 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePyTorch FSDP: Experiences on Scaling Fully Sharded Data Parallel
Apr 21, 2023It is widely acknowledged that large models have the potential to deliver superior performance across a broad range of domains. Despite the remarkable progress made in the field of machine learning systems research, which has enabled the development and exploration of large models, such abilities remain confined to a small group of advanced users and industry leaders, resulting in an implicit technical barrier for the wider community to access and leverage these technologies. In this paper, we introduce PyTorch Fully Sharded Data Parallel (FSDP) as an industry-grade solution for large model training. FSDP has been closely co-designed with several key PyTorch core components including Tensor implementation, dispatcher system, and CUDA memory caching allocator, to provide non-intrusive user experiences and high training efficiency. Additionally, FSDP natively incorporates a range of techniques and settings to optimize resource utilization across a variety of hardware configurations. The experimental results demonstrate that FSDP is capable of achieving comparable performance to Distributed Data Parallel while providing support for significantly larger models with near-linear scalability in terms of TFLOPS.
Beyond the Imitation Game: Quantifying and extrapolating the capabilities of language models
Jun 10, 2022Language models demonstrate both quantitative improvement and new qualitative capabilities with increasing scale. Despite their potentially transformative impact, these new capabilities are as yet poorly characterized. In order to inform future research, prepare for disruptive new model capabilities, and ameliorate socially harmful effects, it is vital that we understand the present and near-future capabilities and limitations of language models. To address this challenge, we introduce the Beyond the Imitation Game benchmark (BIG-bench). BIG-bench currently consists of 204 tasks, contributed by 442 authors across 132 institutions. Task topics are diverse, drawing problems from linguistics, childhood development, math, common-sense reasoning, biology, physics, social bias, software development, and beyond. BIG-bench focuses on tasks that are believed to be beyond the capabilities of current language models. We evaluate the behavior of OpenAI's GPT models, Google-internal dense transformer architectures, and Switch-style sparse transformers on BIG-bench, across model sizes spanning millions to hundreds of billions of parameters. In addition, a team of human expert raters performed all tasks in order to provide a strong baseline. Findings include: model performance and calibration both improve with scale, but are poor in