 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge3DGen: Triplane Latent Diffusion for Textured Mesh Generation
Mar 09, 2023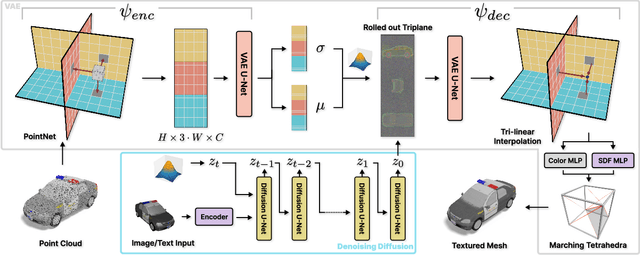
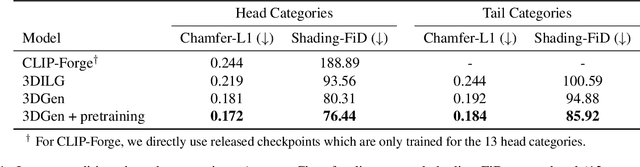

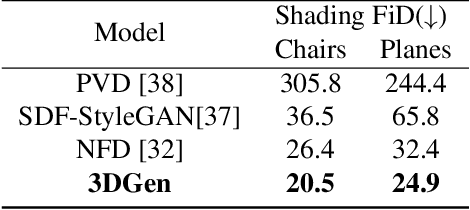
Latent diffusion models for image generation have crossed a quality threshold which enabled them to achieve mass adoption. Recently, a series of works have made advancements towards replicating this success in the 3D domain, introducing techniques such as point cloud VAE, triplane representation, neural implicit surfaces and differentiable rendering based training. We take another step along this direction, combining these developments in a two-step pipeline consisting of 1) a triplane VAE which can learn latent representations of textured meshes and 2) a conditional diffusion model which generates the triplane features. For the first time this architecture allows conditional and unconditional generation of high quality textured or untextured 3D meshes across multiple diverse categories in a few seconds on a single GPU. It outperforms previous work substantially on image-conditioned and unconditional generation on mesh quality as well as texture generation. Furthermore, we demonstrate the scalability of our model to large datasets for increased quality and diversity. We will release our code and trained models.
CLIP-Layout: Style-Consistent Indoor Scene Synthesis with Semantic Furniture Embedding
Mar 07, 2023



Indoor scene synthesis involves automatically picking and placing furniture appropriately on a floor plan, so that the scene looks realistic and is functionally plausible. Such scenes can serve as a home for immersive 3D experiences, or be used to train embodied agents. Existing methods for this task rely on labeled categories of furniture, e.g. bed, chair or table, to generate contextually relevant combinations of furniture. Whether heuristic or learned, these methods ignore instance-level attributes of objects such as color and style, and as a result may produce visually less coherent scenes. In this paper, we introduce an auto-regressive scene model which can output instance-level predictions, making use of general purpose image embedding based on CLIP. This allows us to learn visual correspondences such as matching color and style, and produce more plausible and aesthetically pleasing scenes. Evaluated on the 3D-FRONT dataset, our model achieves SOTA results in scene generation and improves auto-completion metrics by over 50%. Moreover, our embedding-based approach enables zero-shot text-guided scene generation and editing, which easily generalizes to furniture not seen at training time.