 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStudying Large Language Model Generalization with Influence Functions
Aug 07, 2023



When trying to gain better visibility into a machine learning model in order to understand and mitigate the associated risks, a potentially valuable source of evidence is: which training examples most contribute to a given behavior? Influence functions aim to answer a counterfactual: how would the model's parameters (and hence its outputs) change if a given sequence were added to the training set? While influence functions have produced insights for small models, they are difficult to scale to large language models (LLMs) due to the difficulty of computing an inverse-Hessian-vector product (IHVP). We use the Eigenvalue-corrected Kronecker-Factored Approximate Curvature (EK-FAC) approximation to scale influence functions up to LLMs with up to 52 billion parameters. In our experiments, EK-FAC achieves similar accuracy to traditional influence function estimators despite the IHVP computation being orders of magnitude faster. We investigate two algorithmic techniques to reduce the cost of computing gradients of candidate training sequences: TF-IDF filtering and query batching. We use influence functions to investigate the generalization patterns of LLMs, including the sparsity of the influence patterns, increasing abstraction with scale, math and programming abilities, cross-lingual generalization, and role-playing behavior. Despite many apparently sophisticated forms of generalization, we identify a surprising limitation: influences decay to near-zero when the order of key phrases is flipped. Overall, influence functions give us a powerful new tool for studying the generalization properties of LLMs.
Measuring Faithfulness in Chain-of-Thought Reasoning
Jul 17, 2023

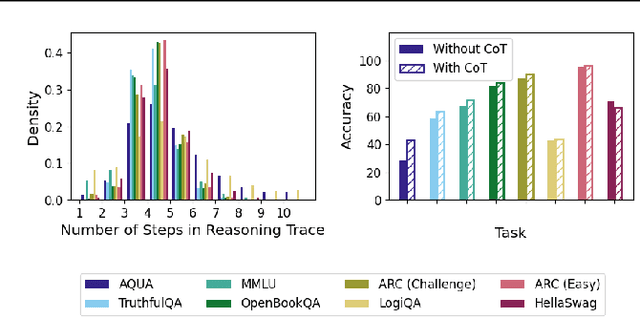
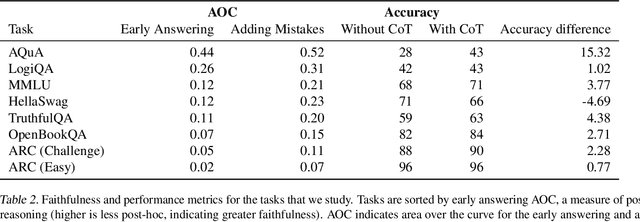
Large language models (LLMs) perform better when they produce step-by-step, "Chain-of-Thought" (CoT) reasoning before answering a question, but it is unclear if the stated reasoning is a faithful explanation of the model's actual reasoning (i.e., its process for answering the question). We investigate hypotheses for how CoT reasoning may be unfaithful, by examining how the model predictions change when we intervene on the CoT (e.g., by adding mistakes or paraphrasing it). Models show large variation across tasks in how strongly they condition on the CoT when predicting their answer, sometimes relying heavily on the CoT and other times primarily ignoring it. CoT's performance boost does not seem to come from CoT's added test-time compute alone or from information encoded via the particular phrasing of the CoT. As models become larger and more capable, they produce less faithful reasoning on most tasks we study. Overall, our results suggest that CoT can be faithful if the circumstances such as the model size and task are carefully chosen.
