 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Factuality with Explicit Working Memory
Dec 24, 2024



Large language models can generate factually inaccurate content, a problem known as hallucination. Recent works have built upon retrieved-augmented generation to improve factuality through iterative prompting but these methods are limited by the traditional RAG design. To address these challenges, we introduce EWE (Explicit Working Memory), a novel approach that enhances factuality in long-form text generation by integrating a working memory that receives real-time feedback from external resources. The memory is refreshed based on online fact-checking and retrieval feedback, allowing EWE to rectify false claims during the generation process and ensure more accurate and reliable outputs. Our experiments demonstrate that Ewe outperforms strong baselines on four fact-seeking long-form generation datasets, increasing the factuality metric, VeriScore, by 2 to 10 points absolute without sacrificing the helpfulness of the responses. Further analysis reveals that the design of rules for memory updates, configurations of memory units, and the quality of the retrieval datastore are crucial factors for influencing model performance.
Memory Layers at Scale
Dec 12, 2024



Memory layers use a trainable key-value lookup mechanism to add extra parameters to a model without increasing FLOPs. Conceptually, sparsely activated memory layers complement compute-heavy dense feed-forward layers, providing dedicated capacity to store and retrieve information cheaply. This work takes memory layers beyond proof-of-concept, proving their utility at contemporary scale. On downstream tasks, language models augmented with our improved memory layer outperform dense models with more than twice the computation budget, as well as mixture-of-expert models when matched for both compute and parameters. We find gains are especially pronounced for factual tasks. We provide a fully parallelizable memory layer implementation, demonstrating scaling laws with up to 128B memory parameters, pretrained to 1 trillion tokens, comparing to base models with up to 8B parameters.
MoMa: Efficient Early-Fusion Pre-training with Mixture of Modality-Aware Experts
Jul 31, 2024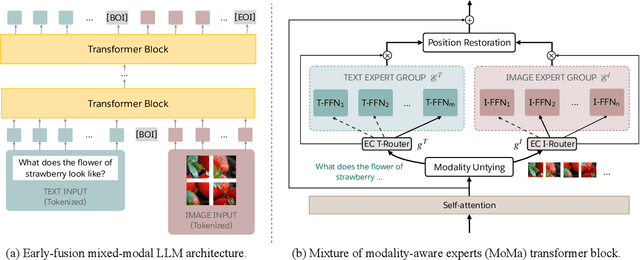

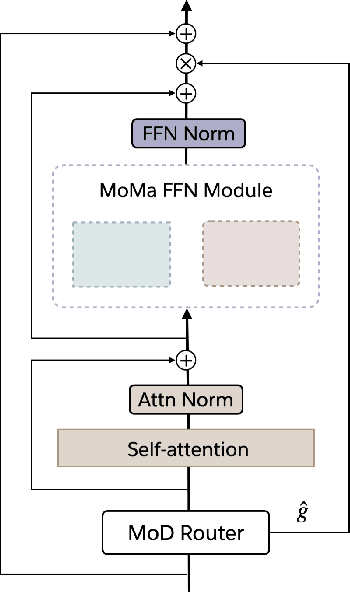
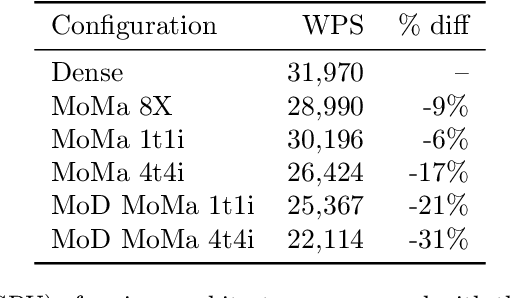
We introduce MoMa, a novel modality-aware mixture-of-experts (MoE) architecture designed for pre-training mixed-modal, early-fusion language models. MoMa processes images and text in arbitrary sequences by dividing expert modules into modality-specific groups. These groups exclusively process designated tokens while employing learned routing within each group to maintain semantically informed adaptivity. Our empirical results reveal substantial pre-training efficiency gains through this modality-specific parameter allocation. Under a 1-trillion-token training budget, the MoMa 1.4B model, featuring 4 text experts and 4 image experts, achieves impressive FLOPs savings: 3.7x overall, with 2.6x for text and 5.2x for image processing compared to a compute-equivalent dense baseline, measured by pre-training loss. This outperforms the standard expert-choice MoE with 8 mixed-modal experts, which achieves 3x overall FLOPs savings (3x for text, 2.8x for image). Combining MoMa with mixture-of-depths (MoD) further improves pre-training FLOPs savings to 4.2x overall (text: 3.4x, image: 5.3x), although this combination hurts performance in causal inference due to increased sensitivity to router accuracy. These results demonstrate MoMa's potential to significantly advance the efficiency of mixed-modal, early-fusion language model pre-training, paving the way for more resource-efficient and capable multimodal AI systems.
FLAP: Fast Language-Audio Pre-training
Nov 02, 2023We propose Fast Language-Audio Pre-training (FLAP), a self-supervised approach that efficiently and effectively learns aligned audio and language representations through masking, contrastive learning and reconstruction. For efficiency, FLAP randomly drops audio spectrogram tokens, focusing solely on the remaining ones for self-supervision. Through inter-modal contrastive learning, FLAP learns to align paired audio and text representations in a shared latent space. Notably, FLAP leverages multiple augmented views via masking for inter-modal contrast and learns to reconstruct the masked portion of audio tokens. Moreover, FLAP leverages large language models (LLMs) to augment the text inputs, contributing to improved performance. These approaches lead to more robust and informative audio-text representations, enabling FLAP to achieve state-of-the-art (SoTA) performance on audio-text retrieval tasks on AudioCaps (achieving 53.0% R@1) and Clotho (achieving 25.5% R@1).