 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeApproximating 1-Wasserstein Distance with Trees
Jun 24, 2022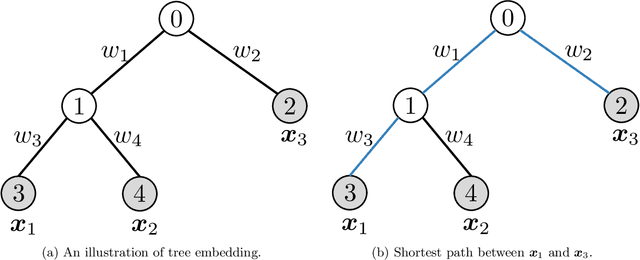
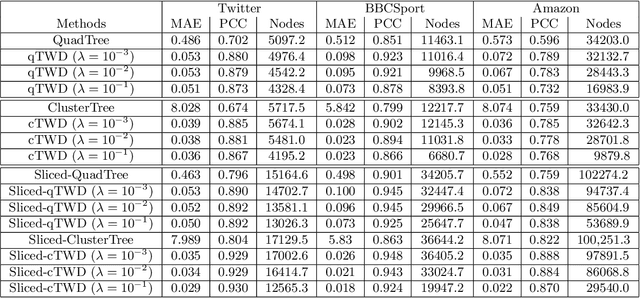
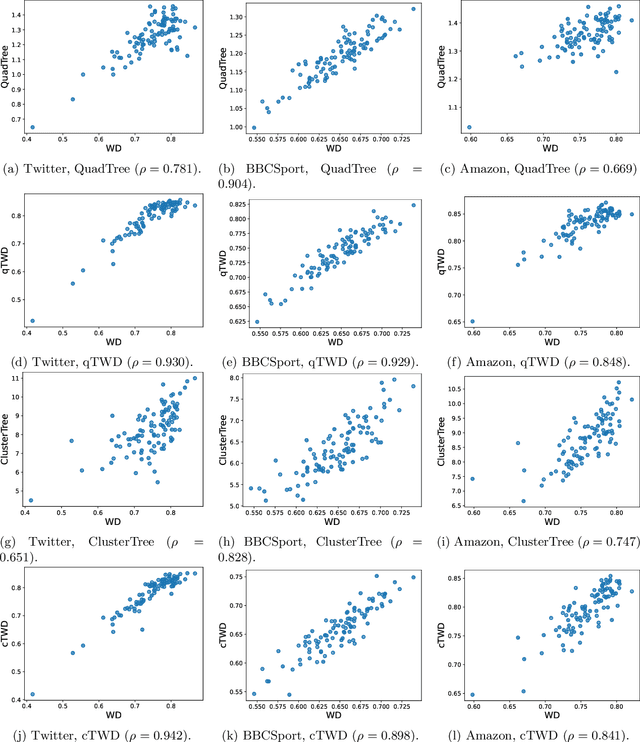
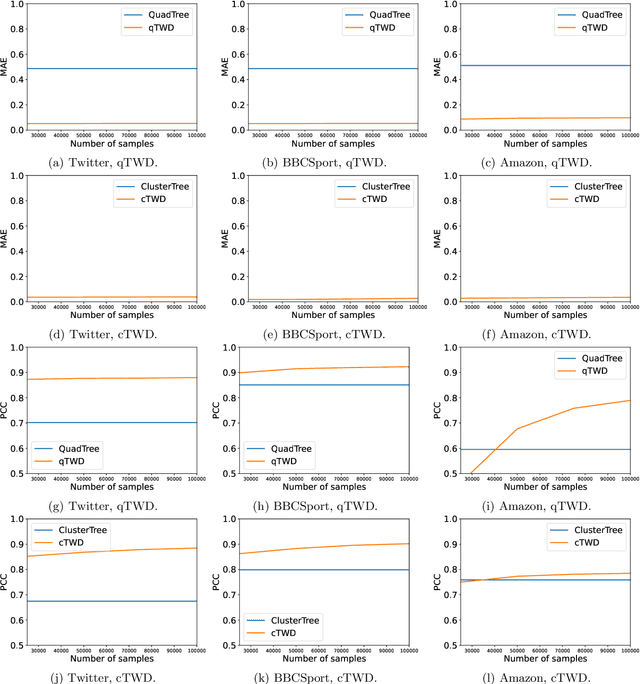
Wasserstein distance, which measures the discrepancy between distributions, shows efficacy in various types of natural language processing (NLP) and computer vision (CV) applications. One of the challenges in estimating Wasserstein distance is that it is computationally expensive and does not scale well for many distribution comparison tasks. In this paper, we aim to approximate the 1-Wasserstein distance by the tree-Wasserstein distance (TWD), where TWD is a 1-Wasserstein distance with tree-based embedding and can be computed in linear time with respect to the number of nodes on a tree. More specifically, we propose a simple yet efficient L1-regularized approach to learning the weights of the edges in a tree. To this end, we first show that the 1-Wasserstein approximation problem can be formulated as a distance approximation problem using the shortest path distance on a tree. We then show that the shortest path distance can be represented by a linear model and can be formulated as a Lasso-based regression problem. Owing to the convex formulation, we can obtain a globally optimal solution efficiently. Moreover, we propose a tree-sliced variant of these methods. Through experiments, we demonstrated that the weighted TWD can accurately approximate the original 1-Wasserstein distance.
ToKen: Task Decomposition and Knowledge Infusion for Few-Shot Hate Speech Detection
May 25, 2022



