 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeByte Latent Transformer: Patches Scale Better Than Tokens
Dec 13, 2024We introduce the Byte Latent Transformer (BLT), a new byte-level LLM architecture that, for the first time, matches tokenization-based LLM performance at scale with significant improvements in inference efficiency and robustness. BLT encodes bytes into dynamically sized patches, which serve as the primary units of computation. Patches are segmented based on the entropy of the next byte, allocating more compute and model capacity where increased data complexity demands it. We present the first FLOP controlled scaling study of byte-level models up to 8B parameters and 4T training bytes. Our results demonstrate the feasibility of scaling models trained on raw bytes without a fixed vocabulary. Both training and inference efficiency improve due to dynamically selecting long patches when data is predictable, along with qualitative improvements on reasoning and long tail generalization. Overall, for fixed inference costs, BLT shows significantly better scaling than tokenization-based models, by simultaneously growing both patch and model size.
Mixture-of-Transformers: A Sparse and Scalable Architecture for Multi-Modal Foundation Models
Nov 07, 2024

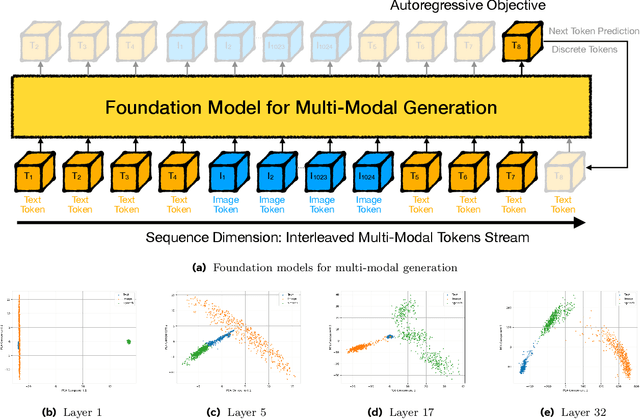

The development of large language models (LLMs) has expanded to multi-modal systems capable of processing text, images, and speech within a unified framework. Training these models demands significantly larger datasets and computational resources compared to text-only LLMs. To address the scaling challenges, we introduce Mixture-of-Transformers (MoT), a sparse multi-modal transformer architecture that significantly reduces pretraining computational costs. MoT decouples non-embedding parameters of the model by modality -- including feed-forward networks, attention matrices, and layer normalization -- enabling modality-specific processing with global self-attention over the full input sequence. We evaluate MoT across multiple settings and model scales. In the Chameleon 7B setting (autoregressive text-and-image generation), MoT matches the dense baseline's performance using only 55.8\% of the FLOPs. When extended to include speech, MoT reaches speech performance comparable to the dense baseline with only 37.2\% of the FLOPs. In the Transfusion setting, where text and image are trained with different objectives, a 7B MoT model matches the image modality performance of the dense baseline with one third of the FLOPs, and a 760M MoT model outperforms a 1.4B dense baseline across key image generation metrics. System profiling further highlights MoT's practical benefits, achieving dense baseline image quality in 47.2\% of the wall-clock time and text quality in 75.6\% of the wall-clock time (measured on AWS p4de.24xlarge instances with NVIDIA A100 GPUs).
