 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Reason for Factuality
Aug 07, 2025Reasoning Large Language Models (R-LLMs) have significantly advanced complex reasoning tasks but often struggle with factuality, generating substantially more hallucinations than their non-reasoning counterparts on long-form factuality benchmarks. However, extending online Reinforcement Learning (RL), a key component in recent R-LLM advancements, to the long-form factuality setting poses several unique challenges due to the lack of reliable verification methods. Previous work has utilized automatic factuality evaluation frameworks such as FActScore to curate preference data in the offline RL setting, yet we find that directly leveraging such methods as the reward in online RL leads to reward hacking in multiple ways, such as producing less detailed or relevant responses. We propose a novel reward function that simultaneously considers the factual precision, response detail level, and answer relevance, and applies online RL to learn high quality factual reasoning. Evaluated on six long-form factuality benchmarks, our factual reasoning model achieves an average reduction of 23.1 percentage points in hallucination rate, a 23% increase in answer detail level, and no degradation in the overall response helpfulness.
Memory Layers at Scale
Dec 12, 2024



Memory layers use a trainable key-value lookup mechanism to add extra parameters to a model without increasing FLOPs. Conceptually, sparsely activated memory layers complement compute-heavy dense feed-forward layers, providing dedicated capacity to store and retrieve information cheaply. This work takes memory layers beyond proof-of-concept, proving their utility at contemporary scale. On downstream tasks, language models augmented with our improved memory layer outperform dense models with more than twice the computation budget, as well as mixture-of-expert models when matched for both compute and parameters. We find gains are especially pronounced for factual tasks. We provide a fully parallelizable memory layer implementation, demonstrating scaling laws with up to 128B memory parameters, pretrained to 1 trillion tokens, comparing to base models with up to 8B parameters.
Text-guided 3D Human Generation from 2D Collections
May 23, 2023
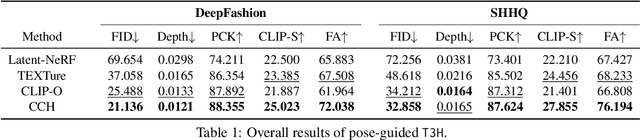
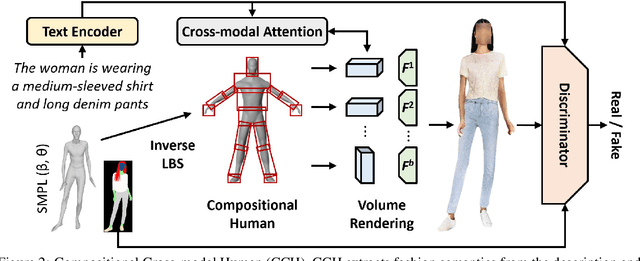
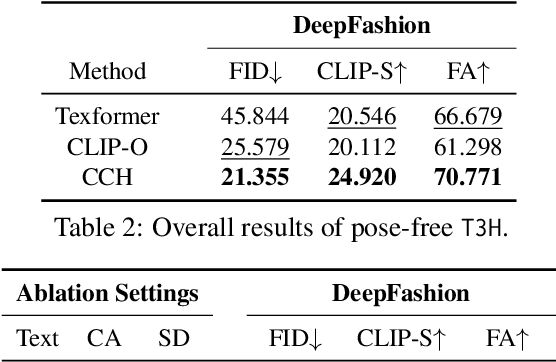
3D human modeling has been widely used for engaging interaction in gaming, film, and animation. The customization of these characters is crucial for creativity and scalability, which highlights the importance of controllability. In this work, we introduce Text-guided 3D Human Generation (\texttt{T3H}), where a model is to generate a 3D human, guided by the fashion description. There are two goals: 1) the 3D human should render articulately, and 2) its outfit is controlled by the given text. To address this \texttt{T3H} task, we propose Compositional Cross-modal Human (CCH). CCH adopts cross-modal attention to fuse compositional human rendering with the extracted fashion semantics. Each human body part perceives relevant textual guidance as its visual patterns. We incorporate the human prior and semantic discrimination to enhance 3D geometry transformation and fine-grained consistency, enabling it to learn from 2D collections for data efficiency. We conduct evaluations on DeepFashion and SHHQ with diverse fashion attributes covering the shape, fabric, and color of upper and lower clothing. Extensive experiments demonstrate that CCH achieves superior results for \texttt{T3H} with high efficiency.
