 2016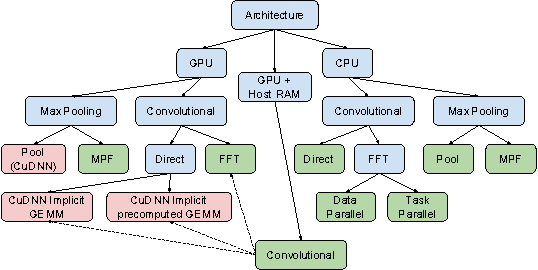
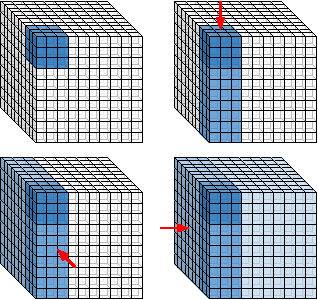
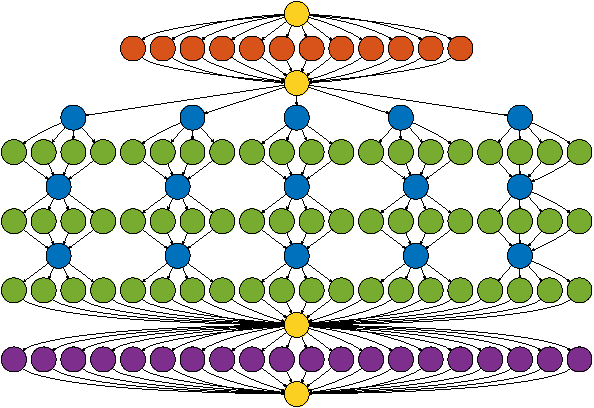
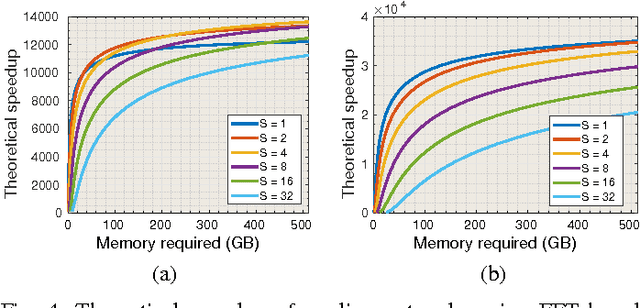
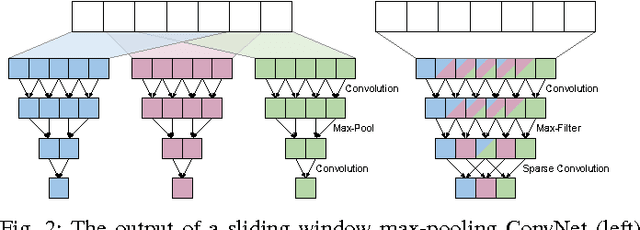
Sliding window convolutional networks (ConvNets) have become a popular approach to computer vision problems such as image segmentation, and object detection and localization. Here we consider the problem of inference, the application of a previously trained ConvNet, with emphasis on 3D images. Our goal is to maximize throughput, defined as average number of output voxels computed per unit time. Other things being equal, processing a larger image tends to increase throughput, because fractionally less computation is wasted on the borders of the image. It follows that an apparently slower algorithm may end up having higher throughput if it can process a larger image within the constraint of the available RAM. We introduce novel CPU and GPU primitives for convolutional and pooling layers, which are designed to minimize memory overhead. The primitives include convolution based on highly efficient pruned FFTs. Our theoretical analyses and empirical tests reveal a number of interesting findings. For some ConvNet architectures, cuDNN is outperformed by our FFT-based GPU primitives, and these in turn can be outperformed by our CPU primitives. The CPU manages to achieve higher throughput because of its fast access to more RAM. A novel primitive in which the GPU accesses host RAM can significantly increase GPU throughput. Finally, a CPU-GPU algorithm achieves the greatest throughput of all, 10x or more than other publicly available implementations of sliding window 3D ConvNets. All of our code has been made available as open source project.