Hate speech detection is complex; it relies on commonsense reasoning, knowledge of stereotypes, and an understanding of social nuance that differs from one culture to the next. It is also difficult to collect a large-scale hate speech annotated dataset. In this work, we frame this problem as a few-shot learning task, and show significant gains with decomposing the task into its "constituent" parts. In addition, we see that infusing knowledge from reasoning datasets (e.g. Atomic2020) improves the performance even further. Moreover, we observe that the trained models generalize to out-of-distribution datasets, showing the superiority of task decomposition and knowledge infusion compared to previously used methods. Concretely, our method outperforms the baseline by 17.83% absolute gain in the 16-shot case.
Improving In-Context Few-Shot Learning via Self-Supervised Training
May 03, 2022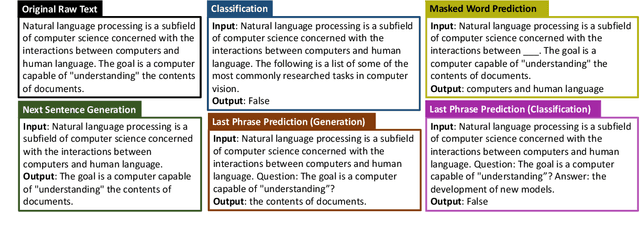

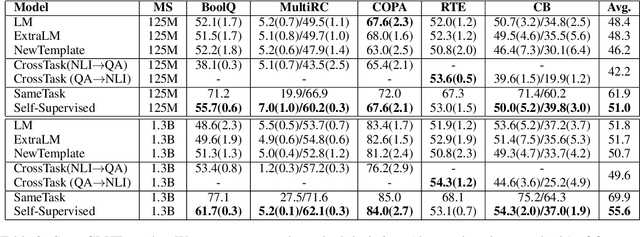

Self-supervised pretraining has made few-shot learning possible for many NLP tasks. But the pretraining objectives are not typically adapted specifically for in-context few-shot learning. In this paper, we propose to use self-supervision in an intermediate training stage between pretraining and downstream few-shot usage with the goal to teach the model to perform in-context few shot learning. We propose and evaluate four self-supervised objectives on two benchmarks. We find that the intermediate self-supervision stage produces models that outperform strong baselines. Ablation study shows that several factors affect the downstream performance, such as the amount of training data and the diversity of the self-supervised objectives. Human-annotated cross-task supervision and self-supervision are complementary. Qualitative analysis suggests that the self-supervised-trained models are better at following task requirements.
