 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgebgGLUE: A Bulgarian General Language Understanding Evaluation Benchmark
Jun 07, 2023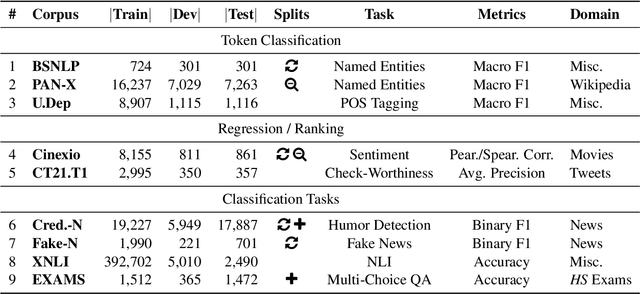
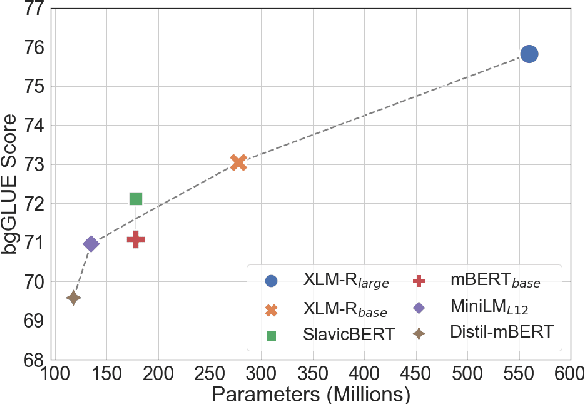

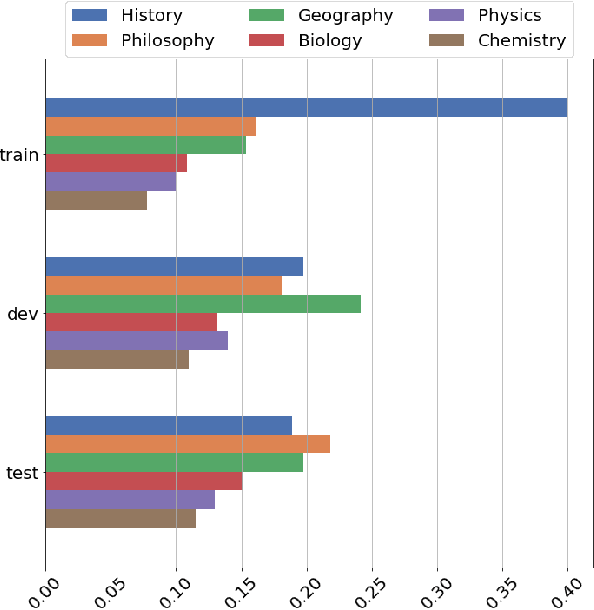
We present bgGLUE(Bulgarian General Language Understanding Evaluation), a benchmark for evaluating language models on Natural Language Understanding (NLU) tasks in Bulgarian. Our benchmark includes NLU tasks targeting a variety of NLP problems (e.g., natural language inference, fact-checking, named entity recognition, sentiment analysis, question answering, etc.) and machine learning tasks (sequence labeling, document-level classification, and regression). We run the first systematic evaluation of pre-trained language models for Bulgarian, comparing and contrasting results across the nine tasks in the benchmark. The evaluation results show strong performance on sequence labeling tasks, but there is a lot of room for improvement for tasks that require more complex reasoning. We make bgGLUE publicly available together with the fine-tuning and the evaluation code, as well as a public leaderboard at https://bgglue.github.io/, and we hope that it will enable further advancements in developing NLU models for Bulgarian.
