 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSAVMap: Structure-Aided Visual Mapping of Large-Scale 2.5D Manhattan Wireframes from Panoramic Video
Jun 01, 2026Precise 3D representations of industrial environments enable tasks such as robot localization and digital twin generation. We propose SAVMap, a method for generating a semantic wireframe map of warehouse shelf and light structures using only a panoramic video camera as the sensor input. Sequences of rectified images with shelf and ceiling-facing views are extracted from a panoramic video captured along the warehouse aisles. Using a semantic segmentation network front end, a set of sparse, semantic structure feature points (e.g., corners of shelf structures, centers of lights) are extracted from each image and tracked across the sequences. By accounting for real-world geometric relationships among the points such as Manhattan grids, a constrained structure-from-motion algorithm yields the 3D points that form a wireframe map. We demonstrate the scalability and accuracy of our proposal in a warehouse with 46 shelving rows, each with faces spanning 55\,m by 7\,m. From an hour of panoramic video content, we create wireframe maps for over 5000 shelf elements across the rows, achieving an aggregate mean absolute error of 4.8\,cm with respect to ground-truth.
GenAI for Systems: Recurring Challenges and Design Principles from Software to Silicon
Feb 16, 2026Generative AI is reshaping how computing systems are designed, optimized, and built, yet research remains fragmented across software, architecture, and chip design communities. This paper takes a cross-stack perspective, examining how generative models are being applied from code generation and distributed runtimes through hardware design space exploration to RTL synthesis, physical layout, and verification. Rather than reviewing each layer in isolation, we analyze how the same structural difficulties and effective responses recur across the stack. Our central finding is one of convergence. Despite the diversity of domains and tools, the field keeps encountering five recurring challenges (the feedback loop crisis, the tacit knowledge problem, trust and validation, co-design across boundaries, and the shift from determinism to dynamism) and keeps arriving at five design principles that independently emerge as effective responses (embracing hybrid approaches, designing for continuous feedback, separating concerns by role, matching methods to problem structure, and building on decades of systems knowledge). We organize these into a challenge--principle map that serves as a diagnostic and design aid, showing which principles have proven effective for which challenges across layers. Through concrete cross-stack examples, we show how systems navigate this map as they mature, and argue that the field needs shared engineering methodology, including common vocabularies, cross-layer benchmarks, and systematic design practices, so that progress compounds across communities rather than being rediscovered in each one. Our analysis covers more than 275 papers spanning eleven application areas across three layers of the computing stack, and distills open research questions that become visible only from a cross-layer vantage point.
The Llama 4 Herd: Architecture, Training, Evaluation, and Deployment Notes
Jan 15, 2026This document consolidates publicly reported technical details about Metas Llama 4 model family. It summarizes (i) released variants (Scout and Maverick) and the broader herd context including the previewed Behemoth teacher model, (ii) architectural characteristics beyond a high-level MoE description covering routed/shared-expert structure, early-fusion multimodality, and long-context design elements reported for Scout (iRoPE and length generalization strategies), (iii) training disclosures spanning pre-training, mid-training for long-context extension, and post-training methodology (lightweight SFT, online RL, and lightweight DPO) as described in release materials, (iv) developer-reported benchmark results for both base and instruction-tuned checkpoints, and (v) practical deployment constraints observed across major serving environments, including provider-specific context limits and quantization packaging. The manuscript also summarizes licensing obligations relevant to redistribution and derivative naming, and reviews publicly described safeguards and evaluation practices. The goal is to provide a compact technical reference for researchers and practitioners who need precise, source-backed facts about Llama 4.