Efficient Large Scale Language Modeling with Mixtures of Experts
Dec 20, 2021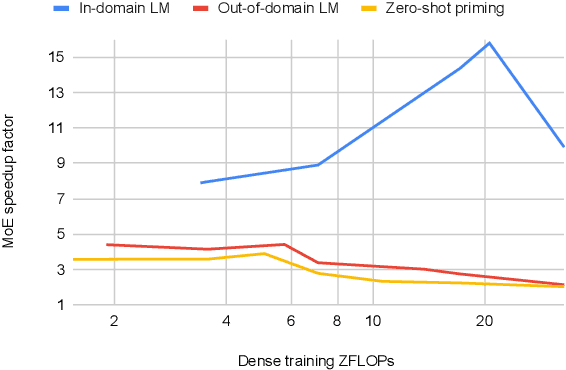
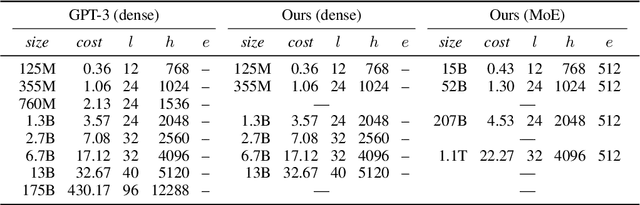
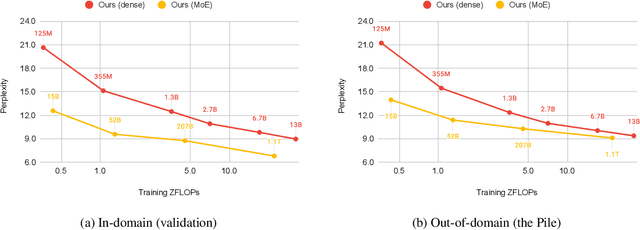
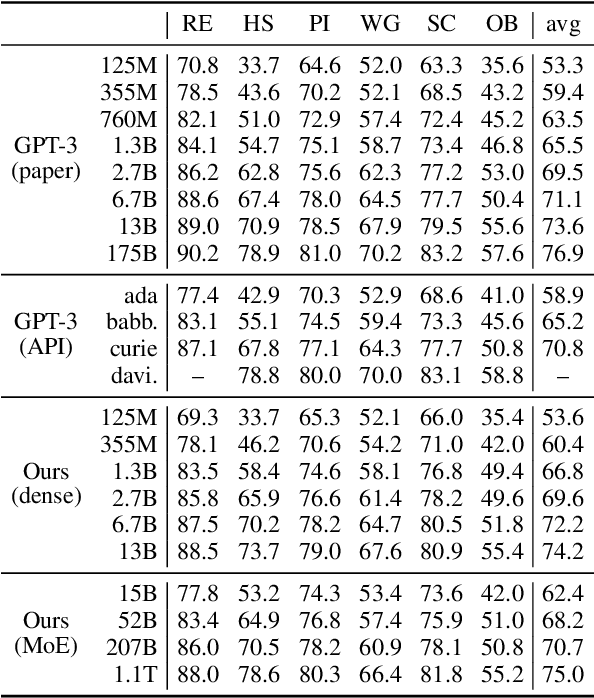
Mixture of Experts layers (MoEs) enable efficient scaling of language models through conditional computation. This paper presents a detailed empirical study of how autoregressive MoE language models scale in comparison with dense models in a wide range of settings: in- and out-of-domain language modeling, zero- and few-shot priming, and full fine-tuning. With the exception of fine-tuning, we find MoEs to be substantially more compute efficient. At more modest training budgets, MoEs can match the performance of dense models using $\sim$4 times less compute. This gap narrows at scale, but our largest MoE model (1.1T parameters) consistently outperforms a compute-equivalent dense model (6.7B parameters). Overall, this performance gap varies greatly across tasks and domains, suggesting that MoE and dense models generalize differently in ways that are worthy of future study. We make our code and models publicly available for research use.