absolute terms (and when compared with rater performance); performance is remarkably similar across model classes, though with benefits from sparsity; tasks that improve gradually and predictably commonly involve a large knowledge or memorization component, whereas tasks that exhibit "breakthrough" behavior at a critical scale often involve multiple steps or components, or brittle metrics; social bias typically increases with scale in settings with ambiguous context, but this can be improved with prompting.
OPT: Open Pre-trained Transformer Language Models
May 05, 2022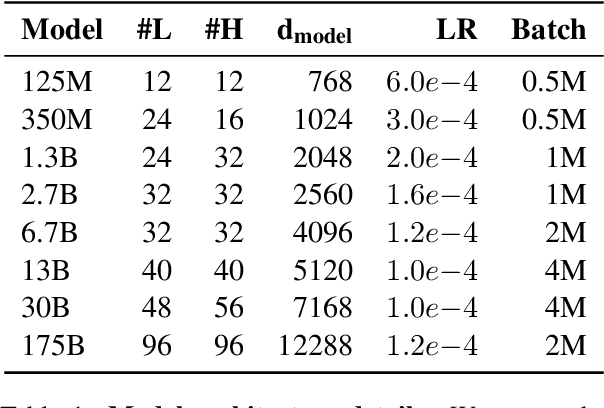
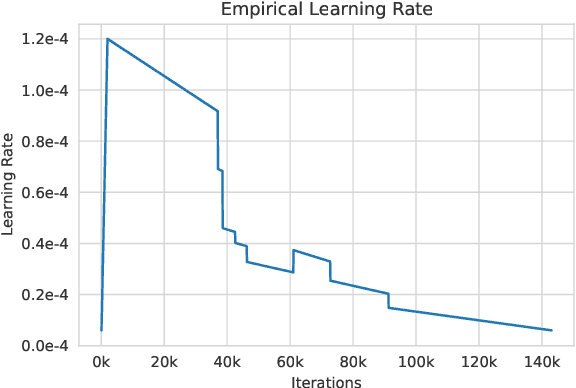
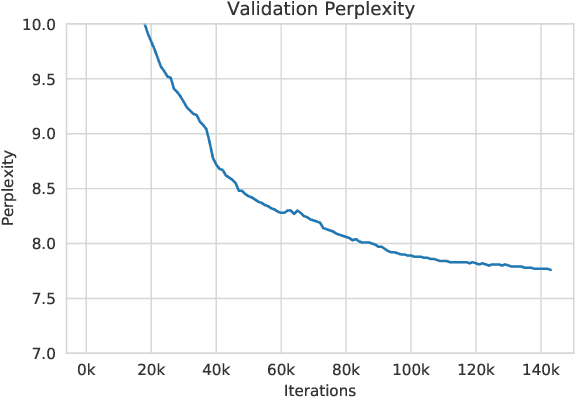
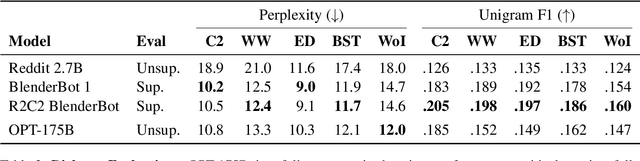
Large language models, which are often trained for hundreds of thousands of compute days, have shown remarkable capabilities for zero- and few-shot learning. Given their computational cost, these models are difficult to replicate without significant capital. For the few that are available through APIs, no access is granted to the full model weights, making them difficult to study. We present Open Pre-trained Transformers (OPT), a suite of decoder-only pre-trained transformers ranging from 125M to 175B parameters, which we aim to fully and responsibly share with interested researchers. We show that OPT-175B is comparable to GPT-3, while requiring only 1/7th the carbon footprint to develop. We are also releasing our logbook detailing the infrastructure challenges we faced, along with code for experimenting with all of the released models.
Efficient Language Modeling with Sparse all-MLP
Mar 16, 2022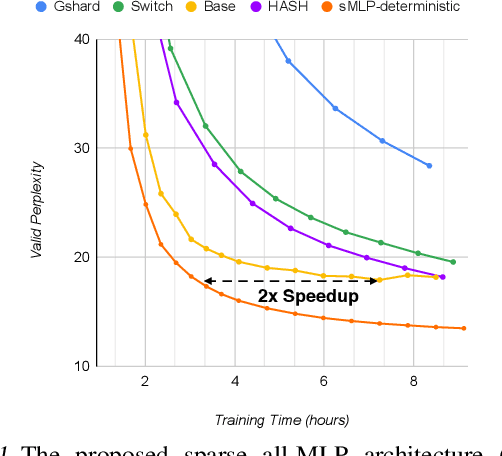

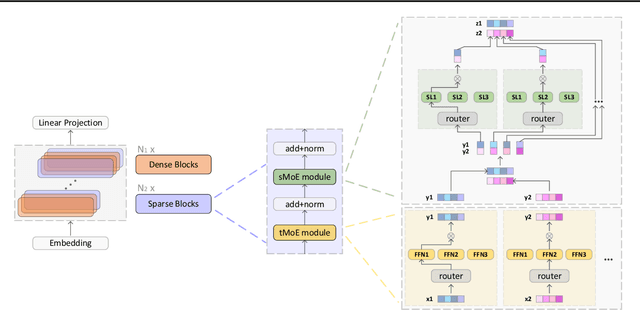

All-MLP architectures have attracted increasing interest as an alternative to attention-based models. In NLP, recent work like gMLP shows that all-MLPs can match Transformers in language modeling, but still lag behind in downstream tasks. In this work, we analyze the limitations of MLPs in expressiveness, and propose sparsely activated MLPs with mixture-of-experts (MoEs) in both feature and input (token) dimensions. Such sparse all-MLPs significantly increase model capacity and expressiveness while keeping the compute constant. We address critical challenges in incorporating conditional computation with two routing strategies. The proposed sparse all-MLP improves language modeling perplexity and obtains up to 2$\times$ improvement in training efficiency compared to both Transformer-based MoEs (GShard, Switch Transformer, Base Layers and HASH Layers) as well as dense Transformers and all-MLPs. Finally, we evaluate its zero-shot in-context learning performance on six downstream tasks, and find that it surpasses Transformer-based MoEs and dense Transformers.