MoMa: Efficient Early-Fusion Pre-training with Mixture of Modality-Aware Experts
Jul 31, 2024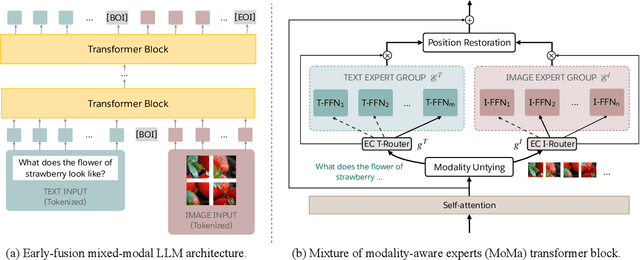

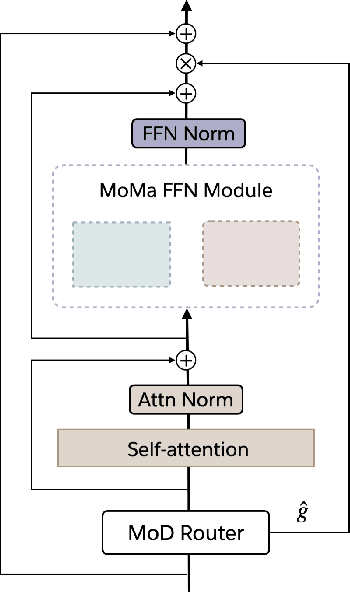
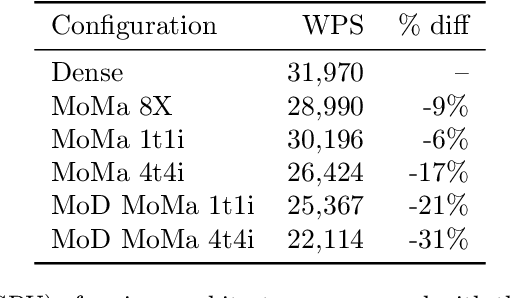
We introduce MoMa, a novel modality-aware mixture-of-experts (MoE) architecture designed for pre-training mixed-modal, early-fusion language models. MoMa processes images and text in arbitrary sequences by dividing expert modules into modality-specific groups. These groups exclusively process designated tokens while employing learned routing within each group to maintain semantically informed adaptivity. Our empirical results reveal substantial pre-training efficiency gains through this modality-specific parameter allocation. Under a 1-trillion-token training budget, the MoMa 1.4B model, featuring 4 text experts and 4 image experts, achieves impressive FLOPs savings: 3.7x overall, with 2.6x for text and 5.2x for image processing compared to a compute-equivalent dense baseline, measured by pre-training loss. This outperforms the standard expert-choice MoE with 8 mixed-modal experts, which achieves 3x overall FLOPs savings (3x for text, 2.8x for image). Combining MoMa with mixture-of-depths (MoD) further improves pre-training FLOPs savings to 4.2x overall (text: 3.4x, image: 5.3x), although this combination hurts performance in causal inference due to increased sensitivity to router accuracy. These results demonstrate MoMa's potential to significantly advance the efficiency of mixed-modal, early-fusion language model pre-training, paving the way for more resource-efficient and capable multimodal AI systems.
Instruction-tuned Language Models are Better Knowledge Learners
Feb 20, 2024



In order for large language model (LLM)-based assistants to effectively adapt to evolving information needs, it must be possible to update their factual knowledge through continued training on new data. The standard recipe for doing so involves continued pre-training on new documents followed by instruction-tuning on question-answer (QA) pairs. However, we find that LLMs trained with this recipe struggle to answer questions, even though the perplexity of documents is minimized. We found that QA pairs are generally straightforward, while documents are more complex, weaving many factual statements together in an intricate manner. Therefore, we hypothesize that it is beneficial to expose LLMs to QA pairs before continued pre-training on documents so that the process of encoding knowledge from complex documents takes into account how this knowledge is accessed through questions. Based on this, we propose pre-instruction-tuning (PIT), a method that instruction-tunes on questions prior to training on documents. This contrasts with standard instruction-tuning, which learns how to extract knowledge after training on documents. Extensive experiments and ablation studies demonstrate that PIT significantly enhances the ability of LLMs to absorb knowledge from new documents, outperforming standard instruction-tuning by 17.8%.