VideoOFA: Two-Stage Pre-Training for Video-to-Text Generation
May 04, 2023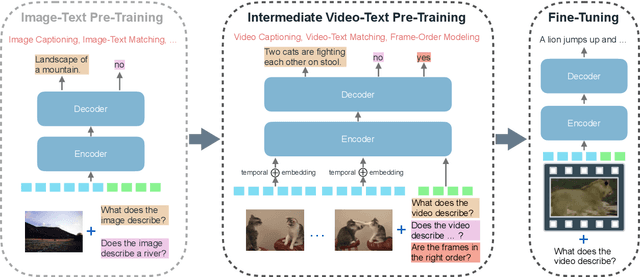
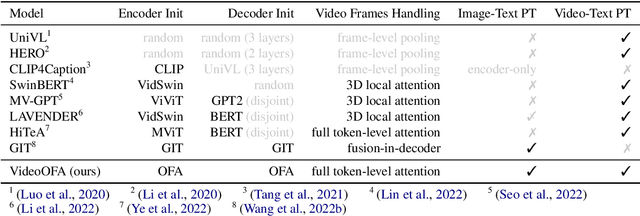
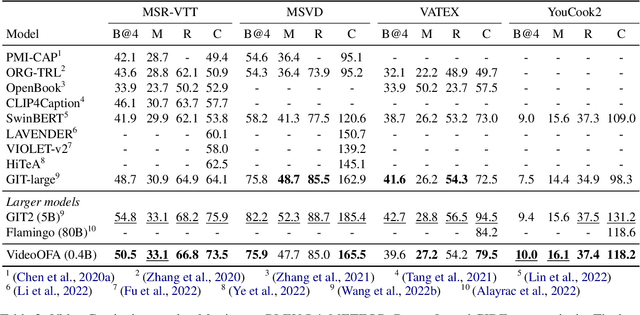

We propose a new two-stage pre-training framework for video-to-text generation tasks such as video captioning and video question answering: A generative encoder-decoder model is first jointly pre-trained on massive image-text data to learn fundamental vision-language concepts, and then adapted to video data in an intermediate video-text pre-training stage to learn video-specific skills such as spatio-temporal reasoning. As a result, our VideoOFA model achieves new state-of-the-art performance on four Video Captioning benchmarks, beating prior art by an average of 9.7 points in CIDEr score. It also outperforms existing models on two open-ended Video Question Answering datasets, showcasing its generalization capability as a universal video-to-text model.
Hierarchical Video-Moment Retrieval and Step-Captioning
Mar 29, 2023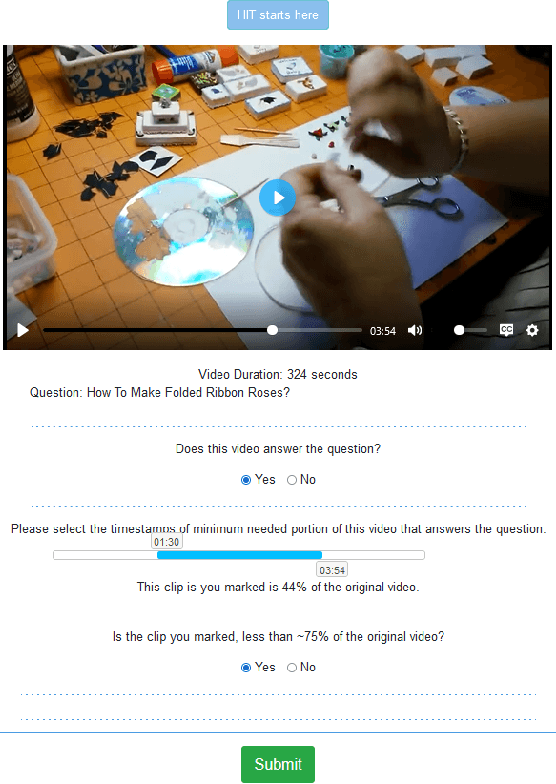

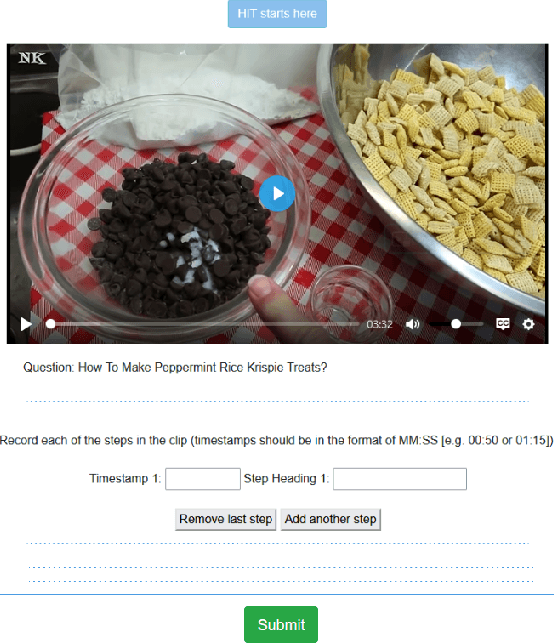
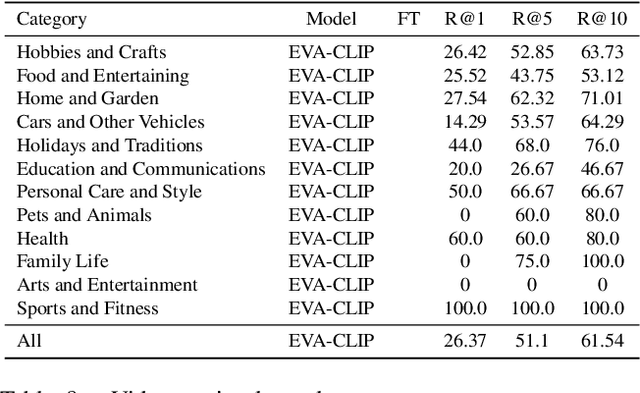
There is growing interest in searching for information from large video corpora. Prior works have studied relevant tasks, such as text-based video retrieval, moment retrieval, video summarization, and video captioning in isolation, without an end-to-end setup that can jointly search from video corpora and generate summaries. Such an end-to-end setup would allow for many interesting applications, e.g., a text-based search that finds a relevant video from a video corpus, extracts the most relevant moment from that video, and segments the moment into important steps with captions. To address this, we present the HiREST (HIerarchical REtrieval and STep-captioning) dataset and propose a new benchmark that covers hierarchical information retrieval and visual/textual stepwise summarization from an instructional video corpus. HiREST consists of 3.4K text-video pairs from an instructional video dataset, where 1.1K videos have