Searching Large Neighborhoods for Integer Linear Programs with Contrastive Learning
Feb 03, 2023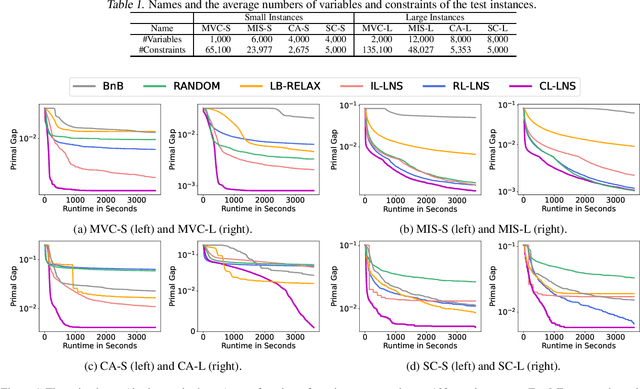
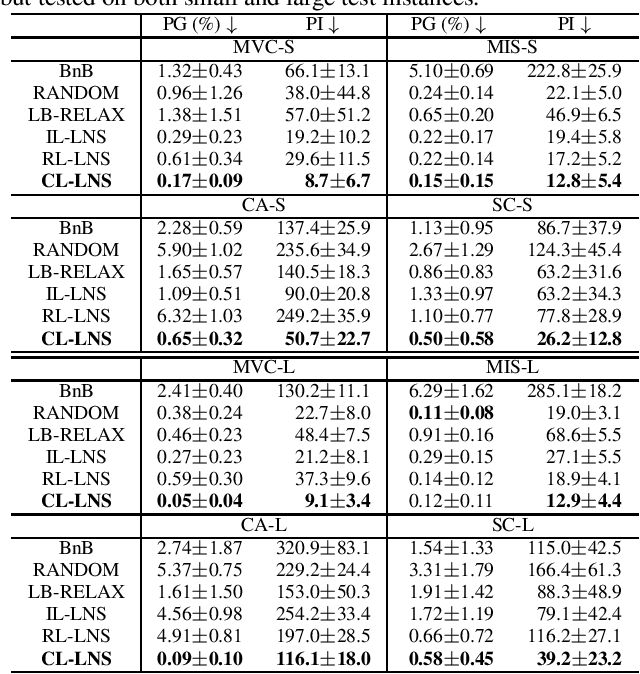
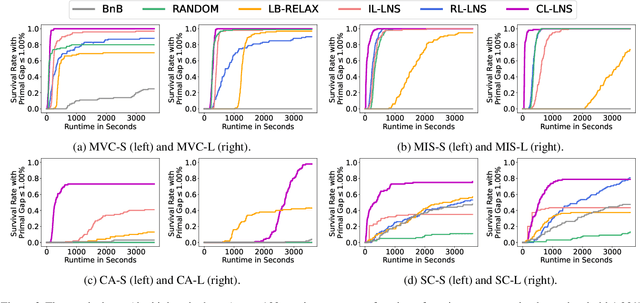
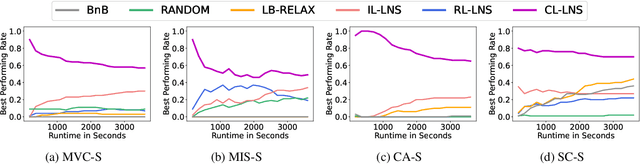
Integer Linear Programs (ILPs) are powerful tools for modeling and solving a large number of combinatorial optimization problems. Recently, it has been shown that Large Neighborhood Search (LNS), as a heuristic algorithm, can find high quality solutions to ILPs faster than Branch and Bound. However, how to find the right heuristics to maximize the performance of LNS remains an open problem. In this paper, we propose a novel approach, CL-LNS, that delivers state-of-the-art anytime performance on several ILP benchmarks measured by metrics including the primal gap, the primal integral, survival rates and the best performing rate. Specifically, CL-LNS collects positive and negative solution samples from an expert heuristic that is slow to compute and learns a new one with a contrastive loss. We use graph attention networks and a richer set of features to further improve its performance.
Learning to compile smartly for program size reduction
Jan 09, 2023Compiler optimization passes are an important tool for improving program efficiency and reducing program size, but manually selecting optimization passes can be time-consuming and error-prone. While human experts have identified a few fixed sequences of optimization passes (e.g., the Clang -Oz passes) that perform well for a wide variety of programs, these sequences are not conditioned on specific programs. In this paper, we propose a novel approach that learns a policy to select passes for program size reduction, allowing for customization and adaptation to specific programs. Our approach uses a search mechanism that helps identify useful pass sequences and a GNN with customized attention that selects the optimal sequence to use. Crucially it is able to generalize to new, unseen programs, making it more flexible and general than previous approaches. We evaluate our approach on a range of programs and show that it leads to size reduction compared to traditional optimization techniques. Our results demonstrate the potential of a single policy that is able to optimize many programs.