ZNN - A Fast and Scalable Algorithm for Training 3D Convolutional Networks on Multi-Core and Many-Core Shared Memory Machines
Oct 22, 2015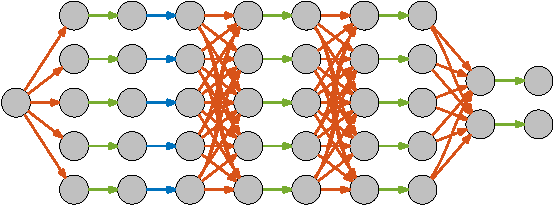
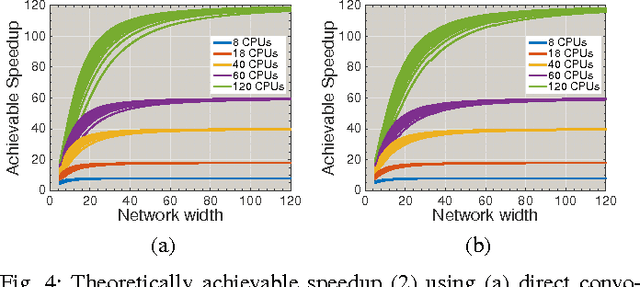
Convolutional networks (ConvNets) have become a popular approach to computer vision. It is important to accelerate ConvNet training, which is computationally costly. We propose a novel parallel algorithm based on decomposition into a set of tasks, most of which are convolutions or FFTs. Applying Brent's theorem to the task dependency graph implies that linear speedup with the number of processors is attainable within the PRAM model of parallel computation, for wide network architectures. To attain such performance on real shared-memory machines, our algorithm computes convolutions converging on the same node of the network with temporal locality to reduce cache misses, and sums the convergent convolution outputs via an almost wait-free concurrent method to reduce time spent in critical sections. We implement the algorithm with a publicly available software package called ZNN. Benchmarking with multi-core CPUs shows that ZNN can attain speedup roughly equal to the number of physical cores. We also show that ZNN can attain over 90x speedup on a many-core CPU (Xeon Phi Knights Corner). These speedups are achieved for network architectures with widths that are in common use. The task parallelism of the ZNN algorithm is suited to CPUs, while the SIMD parallelism of previous algorithms is compatible with GPUs. Through examples, we show that ZNN can be either faster or slower than certain GPU implementations depending on specifics of the network architecture, kernel sizes, and density and size of the output patch. ZNN may be less costly to develop and maintain, due to the relative ease of general-purpose CPU programming.
Recursive Training of 2D-3D Convolutional Networks for Neuronal Boundary Detection
Aug 20, 2015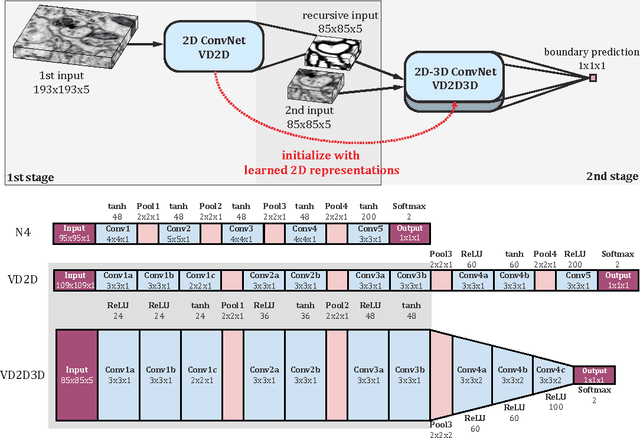

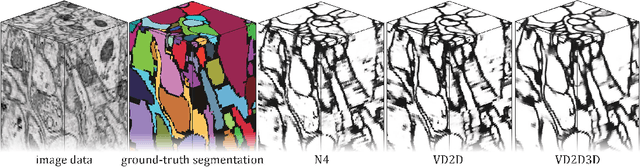
Efforts to automate the reconstruction of neural circuits from 3D electron microscopic (EM) brain images are critical for the field of connectomics. An important computation for reconstruction is the detection of neuronal boundaries. Images acquired by serial section EM, a leading 3D EM technique, are highly anisotropic, with inferior quality along the third dimension. For such images, the 2D max-pooling convolutional network has set the standard for performance at boundary detection. Here we achieve a substantial gain in accuracy through three innovations. Following the trend towards deeper networks for object recognition, we use a much deeper network than previously employed for boundary detection. Second, we incorporate 3D as well as 2D filters, to enable computations that use 3D context. Finally, we adopt a recursively trained architecture in which a first network generates a preliminary boundary map that is provided as input along with the original image to a second network that generates a final boundary map. Backpropagation training is accelerated by ZNN, a new implementation of 3D convolutional networks that uses multicore CPU parallelism for speed. Our hybrid 2D-3D architecture could be more generally applicable to other types of anisotropic 3D images, including video, and our recursive framework for any image labeling problem.
Image Segmentation by Size-Dependent Single Linkage Clustering of a Watershed Basin Graph
May 01, 2015

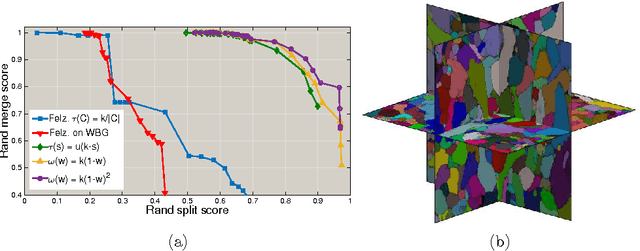
We present a method for hierarchical image segmentation that defines a disaffinity graph on the image, over-segments it into watershed basins, defines a new graph on the basins, and then merges basins with a modified, size-dependent version of single linkage clustering. The quasilinear runtime of the method makes it suitable for segmenting large images. We illustrate the method on the challenging problem of segmenting 3D electron microscopic brain images.