Efficient Large Scale Language Modeling with Mixtures of Experts
Dec 20, 2021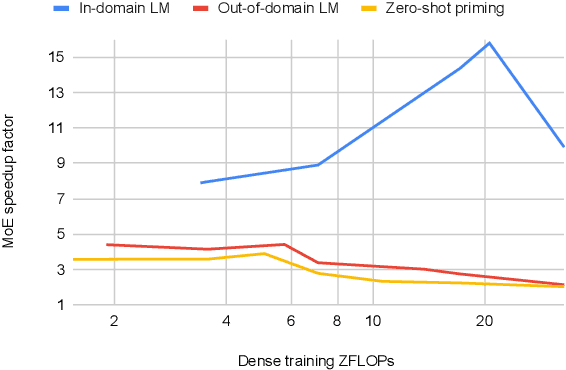
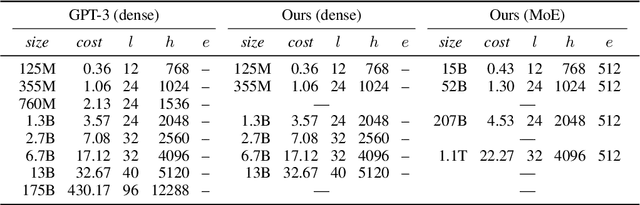
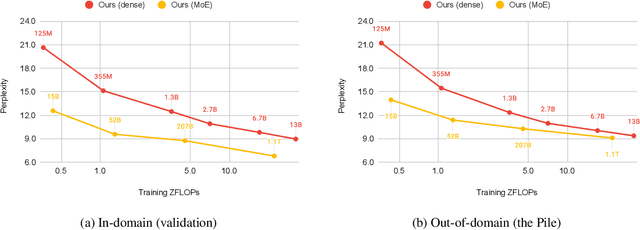
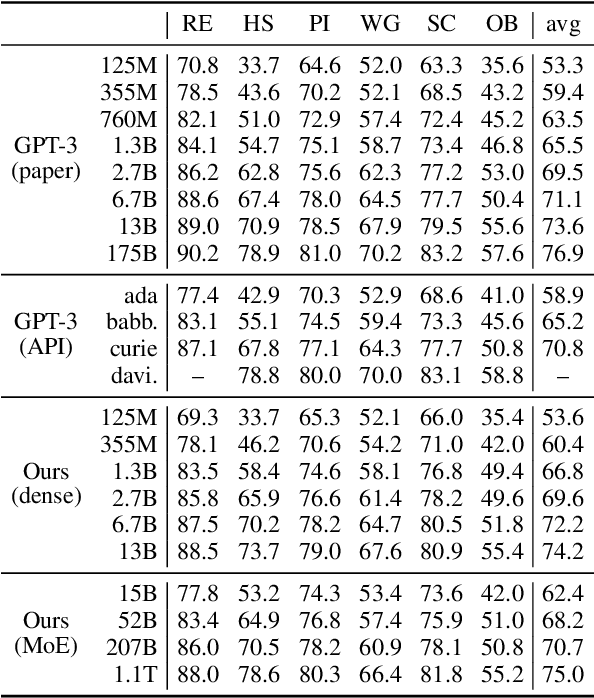
Mixture of Experts layers (MoEs) enable efficient scaling of language models through conditional computation. This paper presents a detailed empirical study of how autoregressive MoE language models scale in comparison with dense models in a wide range of settings: in- and out-of-domain language modeling, zero- and few-shot priming, and full fine-tuning. With the exception of fine-tuning, we find MoEs to be substantially more compute efficient. At more modest training budgets, MoEs can match the performance of dense models using $\sim$4 times less compute. This gap narrows at scale, but our largest MoE model (1.1T parameters) consistently outperforms a compute-equivalent dense model (6.7B parameters). Overall, this performance gap varies greatly across tasks and domains, suggesting that MoE and dense models generalize differently in ways that are worthy of future study. We make our code and models publicly available for research use.