* Accepted to ACL 2023 (Main Conference)
LEVER: Learning to Verify Language-to-Code Generation with Execution
Feb 16, 2023The advent of pre-trained code language models (CodeLMs) has lead to significant progress in language-to-code generation. State-of-the-art approaches in this area combine CodeLM decoding with sample pruning and reranking using test cases or heuristics based on the execution results. However, it is challenging to obtain test cases for many real-world language-to-code applications, and heuristics cannot well capture the semantic features of the execution results, such as data type and value range, which often indicates the correctness of the program. In this work, we propose LEVER, a simple approach to improve language-to-code generation by learning to verify the generated programs with their execution results. Specifically, we train verifiers to determine whether a program sampled from the CodeLM is correct or not based on the natural language input, the program itself and its execution results. The sampled programs are reranked by combining the verification score with the CodeLM generation probability, and marginalizing over programs with the same execution results. On four datasets across the domains of table QA, math QA and basic Python programming, LEVER consistently improves over the base CodeLMs (4.6% to 10.9% with code-davinci-002) and achieves new state-of-the-art results on all of them.
OPT-IML: Scaling Language Model Instruction Meta Learning through the Lens of Generalization
Dec 28, 2022



Recent work has shown that fine-tuning large pre-trained language models on a collection of tasks described via instructions, a.k.a. instruction-tuning, improves their zero and few-shot generalization to unseen tasks. However, there is a limited understanding of the performance trade-offs of different decisions made during the instruction-tuning process. These decisions include the scale and diversity of the instruction-tuning benchmark, different task sampling strategies, fine-tuning with and without demonstrations, training using specialized datasets for reasoning and dialogue, and finally, the fine-tuning objectives themselves. In this paper, we characterize the effect of instruction-tuning decisions on downstream task performance when scaling both model and benchmark sizes. To this end, we create OPT-IML Bench: a large benchmark for Instruction Meta-Learning (IML) of 2000 NLP tasks consolidated into task categories from 8 existing benchmarks, and prepare an evaluation framework to measure three types of model generalizations: to tasks from fully held-out categories, to held-out tasks from seen categories, and to held-out instances from seen tasks. Through the lens of this framework, we first present insights about instruction-tuning decisions as applied to OPT-30B and further exploit these insights to train OPT-IML 30B and 175B, which are instruction-tuned versions of OPT. OPT-IML demonstrates all three generalization abilities at both scales on four different evaluation benchmarks with diverse tasks and input formats -- PromptSource, FLAN, Super-NaturalInstructions, and UnifiedSKG. Not only does it significantly outperform OPT on all benchmarks but is also highly competitive with existing models fine-tuned on each specific benchmark. We release OPT-IML at both scales, together with the OPT-IML Bench evaluation framework.
Training Trajectories of Language Models Across Scales
Dec 19, 2022



Scaling up language models has led to unprecedented performance gains, but little is understood about how the training dynamics change as models get larger. How do language models of different sizes learn during pre-training? Why do larger language models demonstrate more desirable behaviors? In this paper, we analyze the intermediate training checkpoints of differently sized OPT models (Zhang et al.,2022)--from 125M to 175B parameters--on next-token prediction, sequence-level generation, and downstream tasks. We find that 1) at a given perplexity and independent of model sizes, a similar subset of training tokens see the most significant reduction in loss, with the rest stagnating or showing double-descent behavior; 2) early in training, all models learn to reduce the perplexity of grammatical sequences that contain hallucinations, with small models halting at this suboptimal distribution and larger ones eventually learning to assign these sequences lower probabilities; 3) perplexity is a strong predictor of in-context learning performance on 74 multiple-choice tasks from BIG-Bench, and this holds independent of the model size. Together, these results show that perplexity is more predictive of model behaviors than model size or training computation.