OPT-IML: Scaling Language Model Instruction Meta Learning through the Lens of Generalization
Dec 28, 2022



Recent work has shown that fine-tuning large pre-trained language models on a collection of tasks described via instructions, a.k.a. instruction-tuning, improves their zero and few-shot generalization to unseen tasks. However, there is a limited understanding of the performance trade-offs of different decisions made during the instruction-tuning process. These decisions include the scale and diversity of the instruction-tuning benchmark, different task sampling strategies, fine-tuning with and without demonstrations, training using specialized datasets for reasoning and dialogue, and finally, the fine-tuning objectives themselves. In this paper, we characterize the effect of instruction-tuning decisions on downstream task performance when scaling both model and benchmark sizes. To this end, we create OPT-IML Bench: a large benchmark for Instruction Meta-Learning (IML) of 2000 NLP tasks consolidated into task categories from 8 existing benchmarks, and prepare an evaluation framework to measure three types of model generalizations: to tasks from fully held-out categories, to held-out tasks from seen categories, and to held-out instances from seen tasks. Through the lens of this framework, we first present insights about instruction-tuning decisions as applied to OPT-30B and further exploit these insights to train OPT-IML 30B and 175B, which are instruction-tuned versions of OPT. OPT-IML demonstrates all three generalization abilities at both scales on four different evaluation benchmarks with diverse tasks and input formats -- PromptSource, FLAN, Super-NaturalInstructions, and UnifiedSKG. Not only does it significantly outperform OPT on all benchmarks but is also highly competitive with existing models fine-tuned on each specific benchmark. We release OPT-IML at both scales, together with the OPT-IML Bench evaluation framework.
Complementary Explanations for Effective In-Context Learning
Nov 25, 2022Large language models (LLMs) have exhibited remarkable capabilities in learning from explanations in prompts. Yet, there has been limited understanding of what makes explanations effective for in-context learning. This work aims to better understand the mechanisms by which explanations are used for in-context learning. We first study the impact of two different factors on prompting