TorchTitan: One-stop PyTorch native solution for production ready LLM pre-training
Oct 09, 2024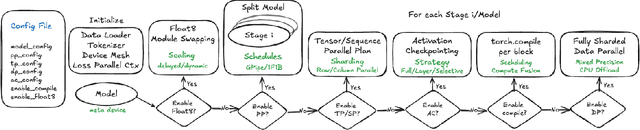



The development of large language models (LLMs) has been instrumental in advancing state-of-the-art natural language processing applications. Training LLMs with billions of parameters and trillions of tokens require sophisticated distributed systems that enable composing and comparing several state-of-the-art techniques in order to efficiently scale across thousands of accelerators. However, existing solutions are complex, scattered across multiple libraries/repositories, lack interoperability, and are cumbersome to maintain. Thus, curating and empirically comparing training recipes require non-trivial engineering effort. This paper introduces TorchTitan, an open-source, PyTorch-native distributed training system that unifies state-of-the-art techniques, streamlining integration and reducing overhead. TorchTitan enables 3D parallelism in a modular manner with elastic scaling, providing comprehensive logging, checkpointing, and debugging tools for production-ready training. It also incorporates hardware-software co-designed solutions, leveraging features like Float8 training and SymmetricMemory. As a flexible test bed, TorchTitan facilitates custom recipe curation and comparison, allowing us to develop optimized training recipes for Llama 3.1 and provide guidance on selecting techniques for maximum efficiency based on our experiences. We thoroughly assess TorchTitan on the Llama 3.1 family of LLMs, spanning 8 billion to 405 billion parameters, and showcase its exceptional performance, modular composability, and elastic scalability. By stacking training optimizations, we demonstrate accelerations of 65.08% with 1D parallelism at the 128-GPU scale (Llama 3.1 8B), an additional 12.59% with 2D parallelism at the 256-GPU scale (Llama 3.1 70B), and an additional 30% with 3D parallelism at the 512-GPU scale (Llama 3.1 405B) on NVIDIA H100 GPUs over optimized baselines.
Domain Adaptation of Networks for Camera Pose Estimation: Learning Camera Pose Estimation Without Pose Labels
Nov 29, 2021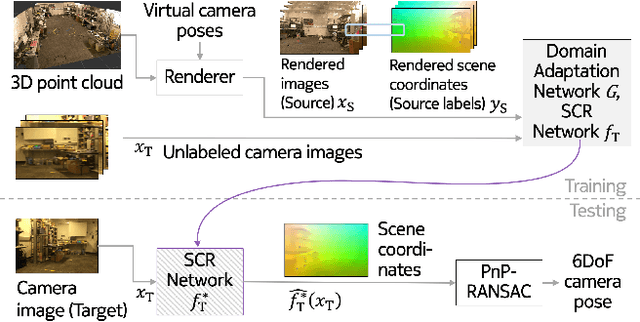
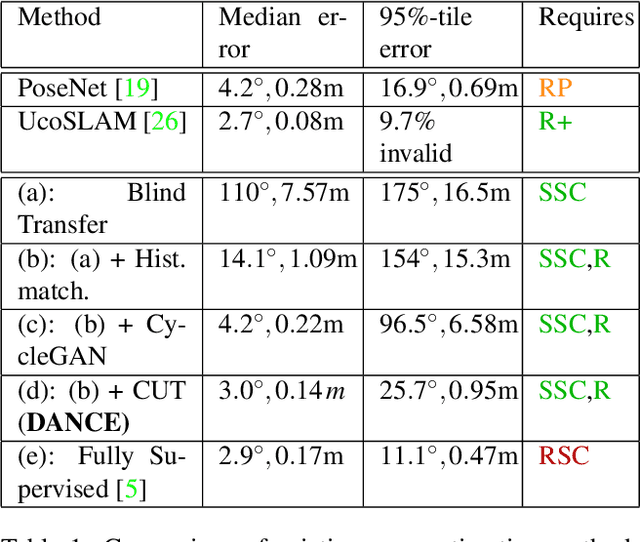
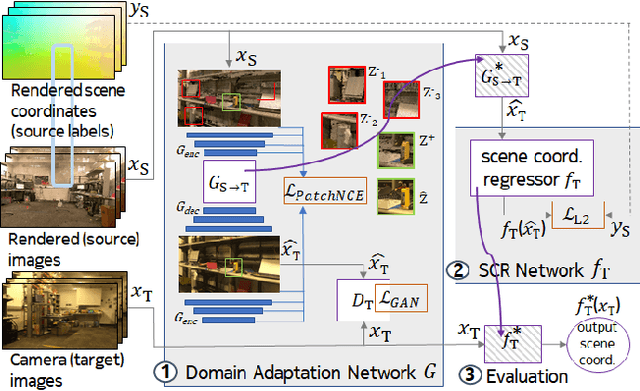