annotations of moment spans relevant to text query and breakdown of each moment into key instruction steps with caption and timestamps (totaling 8.6K step captions). Our hierarchical benchmark consists of video retrieval, moment retrieval, and two novel moment segmentation and step captioning tasks. In moment segmentation, models break down a video moment into instruction steps and identify start-end boundaries. In step captioning, models generate a textual summary for each step. We also present starting point task-specific and end-to-end joint baseline models for our new benchmark. While the baseline models show some promising results, there still exists large room for future improvement by the community. Project website: https://hirest-cvpr2023.github.io
3DGen: Triplane Latent Diffusion for Textured Mesh Generation
Mar 09, 2023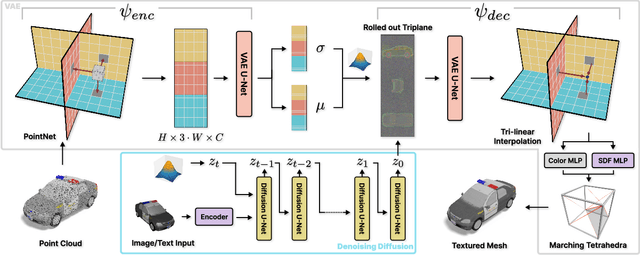
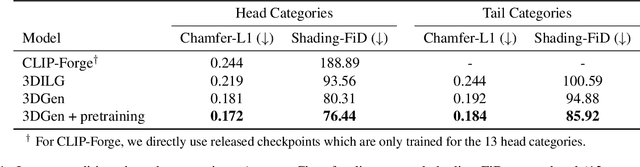

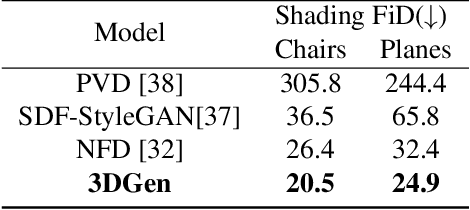
Latent diffusion models for image generation have crossed a quality threshold which enabled them to achieve mass adoption. Recently, a series of works have made advancements towards replicating this success in the 3D domain, introducing techniques such as point cloud VAE, triplane representation, neural implicit surfaces and differentiable rendering based training. We take another step along this direction, combining these developments in a two-step pipeline consisting of 1) a triplane VAE which can learn latent representations of textured meshes and 2) a conditional diffusion model which generates the triplane features. For the first time this architecture allows conditional and unconditional generation of high quality textured or untextured 3D meshes across multiple diverse categories in a few seconds on a single GPU. It outperforms previous work substantially on image-conditioned and unconditional generation on mesh quality as well as texture generation. Furthermore, we demonstrate the scalability of our model to large datasets for increased quality and diversity. We will release our code and trained models.