Few-shot Learning with Multilingual Language Models
Dec 20, 2021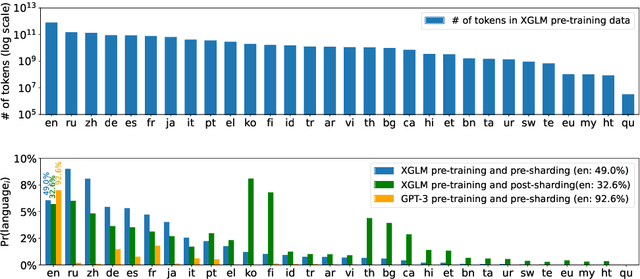
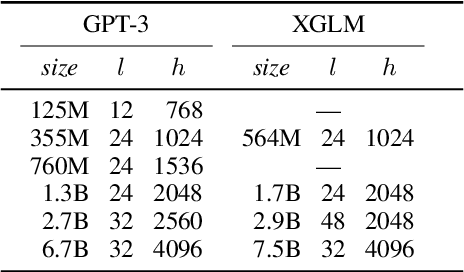
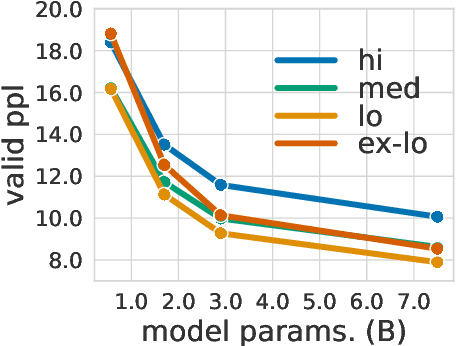

Large-scale autoregressive language models such as GPT-3 are few-shot learners that can perform a wide range of language tasks without fine-tuning. While these models are known to be able to jointly represent many different languages, their training data is dominated by English, potentially limiting their cross-lingual generalization. In this work, we train multilingual autoregressive language models on a balanced corpus covering a diverse set of languages, and study their few- and zero-shot learning capabilities in a wide range of tasks. Our largest model with 7.5 billion parameters sets new state of the art in few-shot learning in more than 20 representative languages, outperforming GPT-3 of comparable size in multilingual commonsense reasoning (with +7.4% absolute accuracy improvement in 0-shot settings and +9.4% in 4-shot settings) and natural language inference (+5.4% in each of 0-shot and 4-shot settings). On the FLORES-101 machine translation benchmark, our model outperforms GPT-3 on 171 out of 182 translation directions with 32 training examples, while surpassing the official supervised baseline in 45 directions. We present a detailed analysis of where the model succeeds and fails, showing in particular that it enables cross-lingual in-context learning on some tasks, while there is still room for improvement on surface form robustness and adaptation to tasks that do not have a natural cloze form. Finally, we evaluate our models in social value tasks such as hate speech detection in five languages and find it has limitations similar to comparable sized GPT-3 models.