Few-shot Learning with Multilingual Language Models
Dec 20, 2021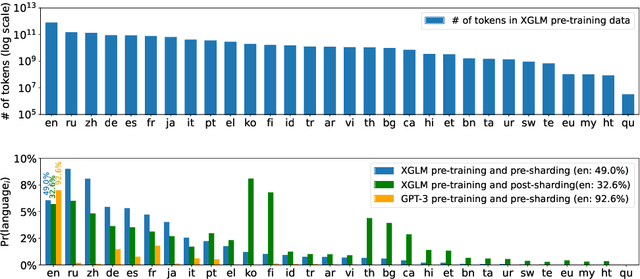
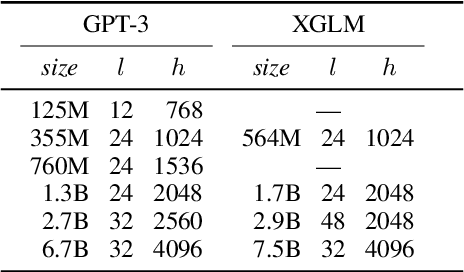
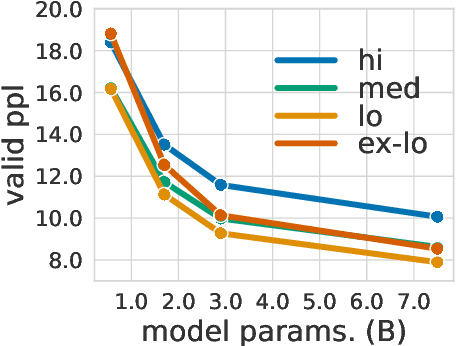

Large-scale autoregressive language models such as GPT-3 are few-shot learners that can perform a wide range of language tasks without fine-tuning. While these models are known to be able to jointly represent many different languages, their training data is dominated by English, potentially limiting their cross-lingual generalization. In this work, we train multilingual autoregressive language models on a balanced corpus covering a diverse set of languages, and study their few- and zero-shot learning capabilities in a wide range of tasks. Our largest model with 7.5 billion parameters sets new state of the art in few-shot learning in more than 20 representative languages, outperforming GPT-3 of comparable size in multilingual commonsense reasoning (with +7.4% absolute accuracy improvement in 0-shot settings and +9.4% in 4-shot settings) and natural language inference (+5.4% in each of 0-shot and 4-shot settings). On the FLORES-101 machine translation benchmark, our model outperforms GPT-3 on 171 out of 182 translation directions with 32 training examples, while surpassing the official supervised baseline in 45 directions. We present a detailed analysis of where the model succeeds and fails, showing in particular that it enables cross-lingual in-context learning on some tasks, while there is still room for improvement on surface form robustness and adaptation to tasks that do not have a natural cloze form. Finally, we evaluate our models in social value tasks such as hate speech detection in five languages and find it has limitations similar to comparable sized GPT-3 models.
Do Language Models Have Beliefs? Methods for Detecting, Updating, and Visualizing Model Beliefs
Nov 26, 2021

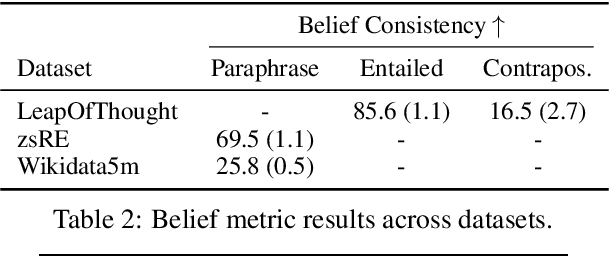
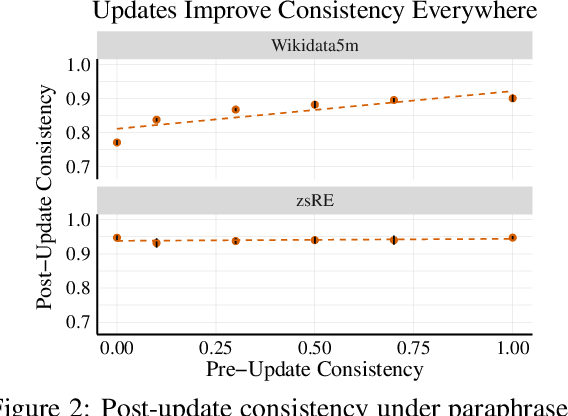
Do language models have beliefs about the world? Dennett (1995) famously argues that even thermostats have beliefs, on the view that a belief is simply an informational state decoupled from any motivational state. In this paper, we discuss approaches to detecting when models have beliefs about the world, and we improve on methods for updating model beliefs to be more truthful, with a focus on methods based on learned optimizers