 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTorchTitan: One-stop PyTorch native solution for production ready LLM pre-training
Oct 09, 2024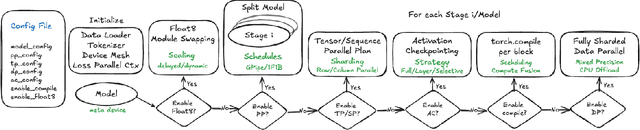



The development of large language models (LLMs) has been instrumental in advancing state-of-the-art natural language processing applications. Training LLMs with billions of parameters and trillions of tokens require sophisticated distributed systems that enable composing and comparing several state-of-the-art techniques in order to efficiently scale across thousands of accelerators. However, existing solutions are complex, scattered across multiple libraries/repositories, lack interoperability, and are cumbersome to maintain. Thus, curating and empirically comparing training recipes require non-trivial engineering effort. This paper introduces TorchTitan, an open-source, PyTorch-native distributed training system that unifies state-of-the-art techniques, streamlining integration and reducing overhead. TorchTitan enables 3D parallelism in a modular manner with elastic scaling, providing comprehensive logging, checkpointing, and debugging tools for production-ready training. It also incorporates hardware-software co-designed solutions, leveraging features like Float8 training and SymmetricMemory. As a flexible test bed, TorchTitan facilitates custom recipe curation and comparison, allowing us to develop optimized training recipes for Llama 3.1 and provide guidance on selecting techniques for maximum efficiency based on our experiences. We thoroughly assess TorchTitan on the Llama 3.1 family of LLMs, spanning 8 billion to 405 billion parameters, and showcase its exceptional performance, modular composability, and elastic scalability. By stacking training optimizations, we demonstrate accelerations of 65.08% with 1D parallelism at the 128-GPU scale (Llama 3.1 8B), an additional 12.59% with 2D parallelism at the 256-GPU scale (Llama 3.1 70B), and an additional 30% with 3D parallelism at the 512-GPU scale (Llama 3.1 405B) on NVIDIA H100 GPUs over optimized baselines.
PyTorch FSDP: Experiences on Scaling Fully Sharded Data Parallel
Apr 21, 2023It is widely acknowledged that large models have the potential to deliver superior performance across a broad range of domains. Despite the remarkable progress made in the field of machine learning systems research, which has enabled the development and exploration of large models, such abilities remain confined to a small group of advanced users and industry leaders, resulting in an implicit technical barrier for the wider community to access and leverage these technologies. In this paper, we introduce PyTorch Fully Sharded Data Parallel (FSDP) as an industry-grade solution for large model training. FSDP has been closely co-designed with several key PyTorch core components including Tensor implementation, dispatcher system, and CUDA memory caching allocator, to provide non-intrusive user experiences and high training efficiency. Additionally, FSDP natively incorporates a range of techniques and settings to optimize resource utilization across a variety of hardware configurations. The experimental results demonstrate that FSDP is capable of achieving comparable performance to Distributed Data Parallel while providing support for significantly larger models with near-linear scalability in terms of TFLOPS.
Get More With Less: Near Real-Time Image Clustering on Mobile Phones
Dec 09, 2015
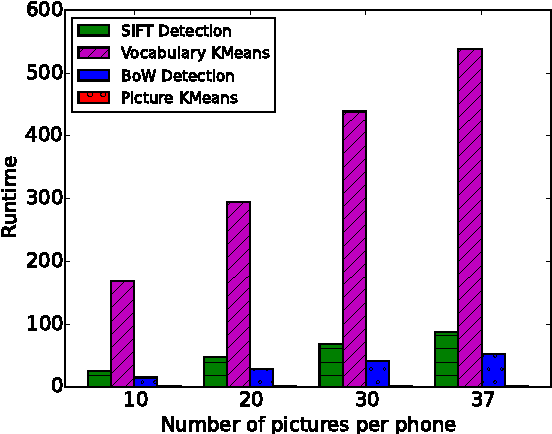
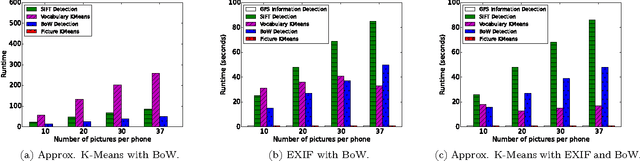
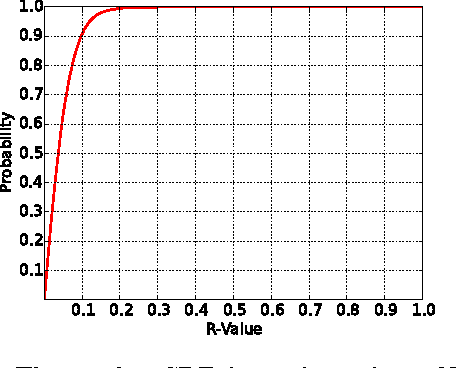
Machine learning algorithms, in conjunction with user data, hold the promise of revolutionizing the way we interact with our phones, and indeed their widespread adoption in the design of apps bear testimony to this promise. However, currently, the computationally expensive segments of the learning pipeline, such as feature extraction and model training, are offloaded to the cloud, resulting in an over-reliance on the network and under-utilization of computing resources available on mobile platforms. In this paper, we show that by combining the computing power distributed over a number of phones, judicious optimization choices, and contextual information it is possible to execute the end-to-end pipeline entirely on the phones at the edge of the network, efficiently. We also show that by harnessing the power of this combination, it is possible to execute a computationally expensive pipeline at near real-time. To demonstrate our approach, we implement an end-to-end image-processing pipeline -- that includes feature extraction, vocabulary learning, vectorization, and image clustering -- on a set of mobile phones. Our results show a 75% improvement over the standard, full pipeline implementation running on the phones without modification -- reducing the time to one minute under certain conditions. We believe that this result is a promising indication that fully distributed, infrastructure-less computing is possible on networks of mobile phones; enabling a new class of mobile applications that are less reliant on the cloud.