 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edgetorch.fx: Practical Program Capture and Transformation for Deep Learning in Python
Dec 15, 2021



Modern deep learning frameworks provide imperative, eager execution programming interfaces embedded in Python to provide a productive development experience. However, deep learning practitioners sometimes need to capture and transform program structure for performance optimization, visualization, analysis, and hardware integration. We study the different designs for program capture and transformation used in deep learning. By designing for typical deep learning use cases rather than long tail ones, it is possible to create a simpler framework for program capture and transformation. We apply this principle in torch.fx, a program capture and transformation library for PyTorch written entirely in Python and optimized for high developer productivity by ML practitioners. We present case studies showing how torch.fx enables workflows previously inaccessible in the PyTorch ecosystem.
CompilerGym: Robust, Performant Compiler Optimization Environments for AI Research
Sep 17, 2021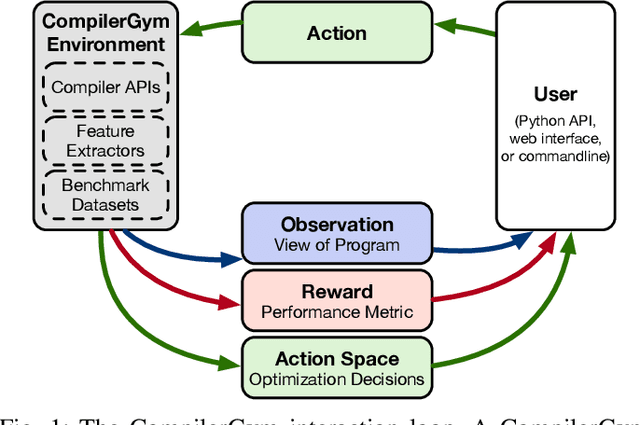
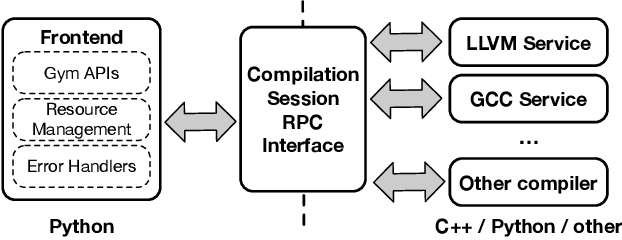
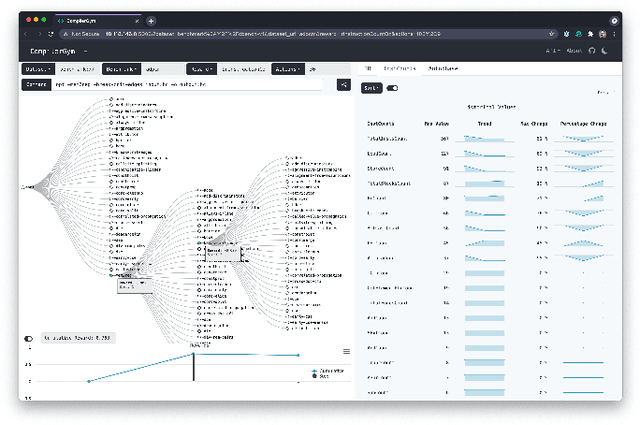
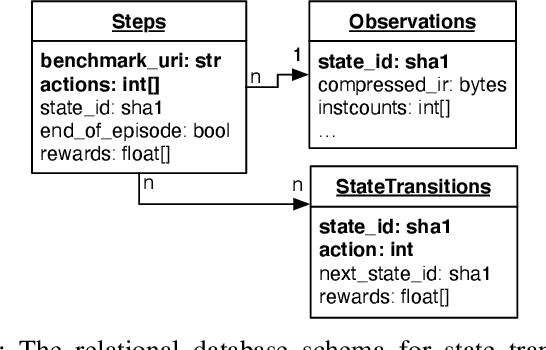
Interest in applying Artificial Intelligence (AI) techniques to compiler optimizations is increasing rapidly, but compiler research has a high entry barrier. Unlike in other domains, compiler and AI researchers do not have access to the datasets and frameworks that enable fast iteration and development of ideas, and getting started requires a significant engineering investment. What is needed is an easy, reusable experimental infrastructure for real world compiler optimization tasks that can serve as a common benchmark for comparing techniques, and as a platform to accelerate progress in the field. We introduce CompilerGym, a set of environments for real world compiler optimization tasks, and a toolkit for exposing new optimization tasks to compiler researchers. CompilerGym enables anyone to experiment on production compiler optimization problems through an easy-to-use package, regardless of their experience with compilers. We build upon the popular OpenAI Gym interface enabling researchers to interact with compilers using Python and a familiar API. We describe the CompilerGym architecture and implementation, characterize the optimization spaces and computational efficiencies of three included compiler environments, and provide extensive empirical evaluations. Compared to prior works, CompilerGym offers larger datasets and optimization spaces, is 27x more computationally efficient, is fault-tolerant, and capable of detecting reproducibility bugs in the underlying compilers. In making it easy for anyone to experiment with compilers - irrespective of their background - we aim to accelerate progress in the AI and compiler research domains.
Using Python for Model Inference in Deep Learning
Apr 01, 2021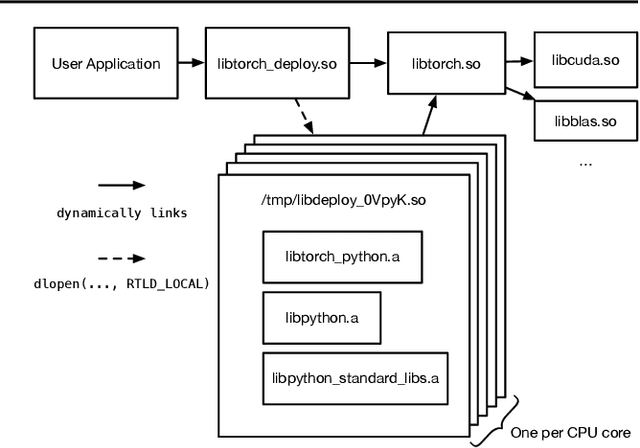