One of the key criticisms of deep learning is that large amounts of expensive and difficult-to-acquire training data are required in order to train models with high performance and good generalization capabilities. Focusing on the task of monocular camera pose estimation via scene coordinate regression (SCR), we describe a novel method, Domain Adaptation of Networks for Camera pose Estimation (DANCE), which enables the training of models without access to any labels on the target task. DANCE requires unlabeled images (without known poses, ordering, or scene coordinate labels) and a 3D representation of the space (e.g., a scanned point cloud), both of which can be captured with minimal effort using off-the-shelf commodity hardware. DANCE renders labeled synthetic images from the 3D model, and bridges the inevitable domain gap between synthetic and real images by applying unsupervised image-level domain adaptation techniques (unpaired image-to-image translation). When tested on real images, the SCR model trained with DANCE achieved comparable performance to its fully supervised counterpart (in both cases using PnP-RANSAC for final pose estimation) at a fraction of the cost. Our code and dataset are available at https://github.com/JackLangerman/dance
Feature Learning for Neural-Network-Based Positioning with Channel State Information
Oct 28, 2021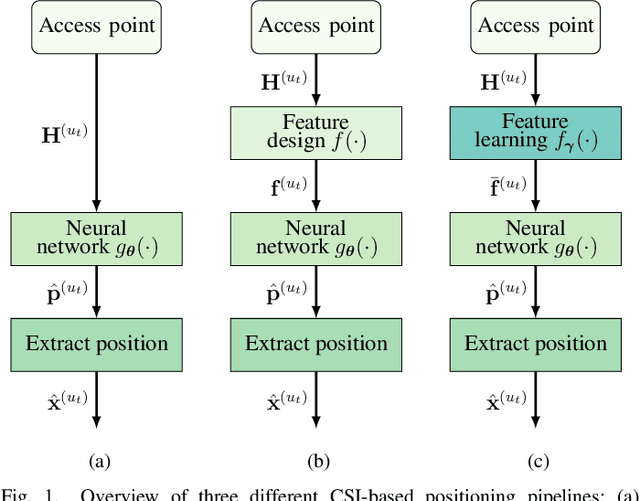
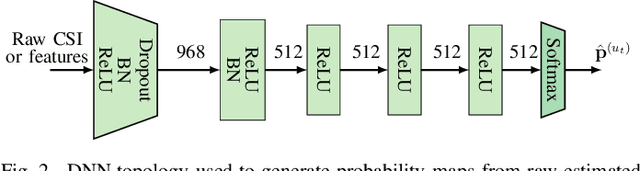
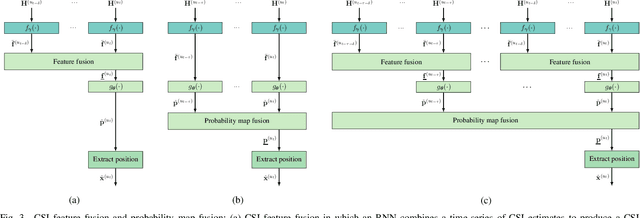
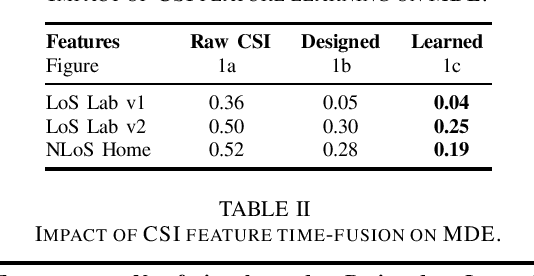
Recent channel state information (CSI)-based positioning pipelines rely on deep neural networks (DNNs) in order to learn a mapping from estimated CSI to position. Since real-world communication transceivers suffer from hardware impairments, CSI-based positioning systems typically rely on features that are designed by hand. In this paper, we propose a CSI-based positioning pipeline that directly takes raw CSI measurements and learns features using a structured DNN in order to generate probability maps describing the likelihood of the transmitter being at pre-defined grid points. To further improve the positioning accuracy of moving user equipments, we propose to fuse a time-series of learned CSI features or a time-series of probability maps. To demonstrate the efficacy of our methods, we perform experiments with real-world indoor line-of-sight (LoS) and non-LoS channel measurements. We show that CSI feature learning and time-series fusion can reduce the mean distance error by up to 2.5$\boldsymbol\times$ compared to the state-of-the-art.
