 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Llama 4 Herd: Architecture, Training, Evaluation, and Deployment Notes
Jan 15, 2026This document consolidates publicly reported technical details about Metas Llama 4 model family. It summarizes (i) released variants (Scout and Maverick) and the broader herd context including the previewed Behemoth teacher model, (ii) architectural characteristics beyond a high-level MoE description covering routed/shared-expert structure, early-fusion multimodality, and long-context design elements reported for Scout (iRoPE and length generalization strategies), (iii) training disclosures spanning pre-training, mid-training for long-context extension, and post-training methodology (lightweight SFT, online RL, and lightweight DPO) as described in release materials, (iv) developer-reported benchmark results for both base and instruction-tuned checkpoints, and (v) practical deployment constraints observed across major serving environments, including provider-specific context limits and quantization packaging. The manuscript also summarizes licensing obligations relevant to redistribution and derivative naming, and reviews publicly described safeguards and evaluation practices. The goal is to provide a compact technical reference for researchers and practitioners who need precise, source-backed facts about Llama 4.
TorchTitan: One-stop PyTorch native solution for production ready LLM pre-training
Oct 09, 2024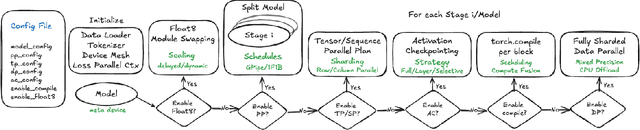



The development of large language models (LLMs) has been instrumental in advancing state-of-the-art natural language processing applications. Training LLMs with billions of parameters and trillions of tokens require sophisticated distributed systems that enable composing and comparing several state-of-the-art techniques in order to efficiently scale across thousands of accelerators. However, existing solutions are complex, scattered across multiple libraries/repositories, lack interoperability, and are cumbersome to maintain. Thus, curating and empirically comparing training recipes require non-trivial engineering effort. This paper introduces TorchTitan, an open-source, PyTorch-native distributed training system that unifies state-of-the-art techniques, streamlining integration and reducing overhead. TorchTitan enables 3D parallelism in a modular manner with elastic scaling, providing comprehensive logging, checkpointing, and debugging tools for production-ready training. It also incorporates hardware-software co-designed solutions, leveraging features like Float8 training and SymmetricMemory. As a flexible test bed, TorchTitan facilitates custom recipe curation and comparison, allowing us to develop optimized training recipes for Llama 3.1 and provide guidance on selecting techniques for maximum efficiency based on our experiences. We thoroughly assess TorchTitan on the Llama 3.1 family of LLMs, spanning 8 billion to 405 billion parameters, and showcase its exceptional performance, modular composability, and elastic scalability. By stacking training optimizations, we demonstrate accelerations of 65.08% with 1D parallelism at the 128-GPU scale (Llama 3.1 8B), an additional 12.59% with 2D parallelism at the 256-GPU scale (Llama 3.1 70B), and an additional 30% with 3D parallelism at the 512-GPU scale (Llama 3.1 405B) on NVIDIA H100 GPUs over optimized baselines.
The Llama 3 Herd of Models
Jul 31, 2024Modern artificial intelligence (AI) systems are powered by foundation models. This paper presents a new set of foundation models, called Llama 3. It is a herd of language models that natively support multilinguality, coding, reasoning, and tool usage. Our largest model is a dense Transformer with 405B parameters and a context window of up to 128K tokens. This paper presents an extensive empirical evaluation of Llama 3. We find that Llama 3 delivers comparable quality to leading language models such as GPT-4 on a plethora of tasks. We publicly release Llama 3, including pre-trained and post-trained versions of the 405B parameter language model and our Llama Guard 3 model for input and output safety. The paper also presents the results of experiments in which we integrate image, video, and speech capabilities into Llama 3 via a compositional approach. We observe this approach performs competitively with the state-of-the-art on image, video, and speech recognition tasks. The resulting models are not yet being broadly released as they are still under development.
TorchBench: Benchmarking PyTorch with High API Surface Coverage
Apr 28, 2023Deep learning (DL) has been a revolutionary technique in various domains. To facilitate the model development and deployment, many deep learning frameworks are proposed, among which PyTorch is one of the most popular solutions. The performance of ecosystem around PyTorch is critically important, which saves the costs of training models and reduces the response time of model inferences. In this paper, we propose TorchBench, a novel benchmark suite to study the performance of PyTorch software stack. Unlike existing benchmark suites, TorchBench encloses many representative models, covering a large PyTorch API surface. TorchBench is able to comprehensively characterize the performance of the PyTorch software stack, guiding the performance optimization across models, PyTorch framework, and GPU libraries. We show two practical use cases of TorchBench. (1) We profile TorchBench to identify GPU performance inefficiencies in PyTorch. We are able to optimize many performance bugs and upstream patches to the official PyTorch repository. (2) We integrate TorchBench into PyTorch continuous integration system. We are able to identify performance regression in multiple daily code checkins to prevent PyTorch repository from introducing performance bugs. TorchBench is open source and keeps evolving.