or hypernetworks. Our main contributions include: (1) new metrics for evaluating belief-updating methods that focus on the logical consistency of beliefs, (2) a training objective for Sequential, Local, and Generalizing model updates (SLAG) that improves the performance of learned optimizers, and (3) the introduction of the belief graph, which is a new form of interface with language models that shows the interdependencies between model beliefs. Our experiments suggest that models possess belief-like qualities to only a limited extent, but update methods can both fix incorrect model beliefs and greatly improve their consistency. Although off-the-shelf optimizers are surprisingly strong belief-updating baselines, our learned optimizers can outperform them in more difficult settings than have been considered in past work. Code is available at https://github.com/peterbhase/SLAG-Belief-Updating
Fixed Support Tree-Sliced Wasserstein Barycenter
Sep 08, 2021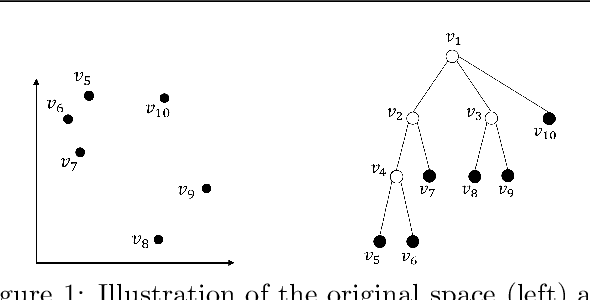
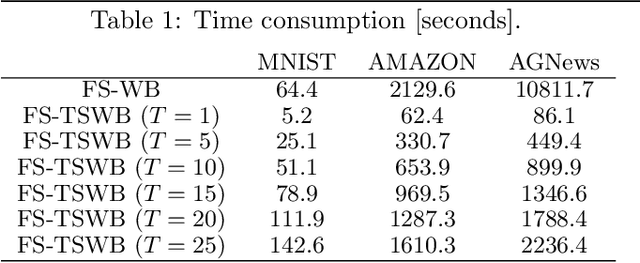
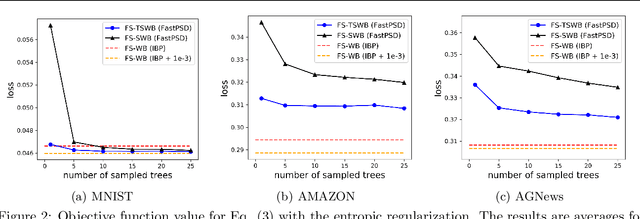
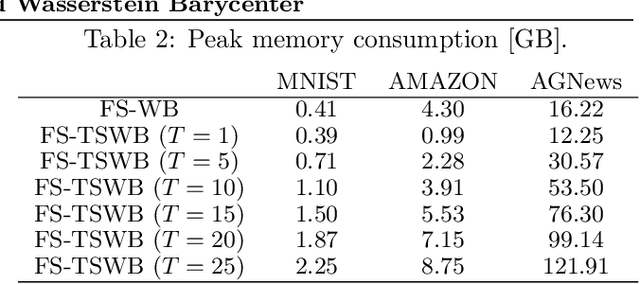
The Wasserstein barycenter has been widely studied in various fields, including natural language processing, and computer vision. However, it requires a high computational cost to solve the Wasserstein barycenter problem because the computation of the Wasserstein distance requires a quadratic time with respect to the number of supports. By contrast, the Wasserstein distance on a tree, called the tree-Wasserstein distance, can be computed in linear time and allows for the fast comparison of a large number of distributions. In this study, we propose a barycenter under the tree-Wasserstein distance, called the fixed support tree-Wasserstein barycenter (FS-TWB) and its extension, called the fixed support tree-sliced Wasserstein barycenter (FS-TSWB). More specifically, we first show that the FS-TWB and FS-TSWB problems are convex optimization problems and can be solved by using the projected subgradient descent. Moreover, we propose a more efficient algorithm to compute the subgradient and objective function value by using the properties of tree-Wasserstein barycenter problems. Through real-world experiments, we show that, by using the proposed algorithm, the FS-TWB and FS-TSWB can be solved two orders of magnitude faster than the original Wasserstein barycenter.