Experimental Study on Probabilistic ToA and AoA Joint Localization in Real Indoor Environments
Feb 22, 2021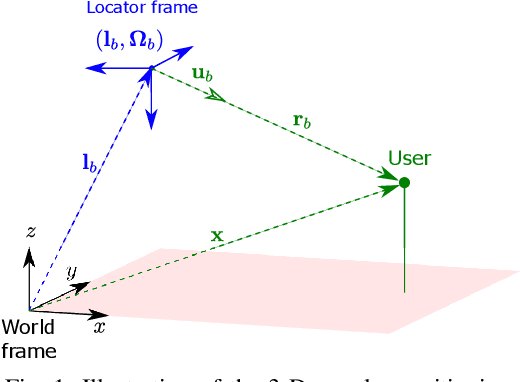


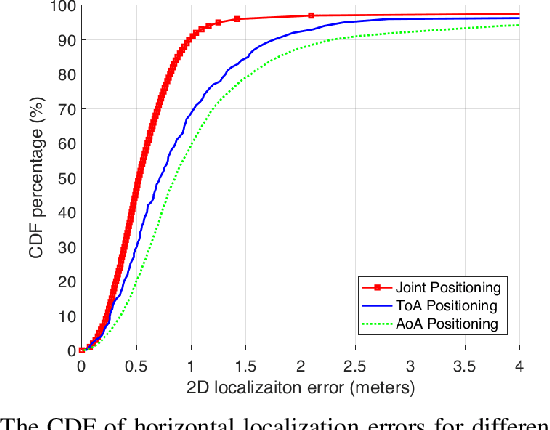
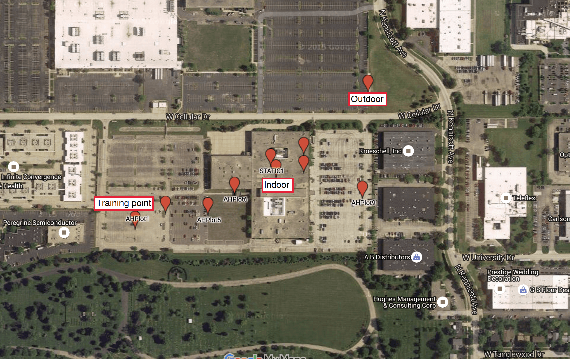
In this paper, we study probabilistic time-of-arrival (ToA) and angle-of-arrival (AoA) joint localization in real indoor environments. To mitigate the effects of multipath propagation, the joint localization algorithm incorporates into the likelihood function Gaussian mixture models (GMM) and the Von Mises-Fisher distribution to model time bias errors and angular uncertainty, respectively. We evaluate the algorithm performance using a proprietary prototype deployed in an indoor factory environment with infrastructure receivers in each of the four corners at the ceiling of a 10 meter by 20 meter section. The field test results show that our joint probabilistic localization algorithm significantly outperforms baselines using only ToA or AoA measurements and achieves 2-D sub-meter accuracy at the 90%-ile. We also numerically demonstrate that the joint localization algorithm is more robust to synchronization errors than the baseline using ToA measurements only.
Probabilistic Time of Arrival Localization
Oct 15, 2019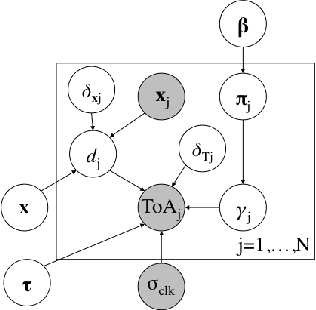

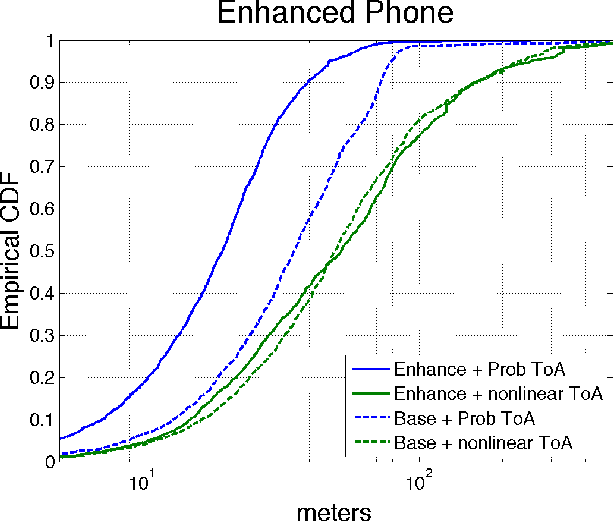
In this paper, we take a new approach for time of arrival geo-localization. We show that the main sources of error in metropolitan areas are due to environmental imperfections that bias our solutions, and that we can rely on a probabilistic model to learn and compensate for them. The resulting localization error is validated using measurements from a live LTE cellular network to be less than 10 meters, representing an order-of-magnitude improvement.