CLIP-Layout: Style-Consistent Indoor Scene Synthesis with Semantic Furniture Embedding
Mar 07, 2023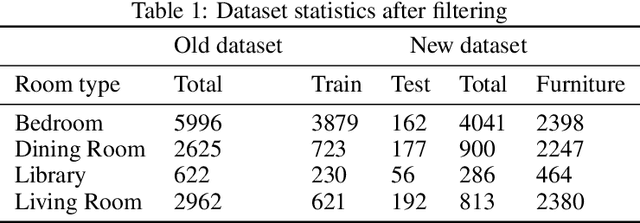



Indoor scene synthesis involves automatically picking and placing furniture appropriately on a floor plan, so that the scene looks realistic and is functionally plausible. Such scenes can serve as a home for immersive 3D experiences, or be used to train embodied agents. Existing methods for this task rely on labeled categories of furniture, e.g. bed, chair or table, to generate contextually relevant combinations of furniture. Whether heuristic or learned, these methods ignore instance-level attributes of objects such as color and style, and as a result may produce visually less coherent scenes. In this paper, we introduce an auto-regressive scene model which can output instance-level predictions, making use of general purpose image embedding based on CLIP. This allows us to learn visual correspondences such as matching color and style, and produce more plausible and aesthetically pleasing scenes. Evaluated on the 3D-FRONT dataset, our model achieves SOTA results in scene generation and improves auto-completion metrics by over 50%. Moreover, our embedding-based approach enables zero-shot text-guided scene generation and editing, which easily generalizes to furniture not seen at training time.
The Web Is Your Oyster -- Knowledge-Intensive NLP against a Very Large Web Corpus
Dec 18, 2021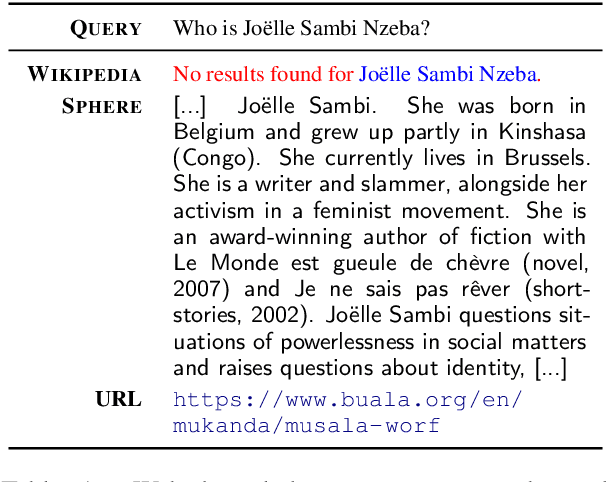
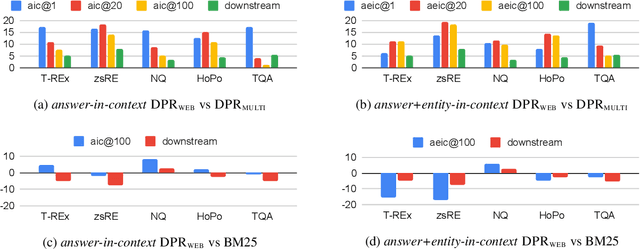
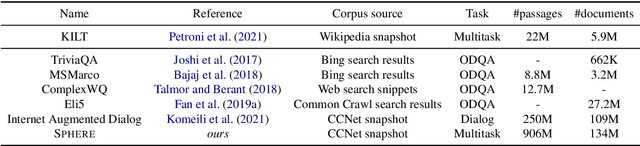
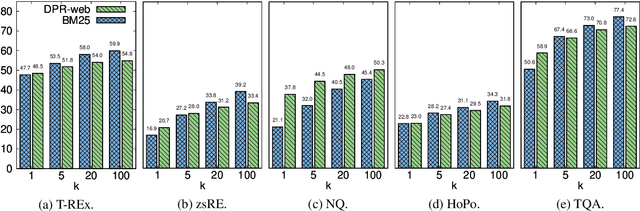