Complementary Explanations for Effective In-Context Learning
Nov 25, 2022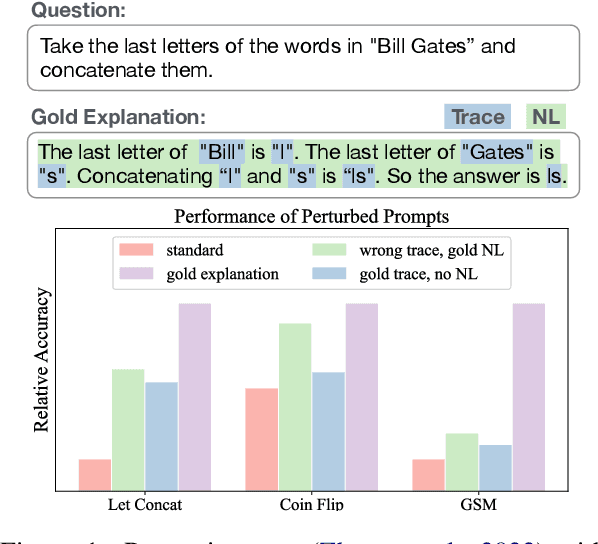



Large language models (LLMs) have exhibited remarkable capabilities in learning from explanations in prompts. Yet, there has been limited understanding of what makes explanations effective for in-context learning. This work aims to better understand the mechanisms by which explanations are used for in-context learning. We first study the impact of two different factors on prompting performance when using explanations: the computation trace (the way the solution is decomposed) and the natural language of the prompt. By perturbing explanations on three controlled tasks, we show that both factors contribute to the effectiveness of explanations, indicating that LLMs do faithfully follow the explanations to some extent. We further study how to form maximally effective sets of explanations for solving a given test query. We find that LLMs can benefit from the complementarity of the explanation set as they are able to fuse different reasoning specified by individual exemplars in prompts. Additionally, having relevant exemplars also contributes to more effective prompts. Therefore, we propose a maximal-marginal-relevance-based exemplar selection approach for constructing exemplar sets that are both relevant as well as complementary, which successfully improves the in-context learning performance across three real-world tasks on multiple LLMs.
Prompting ELECTRA: Few-Shot Learning with Discriminative Pre-Trained Models
Jun 08, 2022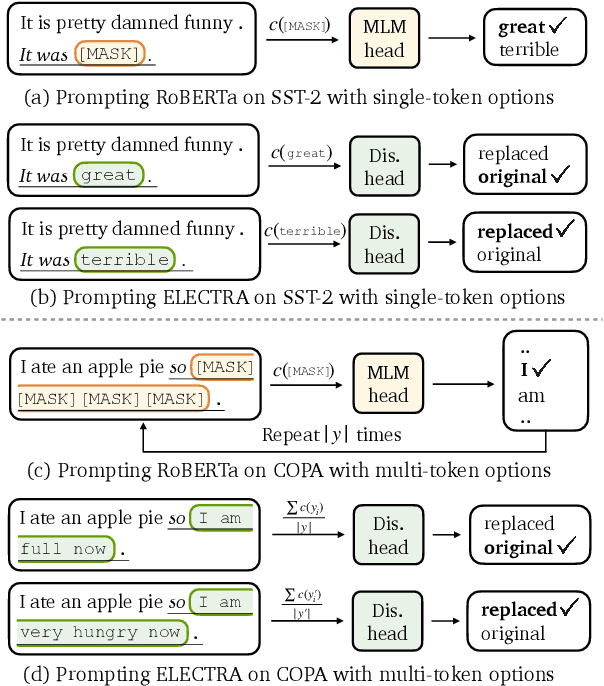
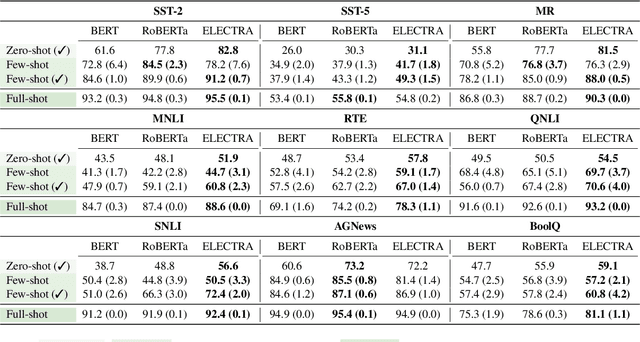
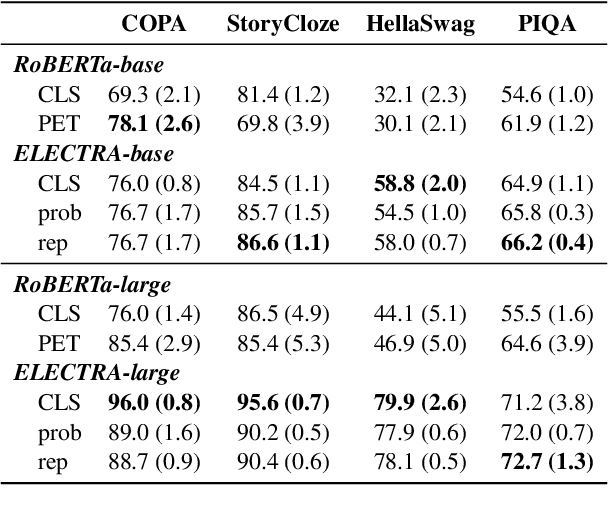
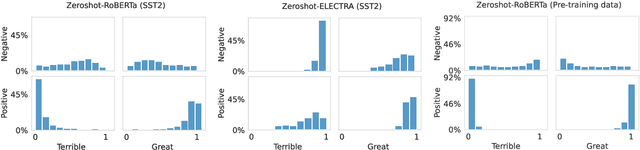