ProFormer: Towards On-Device LSH Projection Based Transformers
Apr 13, 2020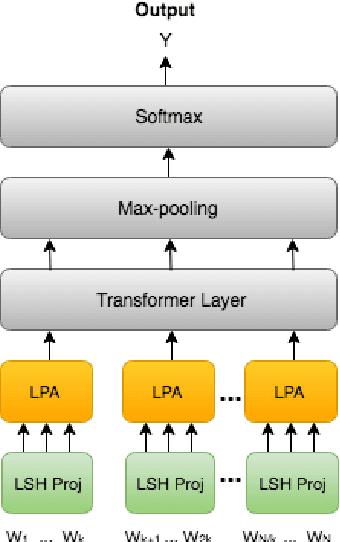

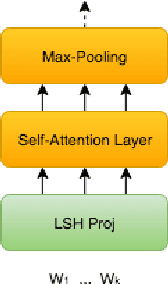
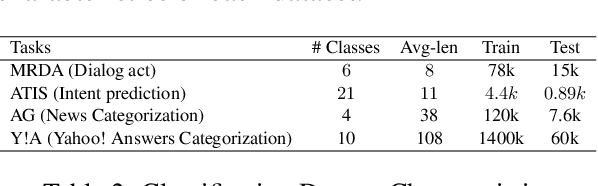
At the heart of text based neural models lay word representations, which are powerful but occupy a lot of memory making it challenging to deploy to devices with memory constraints such as mobile phones, watches and IoT. To surmount these challenges, we introduce ProFormer -- a projection based transformer architecture that is faster and lighter making it suitable to deploy to memory constraint devices and preserve user privacy. We use LSH projection layer to dynamically generate word representations on-the-fly without embedding lookup tables leading to significant memory footprint reduction from O(V.d) to O(T), where V is the vocabulary size, d is the embedding dimension size and T is the dimension of the LSH projection representation. We also propose a local projection attention (LPA) layer, which uses self-attention to transform the input sequence of N LSH word projections into a sequence of N/K representations reducing the computations quadratically by O(K^2). We evaluate ProFormer on multiple text classification tasks and observed improvements over prior state-of-the-art on-device approaches for short text classification and comparable performance for long text classification tasks. In comparison with a 2-layer BERT model, ProFormer reduced the embedding memory footprint from 92.16 MB to 1.3 KB and requires 16 times less computation overhead, which is very impressive making it the fastest and smallest on-device model.