Local Branching Relaxation Heuristics for Integer Linear Programs
Dec 15, 2022Large Neighborhood Search (LNS) is a popular heuristic algorithm for solving combinatorial optimization problems (COP). It starts with an initial solution to the problem and iteratively improves it by searching a large neighborhood around the current best solution. LNS relies on heuristics to select neighborhoods to search in. In this paper, we focus on designing effective and efficient heuristics in LNS for integer linear programs (ILP) since a wide range of COPs can be represented as ILPs. Local Branching (LB) is a heuristic that selects the neighborhood that leads to the largest improvement over the current solution in each iteration of LNS. LB is often slow since it needs to solve an ILP of the same size as input. Our proposed heuristics, LB-RELAX and its variants, use the linear programming relaxation of LB to select neighborhoods. Empirically, LB-RELAX and its variants compute as effective neighborhoods as LB but run faster. They achieve state-of-the-art anytime performance on several ILP benchmarks.
OLLA: Optimizing the Lifetime and Location of Arrays to Reduce the Memory Usage of Neural Networks
Nov 02, 2022The size of deep neural networks has grown exponentially in recent years. Unfortunately, hardware devices have not kept pace with the rapidly increasing memory requirements. To cope with this, researchers have turned to techniques such as spilling and recomputation, which increase training time, or reduced precision and model pruning, which can affect model accuracy. We present OLLA, an algorithm that optimizes the lifetime and memory location of the tensors used to train neural networks. Our method reduces the memory usage of existing neural networks, without needing any modification to the models or their training procedures. We formulate the problem as a joint integer linear program (ILP). We present several techniques to simplify the encoding of the problem, and enable our approach to scale to the size of state-of-the-art neural networks using an off-the-shelf ILP solver. We experimentally demonstrate that OLLA only takes minutes if not seconds to allow the training of neural networks using one-third less memory on average.
SurCo: Learning Linear Surrogates For Combinatorial Nonlinear Optimization Problems
Oct 22, 2022



Optimization problems with expensive nonlinear cost functions and combinatorial constraints appear in many real-world applications, but remain challenging to solve efficiently. Existing combinatorial solvers like Mixed Integer Linear Programming can be fast in practice but cannot readily optimize nonlinear cost functions, while general nonlinear optimizers like gradient descent often do not handle complex combinatorial structures, may require many queries of the cost function, and are prone to local optima. To bridge this gap, we propose SurCo that learns linear Surrogate costs which can be used by existing Combinatorial solvers to output good solutions to the original nonlinear combinatorial optimization problem, combining the flexibility of gradient-based methods with the structure of linear combinatorial optimization. We learn these linear surrogates end-to-end with the nonlinear loss by differentiating through the linear surrogate solver. Three variants of SurCo are proposed: SurCo-zero operates on individual nonlinear problems, SurCo-prior trains a linear surrogate predictor on distributions of problems, and SurCo-hybrid uses a model trained offline to warm start online solving for SurCo-zero. We analyze our method theoretically and empirically, showing smooth convergence and improved performance. Experiments show that compared to state-of-the-art approaches and expert-designed heuristics, SurCo obtains lower cost solutions with comparable or faster solve time for two realworld industry-level applications: embedding table sharding and inverse photonic design.
LoopStack: a Lightweight Tensor Algebra Compiler Stack
May 02, 2022

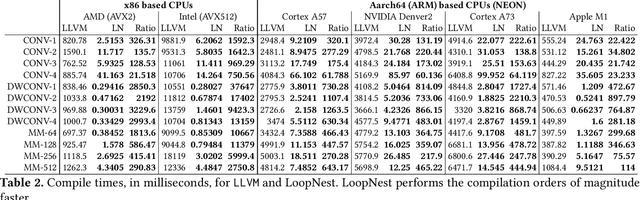
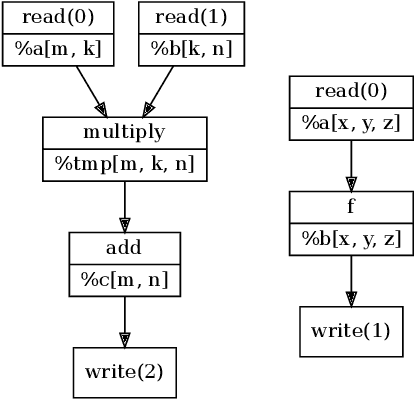
We present LoopStack, a domain specific compiler stack for tensor operations, composed of a frontend, LoopTool, and an efficient optimizing code generator, LoopNest. This stack enables us to compile entire neural networks and generate code targeting the AVX2, AVX512, NEON, and NEONfp16 instruction sets while incorporating optimizations often missing from other machine learning compiler backends. We evaluate our stack on a collection of full neural networks and commonly used network blocks as well as individual operators, and show that LoopStack generates machine code that matches and frequently exceeds the performance of in state-of-the-art machine learning frameworks in both cases. We also show that for a large collection of schedules LoopNest's compilation is orders of magnitude faster than LLVM, while resulting in equal or improved run time performance. Additionally, LoopStack has a very small memory footprint - a binary size of 245KB, and under 30K lines of effective code makes it ideal for use on mobile and embedded devices.