Pre-trained masked language models successfully perform few-shot learning by formulating downstream tasks as text infilling. However, as a strong alternative in full-shot settings, discriminative pre-trained models like ELECTRA do not fit into the paradigm. In this work, we adapt prompt-based few-shot learning to ELECTRA and show that it outperforms masked language models in a wide range of tasks. ELECTRA is pre-trained to distinguish if a token is generated or original. We naturally extend that to prompt-based few-shot learning by training to score the originality of the target options without introducing new parameters. Our method can be easily adapted to tasks involving multi-token predictions without extra computation overhead. Analysis shows that ELECTRA learns distributions that align better with downstream tasks.
ToKen: Task Decomposition and Knowledge Infusion for Few-Shot Hate Speech Detection
May 25, 2022



Hate speech detection is complex; it relies on commonsense reasoning, knowledge of stereotypes, and an understanding of social nuance that differs from one culture to the next. It is also difficult to collect a large-scale hate speech annotated dataset. In this work, we frame this problem as a few-shot learning task, and show significant gains with decomposing the task into its "constituent" parts. In addition, we see that infusing knowledge from reasoning datasets (e.g. Atomic2020) improves the performance even further. Moreover, we observe that the trained models generalize to out-of-distribution datasets, showing the superiority of task decomposition and knowledge infusion compared to previously used methods. Concretely, our method outperforms the baseline by 17.83% absolute gain in the 16-shot case.