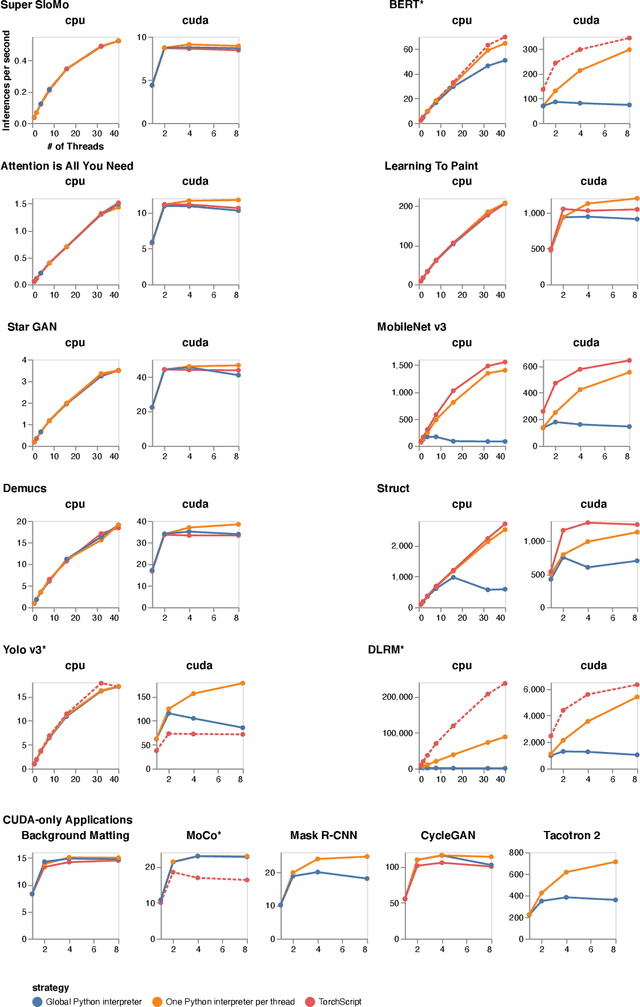
Python has become the de-facto language for training deep neural networks, coupling a large suite of scientific computing libraries with efficient libraries for tensor computation such as PyTorch or TensorFlow. However, when models are used for inference they are typically extracted from Python as TensorFlow graphs or TorchScript programs in order to meet performance and packaging constraints. The extraction process can be time consuming, impeding fast prototyping. We show how it is possible to meet these performance and packaging constraints while performing inference in Python. In particular, we present a way of using multiple Python interpreters within a single process to achieve scalable inference and describe a new container format for models that contains both native Python code and data. This approach simplifies the model deployment story by eliminating the model extraction step, and makes it easier to integrate existing performance-enhancing Python libraries. We evaluate our design on a suite of popular PyTorch models on Github, showing how they can be packaged in our inference format, and comparing their performance to TorchScript. For larger models, our packaged Python models perform the same as TorchScript, and for smaller models where there is some Python overhead, our multi-interpreter approach ensures inference is still scalable.
Tight Prediction Intervals Using Expanded Interval Minimization
Jun 28, 2018


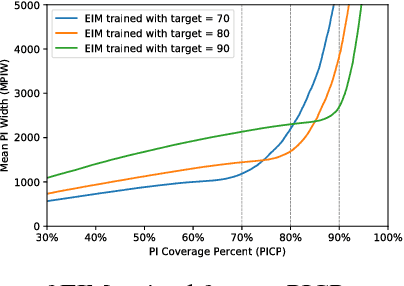
Prediction intervals are a valuable way of quantifying uncertainty in regression problems. Good prediction intervals should be both correct, containing the actual value between the lower and upper bound at least a target percentage of the time; and tight, having a small mean width of the bounds. Many prior techniques for generating prediction intervals make assumptions on the distribution of error, which causes them to work poorly for problems with asymmetric distributions. This paper presents Expanded Interval Minimization (EIM), a novel loss function for generating prediction intervals using neural networks. This loss function uses minibatch statistics to estimate the coverage and optimize the width of the prediction intervals. It does not make the same assumptions on the distributions of data and error as prior work. We compare to three published techniques and show EIM produces on average 1.37x tighter prediction intervals and in the worst case 1.06x tighter intervals across two large real-world datasets and varying coverage levels.