performance when using explanations: the computation trace (the way the solution is decomposed) and the natural language of the prompt. By perturbing explanations on three controlled tasks, we show that both factors contribute to the effectiveness of explanations, indicating that LLMs do faithfully follow the explanations to some extent. We further study how to form maximally effective sets of explanations for solving a given test query. We find that LLMs can benefit from the complementarity of the explanation set as they are able to fuse different reasoning specified by individual exemplars in prompts. Additionally, having relevant exemplars also contributes to more effective prompts. Therefore, we propose a maximal-marginal-relevance-based exemplar selection approach for constructing exemplar sets that are both relevant as well as complementary, which successfully improves the in-context learning performance across three real-world tasks on multiple LLMs.
Efficient Large Scale Language Modeling with Mixtures of Experts
Dec 20, 2021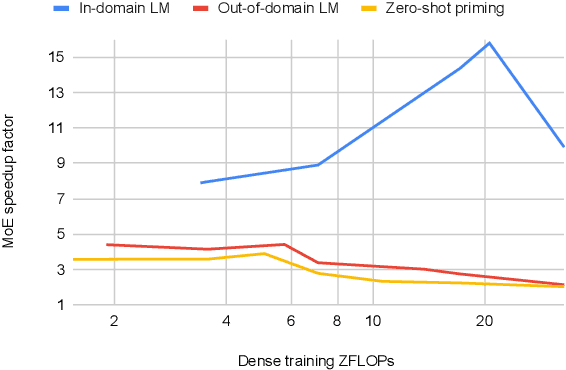
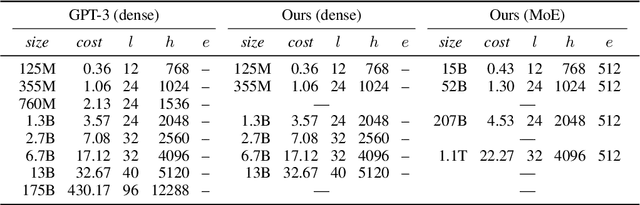
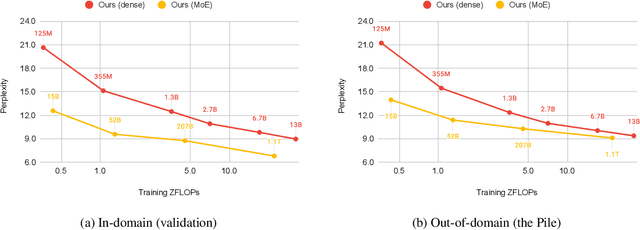
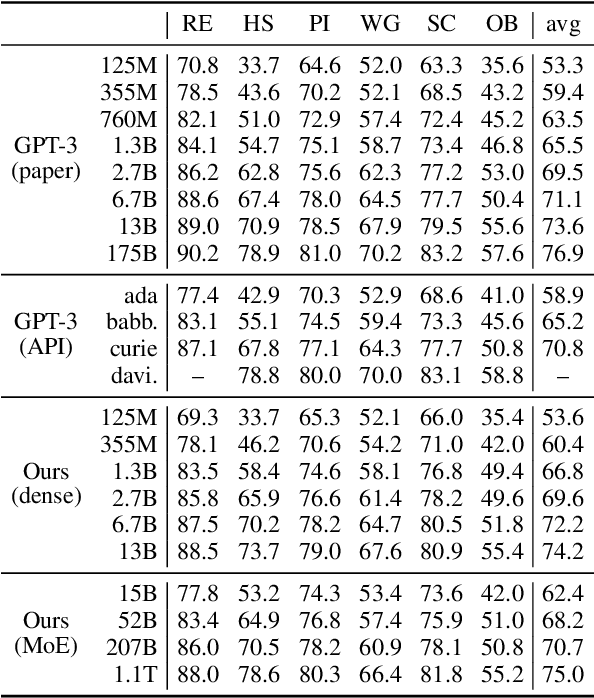
Mixture of Experts layers (MoEs) enable efficient scaling of language models through conditional computation. This paper presents a detailed empirical study of how autoregressive MoE language models scale in comparison with dense models in a wide range of settings: in- and out-of-domain language modeling, zero- and few-shot priming, and full fine-tuning. With the exception of fine-tuning, we find MoEs to be substantially more compute efficient. At more modest training budgets, MoEs can match the performance of dense models using $\sim$4 times less compute. This gap narrows at scale, but our largest MoE model (1.1T parameters) consistently outperforms a compute-equivalent dense model (6.7B parameters). Overall, this performance gap varies greatly across tasks and domains, suggesting that MoE and dense models generalize differently in ways that are worthy of future study. We make our code and models publicly available for research use.
Do Language Models Have Beliefs? Methods for Detecting, Updating, and Visualizing Model Beliefs
Nov 26, 2021

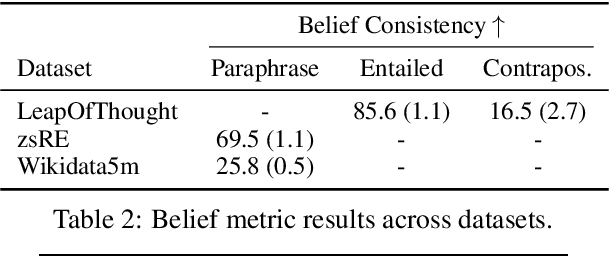
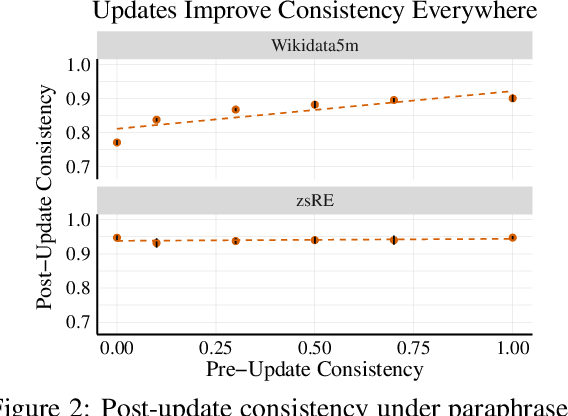