On the Role of Bidirectionality in Language Model Pre-Training
May 24, 2022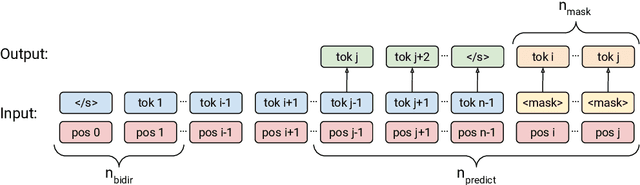

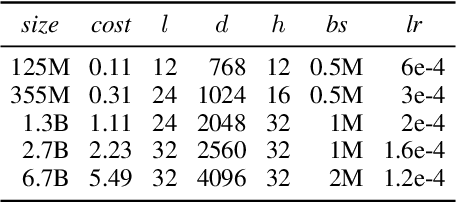
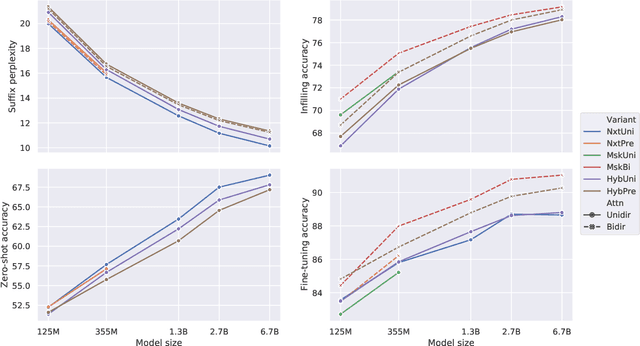
Prior work on language model pre-training has explored different architectures and learning objectives, but differences in data, hyperparameters and evaluation make a principled comparison difficult. In this work, we focus on bidirectionality as a key factor that differentiates existing approaches, and present a comprehensive study of its role in next token prediction, text infilling, zero-shot priming and fine-tuning. We propose a new framework that generalizes prior approaches, including fully unidirectional models like GPT, fully bidirectional models like BERT, and hybrid models like CM3 and prefix LM. Our framework distinguishes between two notions of bidirectionality (bidirectional context and bidirectional attention) and allows us to control each of them separately. We find that the optimal configuration is largely application-dependent (e.g., bidirectional attention is beneficial for fine-tuning and infilling, but harmful for next token prediction and zero-shot priming). We train models with up to 6.7B parameters, and find differences to remain consistent at scale. While prior work on scaling has focused on left-to-right autoregressive models, our results suggest that this approach comes with some trade-offs, and it might be worthwhile to develop very large bidirectional models.
Efficient Language Modeling with Sparse all-MLP
Mar 16, 2022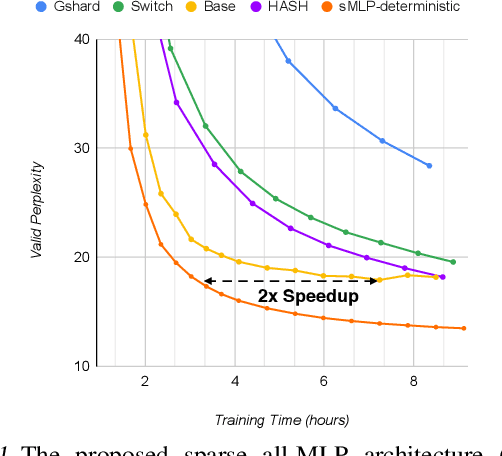

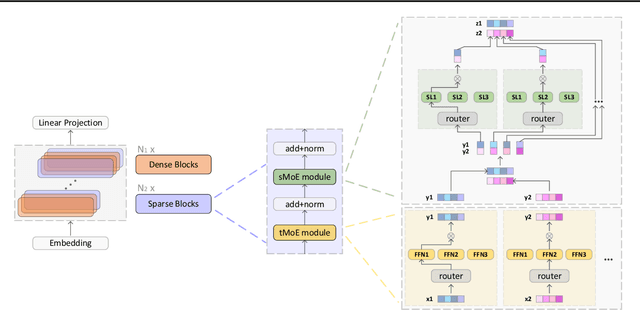

All-MLP architectures have attracted increasing interest as an alternative to attention-based models. In NLP, recent work like gMLP shows that all-MLPs can match Transformers in language modeling, but still lag behind in downstream tasks. In this work, we analyze the limitations of MLPs in expressiveness, and propose sparsely activated MLPs with mixture-of-experts (MoEs) in both feature and input (token) dimensions. Such sparse all-MLPs significantly increase model capacity and expressiveness while keeping the compute constant. We address critical challenges in incorporating conditional computation with two routing strategies. The proposed sparse all-MLP improves language modeling perplexity and obtains up to 2$\times$ improvement in training efficiency compared to both Transformer-based MoEs (GShard, Switch Transformer, Base Layers and HASH Layers) as well as dense Transformers and all-MLPs. Finally, we evaluate its zero-shot in-context learning performance on six downstream tasks, and find that it surpasses Transformer-based MoEs and dense Transformers.