NormFormer: Improved Transformer Pretraining with Extra Normalization
Nov 01, 2021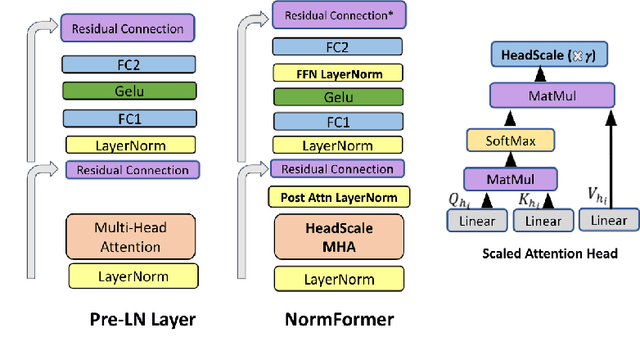

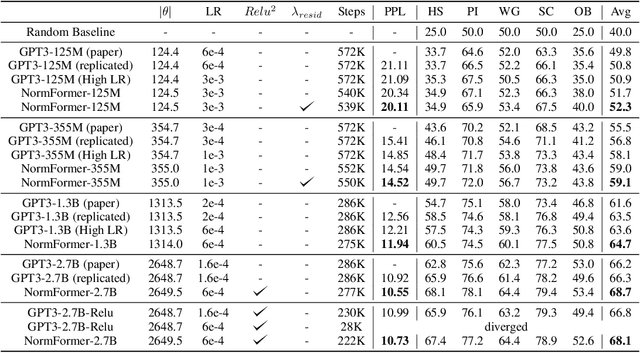
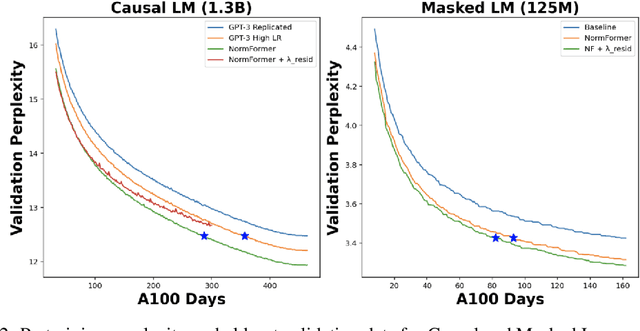
During pretraining, the Pre-LayerNorm transformer suffers from a gradient magnitude mismatch: gradients at early layers are much larger than at later layers. These issues can be alleviated by our proposed NormFormer architecture, which adds three normalization operations to each layer: a Layer Norm after self attention, head-wise scaling of self-attention outputs, and a Layer Norm after the first fully connected layer. The extra operations incur negligible compute cost (+0.4% parameter increase), but improve pretraining perplexity and downstream task performance for both causal and masked language models ranging from 125 Million to 2.7 Billion parameters. For example, adding NormFormer on top of our strongest 1.3B parameter baseline can reach equal perplexity 24% faster, or converge 0.27 perplexity better in the same compute budget. This model reaches GPT3-Large (1.3B) zero shot performance 60% faster. For masked language modeling, NormFormer improves fine-tuned GLUE performance by 1.9% on average. Code to train NormFormer models is available in fairseq https://github.com/pytorch/fairseq/tree/main/examples/normformer .
8-bit Optimizers via Block-wise Quantization
Oct 06, 2021
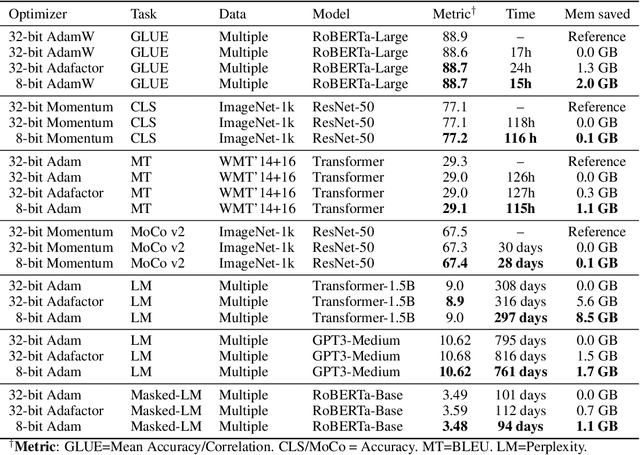
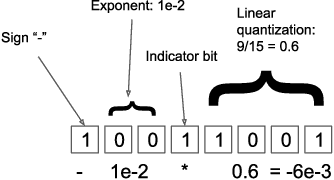

Stateful optimizers maintain gradient statistics over time, e.g., the exponentially smoothed sum (SGD with momentum) or squared sum (Adam) of past gradient values. This state can be used to accelerate optimization compared to plain stochastic gradient descent but uses memory that might otherwise be allocated to model parameters, thereby limiting the maximum size of models trained in practice. In this paper, we develop the first optimizers that use 8-bit statistics while maintaining the performance levels of using 32-bit optimizer states. To overcome the resulting computational, quantization, and stability challenges, we develop block-wise dynamic quantization. Block-wise quantization divides input tensors into smaller blocks that are independently quantized. Each block is processed in parallel across cores, yielding faster optimization and high precision quantization. To maintain stability and performance, we combine block-wise quantization with two additional changes: (1) dynamic quantization, a form of non-linear optimization that is precise for both large and small magnitude values, and (2) a stable embedding layer to reduce gradient variance that comes from the highly non-uniform distribution of input tokens in language models. As a result, our 8-bit optimizers maintain 32-bit performance with a small fraction of the memory footprint on a range of tasks, including 1.5B parameter language modeling, GLUE finetuning, ImageNet classification, WMT'14 machine translation, MoCo v2 contrastive ImageNet pretraining+finetuning, and RoBERTa pretraining, without changes to the original optimizer hyperparameters. We open-source our 8-bit optimizers as a drop-in replacement that only requires a two-line code change.