Flashlight: Enabling Innovation in Tools for Machine Learning
Jan 29, 2022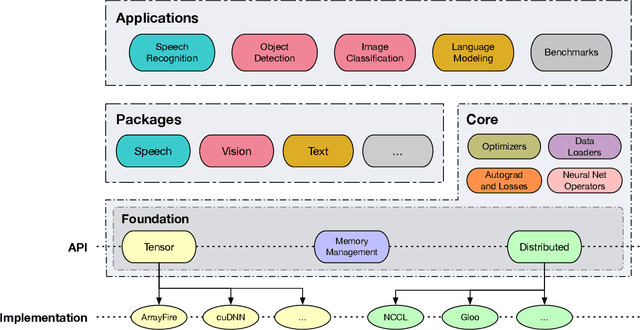
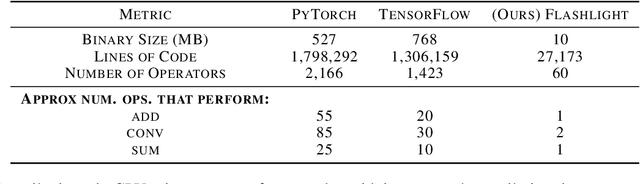
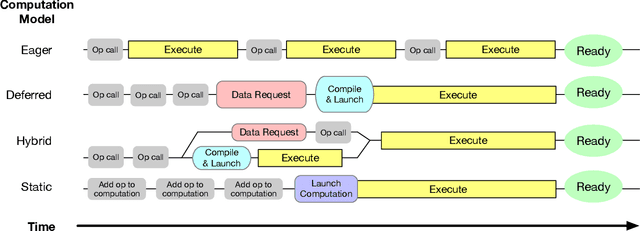
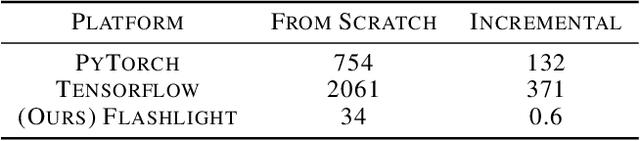
As the computational requirements for machine learning systems and the size and complexity of machine learning frameworks increases, essential framework innovation has become challenging. While computational needs have driven recent compiler, networking, and hardware advancements, utilization of those advancements by machine learning tools is occurring at a slower pace. This is in part due to the difficulties involved in prototyping new computational paradigms with existing frameworks. Large frameworks prioritize machine learning researchers and practitioners as end users and pay comparatively little attention to systems researchers who can push frameworks forward -- we argue that both are equally important stakeholders. We introduce Flashlight, an open-source library built to spur innovation in machine learning tools and systems by prioritizing open, modular, customizable internals and state-of-the-art, research-ready models and training setups across a variety of domains. Flashlight allows systems researchers to rapidly prototype and experiment with novel ideas in machine learning computation and has low overhead, competing with and often outperforming other popular machine learning frameworks. We see Flashlight as a tool enabling research that can benefit widely used libraries downstream and bring machine learning and systems researchers closer together.