Do language models have beliefs about the world? Dennett (1995) famously argues that even thermostats have beliefs, on the view that a belief is simply an informational state decoupled from any motivational state. In this paper, we discuss approaches to detecting when models have beliefs about the world, and we improve on methods for updating model beliefs to be more truthful, with a focus on methods based on learned optimizers or hypernetworks. Our main contributions include: (1) new metrics for evaluating belief-updating methods that focus on the logical consistency of beliefs, (2) a training objective for Sequential, Local, and Generalizing model updates (SLAG) that improves the performance of learned optimizers, and (3) the introduction of the belief graph, which is a new form of interface with language models that shows the interdependencies between model beliefs. Our experiments suggest that models possess belief-like qualities to only a limited extent, but update methods can both fix incorrect model beliefs and greatly improve their consistency. Although off-the-shelf optimizers are surprisingly strong belief-updating baselines, our learned optimizers can outperform them in more difficult settings than have been considered in past work. Code is available at https://github.com/peterbhase/SLAG-Belief-Updating
EASE: Extractive-Abstractive Summarization with Explanations
May 14, 2021
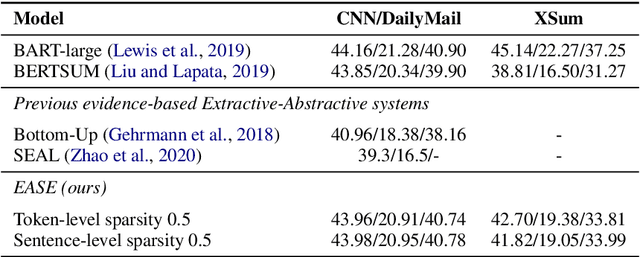
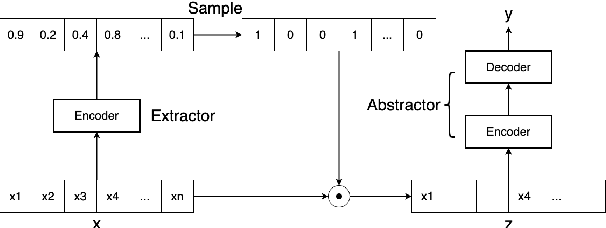
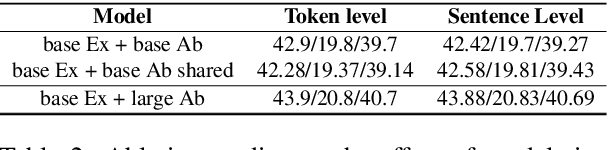
Current abstractive summarization systems outperform their extractive counterparts, but their widespread adoption is inhibited by the inherent lack of interpretability. To achieve the best of both worlds, we propose EASE, an extractive-abstractive framework for evidence-based text generation and apply it to document summarization. We present an explainable summarization system based on the Information Bottleneck principle that is jointly trained for extraction and abstraction in an end-to-end fashion. Inspired by previous research that humans use a two-stage framework to summarize long documents (Jing and McKeown, 2000), our framework first extracts a pre-defined amount of evidence spans as explanations and then generates a summary using only the evidence. Using automatic and human evaluations, we show that explanations from our framework are more relevant than simple baselines, without substantially sacrificing the quality of the generated summary.