Efficient Large Scale Language Modeling with Mixtures of Experts
Dec 20, 2021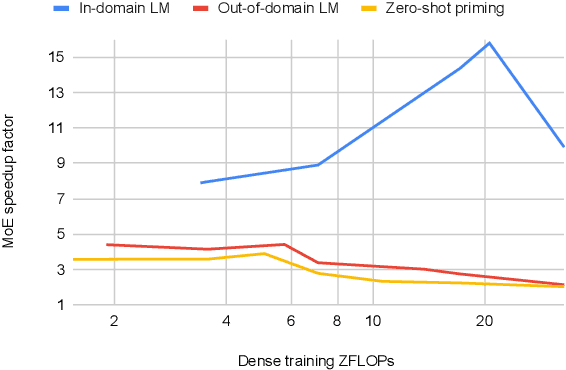
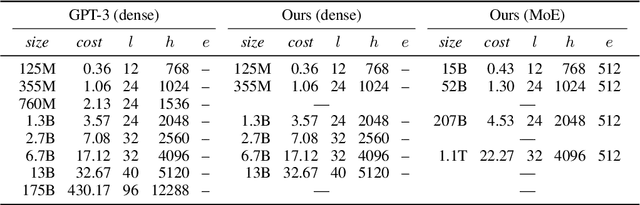
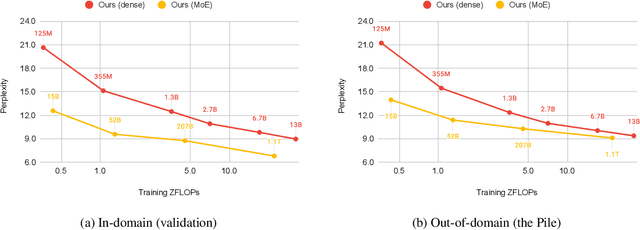
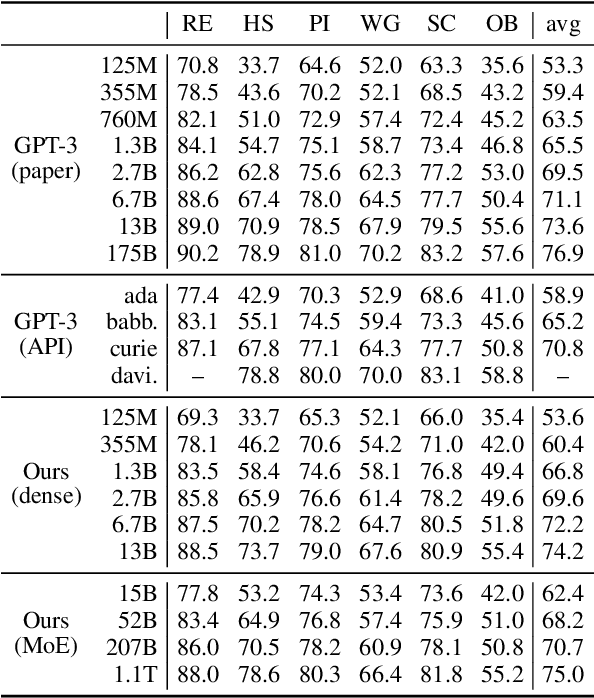
Mixture of Experts layers (MoEs) enable efficient scaling of language models through conditional computation. This paper presents a detailed empirical study of how autoregressive MoE language models scale in comparison with dense models in a wide range of settings: in- and out-of-domain language modeling, zero- and few-shot priming, and full fine-tuning. With the exception of fine-tuning, we find MoEs to be substantially more compute efficient. At more modest training budgets, MoEs can match the performance of dense models using $\sim$4 times less compute. This gap narrows at scale, but our largest MoE model (1.1T parameters) consistently outperforms a compute-equivalent dense model (6.7B parameters). Overall, this performance gap varies greatly across tasks and domains, suggesting that MoE and dense models generalize differently in ways that are worthy of future study. We make our code and models publicly available for research use.