CompilerGym: Robust, Performant Compiler Optimization Environments for AI Research
Sep 17, 2021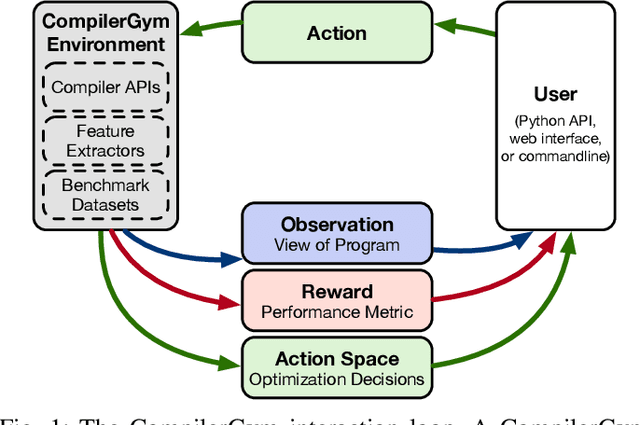
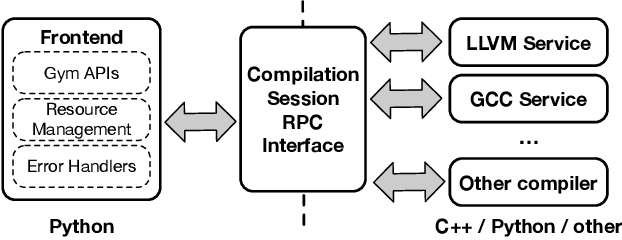
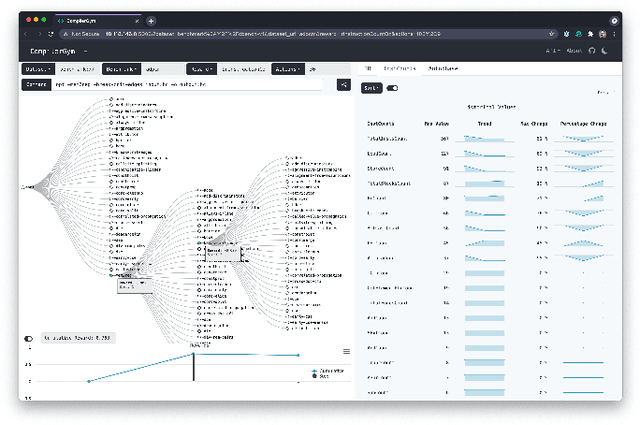
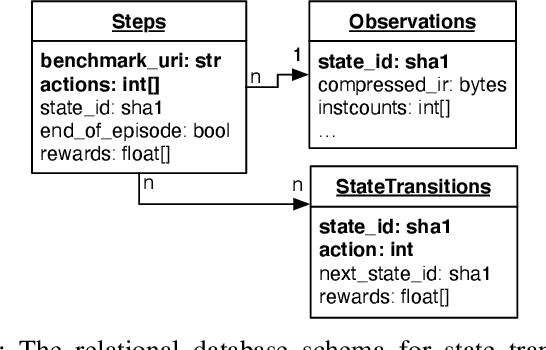
Interest in applying Artificial Intelligence (AI) techniques to compiler optimizations is increasing rapidly, but compiler research has a high entry barrier. Unlike in other domains, compiler and AI researchers do not have access to the datasets and frameworks that enable fast iteration and development of ideas, and getting started requires a significant engineering investment. What is needed is an easy, reusable experimental infrastructure for real world compiler optimization tasks that can serve as a common benchmark for comparing techniques, and as a platform to accelerate progress in the field. We introduce CompilerGym, a set of environments for real world compiler optimization tasks, and a toolkit for exposing new optimization tasks to compiler researchers. CompilerGym enables anyone to experiment on production compiler optimization problems through an easy-to-use package, regardless of their experience with compilers. We build upon the popular OpenAI Gym interface enabling researchers to interact with compilers using Python and a familiar API. We describe the CompilerGym architecture and implementation, characterize the optimization spaces and computational efficiencies of three included compiler environments, and provide extensive empirical evaluations. Compared to prior works, CompilerGym offers larger datasets and optimization spaces, is 27x more computationally efficient, is fault-tolerant, and capable of detecting reproducibility bugs in the underlying compilers. In making it easy for anyone to experiment with compilers - irrespective of their background - we aim to accelerate progress in the AI and compiler research domains.