In order to address the increasing demands of real-world applications, the research for knowledge-intensive NLP (KI-NLP) should advance by capturing the challenges of a truly open-domain environment: web scale knowledge, lack of structure, inconsistent quality, and noise. To this end, we propose a new setup for evaluating existing KI-NLP tasks in which we generalize the background corpus to a universal web snapshot. We repurpose KILT, a standard KI-NLP benchmark initially developed for Wikipedia, and ask systems to use a subset of CCNet - the Sphere corpus - as a knowledge source. In contrast to Wikipedia, Sphere is orders of magnitude larger and better reflects the full diversity of knowledge on the Internet. We find that despite potential gaps of coverage, challenges of scale, lack of structure and lower quality, retrieval from Sphere enables a state-of-the-art retrieve-and-read system to match and even outperform Wikipedia-based models on several KILT tasks - even if we aggressively filter content that looks like Wikipedia. We also observe that while a single dense passage index over Wikipedia can outperform a sparse BM25 version, on Sphere this is not yet possible. To facilitate further research into this area, and minimise the community's reliance on proprietary black box search engines, we will share our indices, evaluation metrics and infrastructure.
Boosted Dense Retriever
Dec 14, 2021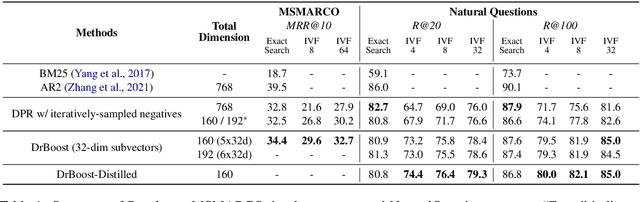
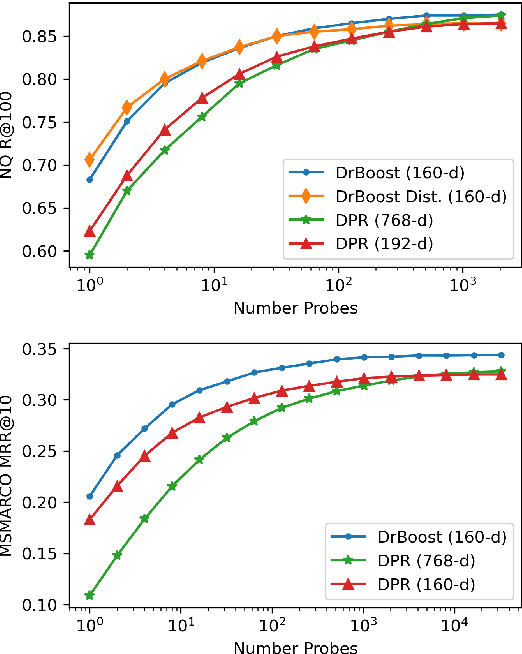
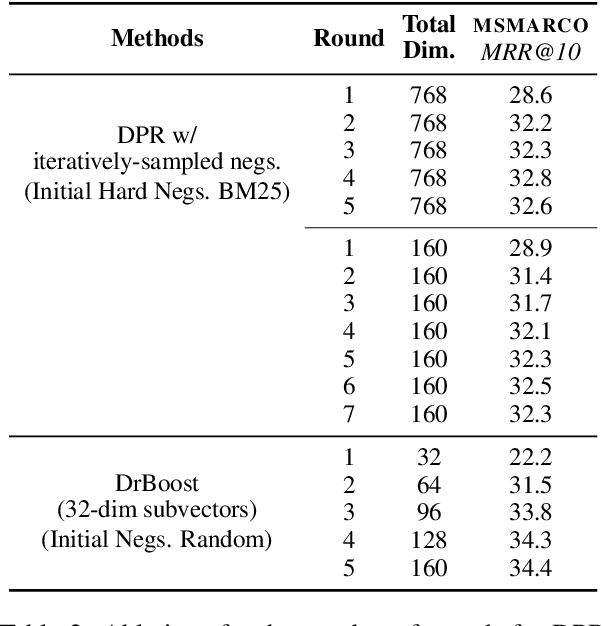
We propose DrBoost, a dense retrieval ensemble inspired by boosting. DrBoost is trained in stages: each component model is learned sequentially and specialized by focusing only on retrieval mistakes made by the current ensemble. The final representation is the concatenation of the output vectors of all the component models, making it a drop-in replacement for standard dense retrievers at test time. DrBoost enjoys several advantages compared to standard dense retrieval models. It produces representations which are 