Pre-trained Summarization Distillation
Oct 28, 2020Recent state-of-the-art approaches to summarization utilize large pre-trained Transformer models. Distilling these models to smaller student models has become critically important for practical use; however there are many different distillation methods proposed by the NLP literature. Recent work on distilling BERT for classification and regression tasks shows strong performance using direct knowledge distillation. Alternatively, machine translation practitioners distill using pseudo-labeling, where a small model is trained on the translations of a larger model. A third, simpler approach is to 'shrink and fine-tune' (SFT), which avoids any explicit distillation by copying parameters to a smaller student model and then fine-tuning. We compare these three approaches for distillation of Pegasus and BART, the current and former state of the art, pre-trained summarization models, and find that SFT outperforms knowledge distillation and pseudo-labeling on the CNN/DailyMail dataset, but under-performs pseudo-labeling on the more abstractive XSUM dataset. PyTorch Code and checkpoints of different sizes are available through Hugging Face transformers here http://tiny.cc/4iy0tz.
Incrementally Improving Graph WaveNet Performance on Traffic Prediction
Dec 11, 2019
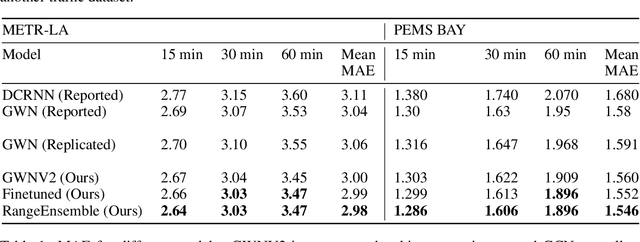


We present a series of modifications which improve upon Graph WaveNet's previously state-of-the-art performance on the METR-LA traffic prediction task. The goal of this task is to predict the future speed of traffic at each sensor in a network using the past hour of sensor readings. Graph WaveNet (GWN) is a spatio-temporal graph neural network which interleaves graph convolution to aggregate information from nearby sensors and dilated convolutions to aggregate information from the past. We improve GWN by (1) using better hyperparameters, (2) adding connections that allow larger gradients to flow back to the early convolutional layers, and (3) pretraining on an easier short-term traffic prediction task. These modifications reduce the mean absolute error by .06 on the METR-LA task, nearly equal to GWN's improvement over its predecessor. These improvements generalize to the PEMS-BAY dataset, with similar relative magnitude. We also show that ensembling separate models for short-and long-term predictions further improves performance. Code is available at https://github.com/sshleifer/Graph-WaveNet .