Using Python for Model Inference in Deep Learning
Apr 01, 2021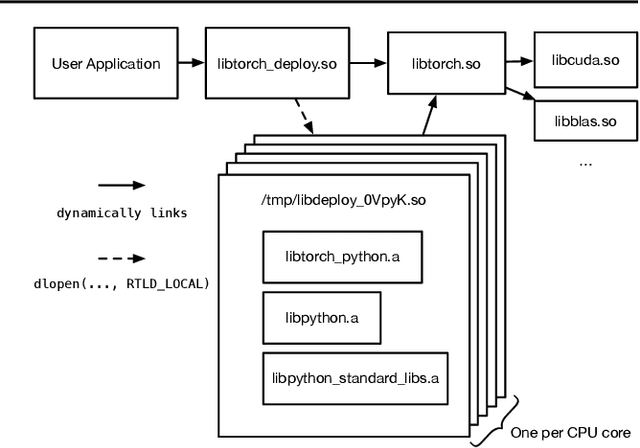


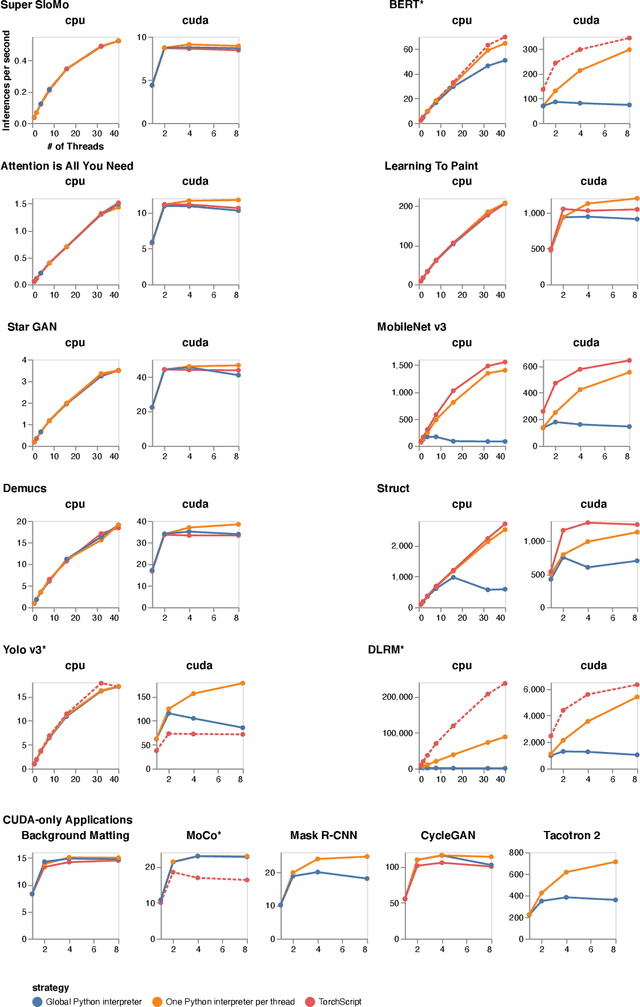
Python has become the de-facto language for training deep neural networks, coupling a large suite of scientific computing libraries with efficient libraries for tensor computation such as PyTorch or TensorFlow. However, when models are used for inference they are typically extracted from Python as TensorFlow graphs or TorchScript programs in order to meet performance and packaging constraints. The extraction process can be time consuming, impeding fast prototyping. We show how it is possible to meet these performance and packaging constraints while performing inference in Python. In particular, we present a way of using multiple Python interpreters within a single process to achieve scalable inference and describe a new container format for models that contains both native Python code and data. This approach simplifies the model deployment story by eliminating the model extraction step, and makes it easier to integrate existing performance-enhancing Python libraries. We evaluate our design on a suite of popular PyTorch models on Github, showing how they can be packaged in our inference format, and comparing their performance to TorchScript. For larger models, our packaged Python models perform the same as TorchScript, and for smaller models where there is some Python overhead, our multi-interpreter approach ensures inference is still scalable.
Intel nGraph: An Intermediate Representation, Compiler, and Executor for Deep Learning
Jan 30, 2018The Deep Learning (DL) community sees many novel topologies published each year. Achieving high performance on each new topology remains challenging, as each requires some level of manual effort. This issue is compounded by the proliferation of frameworks and hardware platforms. The current approach, which we call "direct optimization", requires deep changes within each framework to improve the training performance for each hardware backend (CPUs, GPUs, FPGAs, ASICs) and requires $\mathcal{O}(fp)$ effort; where $f$ is the number of frameworks and $p$ is the number of platforms. While optimized kernels for deep-learning primitives are provided via libraries like Intel Math Kernel Library for Deep Neural Networks (MKL-DNN), there are several compiler-inspired ways in which performance can be further optimized. Building on our experience creating neon (a fast deep learning library on GPUs), we developed Intel nGraph, a soon to be open-sourced C++ library to simplify the realization of optimized deep learning performance across frameworks and hardware platforms. Initially-supported frameworks include TensorFlow, MXNet, and Intel neon framework. Initial backends are Intel Architecture CPUs (CPU), the Intel(R) Nervana Neural Network Processor(R) (NNP), and NVIDIA GPUs. Currently supported compiler optimizations include efficient memory management and data layout abstraction. In this paper, we describe our overall architecture and its core components. In the future, we envision extending nGraph API support to a wider range of frameworks, hardware (including FPGAs and ASICs), and compiler optimizations (training versus inference optimizations, multi-node and multi-device scaling via efficient sub-graph partitioning, and HW-specific compounding of operations).