4x more compact, while delivering comparable retrieval results. It also performs surprisingly well under approximate search with coarse quantization, reducing latency and bandwidth needs by another 4x. In practice, this can make the difference between serving indices from disk versus from memory, paving the way for much cheaper deployments.
Simple Local Attentions Remain Competitive for Long-Context Tasks
Dec 14, 2021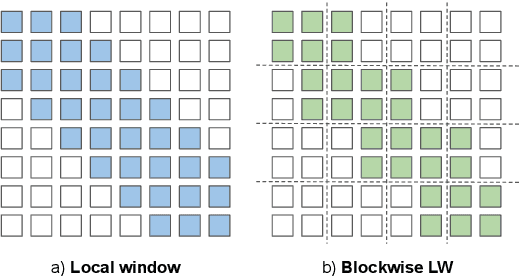
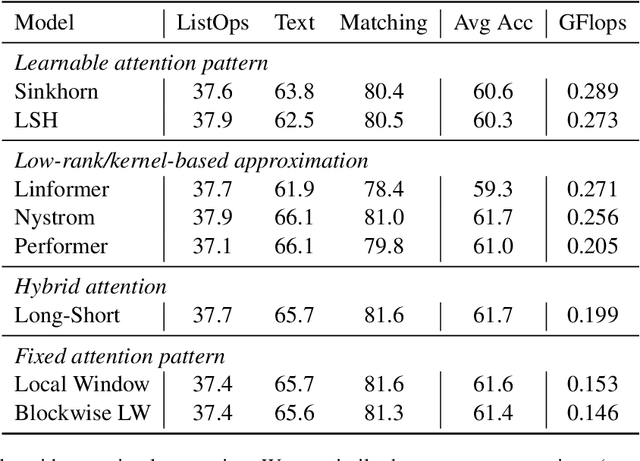
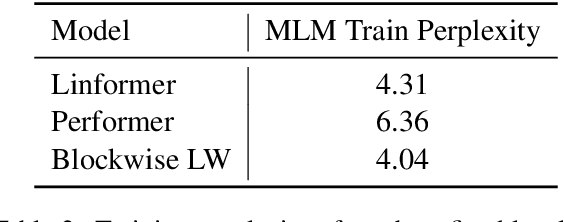
Many NLP tasks require processing long contexts beyond the length limit of pretrained models. In order to scale these models to longer text sequences, many efficient long-range attention variants have been proposed. Despite the abundance of research along this direction, it is still difficult to gauge the relative effectiveness of these models in practical use cases, e.g., if we apply these models following the pretrain-and-finetune paradigm. In this work, we aim to conduct a thorough analysis of these emerging models with large-scale and controlled experiments. For each attention variant, we pretrain large-size models using the same long-doc corpus and then finetune these models for real-world long-context tasks. Our findings reveal pitfalls of an existing widely-used long-range benchmark and show none of the tested efficient attentions can beat a simple local window attention under standard pretraining paradigms. Further analysis on local attention variants suggests that even the commonly used attention-window overlap is not necessary to achieve good downstream results -- using disjoint local attentions, we are able to build a simpler and more efficient long-doc QA model that matches the performance of Longformer~\citep{longformer} with half of its pretraining compute.