FiD-Ex: Improving Sequence-to-Sequence Models for Extractive Rationale Generation
Dec 31, 2020
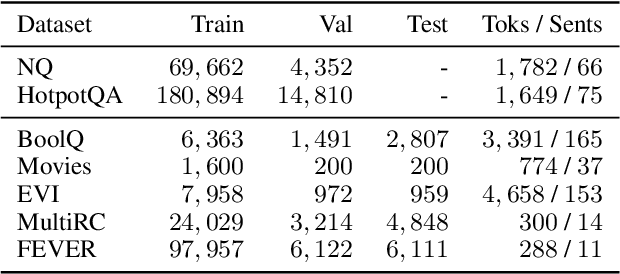
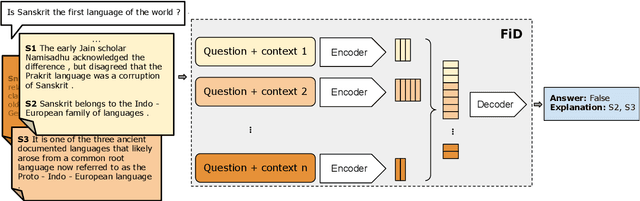
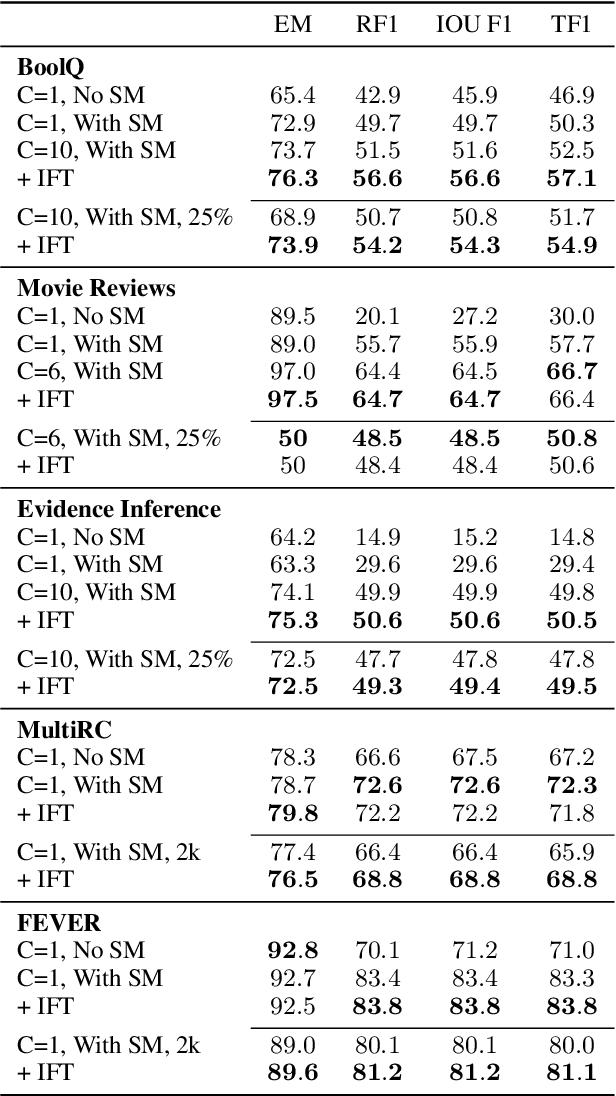
Natural language (NL) explanations of model predictions are gaining popularity as a means to understand and verify decisions made by large black-box pre-trained models, for NLP tasks such as Question Answering (QA) and Fact Verification. Recently, pre-trained sequence to sequence (seq2seq) models have proven to be very effective in jointly making predictions, as well as generating NL explanations. However, these models have many shortcomings; they can fabricate explanations even for incorrect predictions, they are difficult to adapt to long input documents, and their training requires a large amount of labeled data. In this paper, we develop FiD-Ex, which addresses these shortcomings for seq2seq models by: 1) introducing sentence markers to eliminate explanation fabrication by encouraging extractive generation, 2) using the fusion-in-decoder architecture to handle long input contexts, and 3) intermediate fine-tuning on re-structured open domain QA datasets to improve few-shot performance. FiD-Ex significantly improves over prior work in terms of explanation metrics and task accuracy, on multiple tasks from the ERASER explainability benchmark, both in the fully supervised and in the few-shot settings.