Environment-agnostic Multitask Learning for Natural Language Grounded Navigation
Mar 12, 2020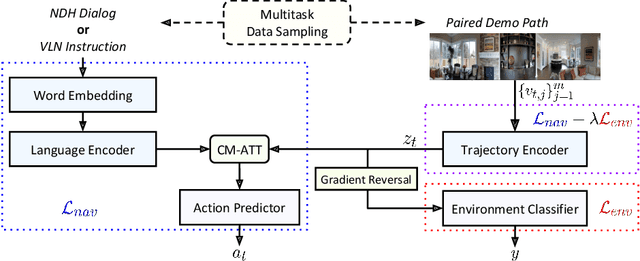
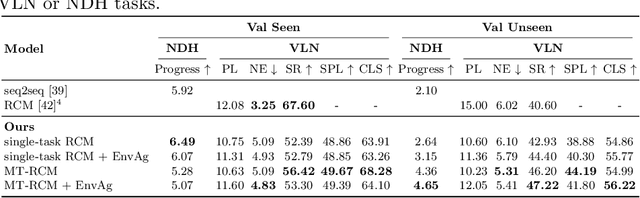
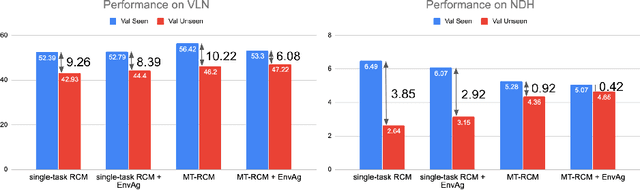
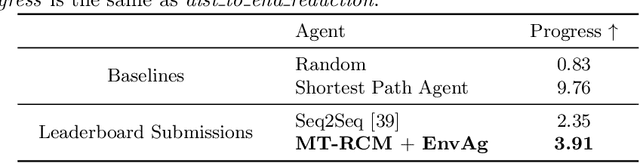
Recent research efforts enable study for natural language grounded navigation in photo-realistic environments, e.g., following natural language instructions or dialog. However, existing methods tend to overfit training data in seen environments and fail to generalize well in previously unseen environments. In order to close the gap between seen and unseen environments, we aim at learning a generalized navigation model from two novel perspectives: (1) we introduce a multitask navigation model that can be seamlessly trained on both Vision-Language Navigation (VLN) and Navigation from Dialog History (NDH) tasks, which benefits from richer natural language guidance and effectively transfers knowledge across tasks; (2) we propose to learn environment-agnostic representations for the navigation policy that are invariant among the environments seen during training, thus generalizing better on unseen environments. Extensive experiments show that training with environment-agnostic multitask learning objective significantly reduces the performance gap between seen and unseen environments and the navigation agent so trained outperforms the baselines on unseen environments by 16% (relative measure on success rate) on VLN and 120% (goal progress) on NDH. Our submission to the CVDN leaderboard establishes a new state-of-the-art for the NDH task outperforming the existing best model by more than 66% (goal progress) on the holdout test set. The code for training the navigation model using environment-agnostic multitask learning is available at https://github.com/google-research/valan.
SemEval-2013 Task 2: Sentiment Analysis in Twitter
Dec 14, 2019

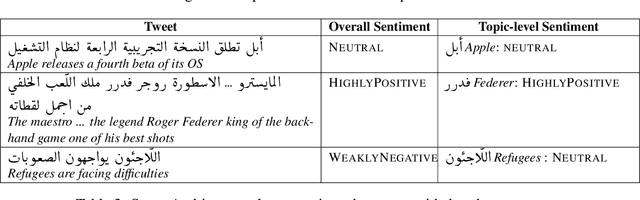
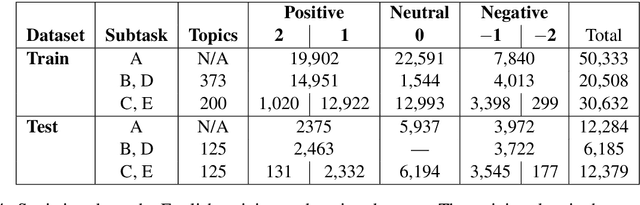
In recent years, sentiment analysis in social media has attracted a lot of research interest and has been used for a number of applications. Unfortunately, research has been hindered by the lack of suitable datasets, complicating the comparison between approaches. To address this issue, we have proposed SemEval-2013 Task 2: Sentiment Analysis in Twitter, which included two subtasks: A, an expression-level subtask, and B, a message-level subtask. We used crowdsourcing on Amazon Mechanical Turk to label a large Twitter training dataset along with additional test sets of Twitter and SMS messages for both subtasks. All datasets used in the evaluation are released to the research community. The task attracted significant interest and a total of 149 submissions from 44 teams. The best-performing team achieved an F1 of 88.9% and 69% for subtasks A and B, respectively.
* Sentiment analysis, microblog sentiment analysis, Twitter opinion mining, SMS