 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePaying Less Generalization Tax: A Cross-Domain Generalization Study of RL Training for LLM Agents
Jan 26, 2026Generalist LLM agents are often post-trained on a narrow set of environments but deployed across far broader, unseen domains. In this work, we investigate the challenge of agentic post-training when the eventual test domains are unknown. Specifically, we analyze which properties of reinforcement learning (RL) environments and modeling choices have the greatest influence on out-of-domain performance. First, we identify two environment axes that strongly correlate with cross-domain generalization: (i) state information richness, i.e., the amount of information for the agent to process from the state, and (ii) planning complexity, estimated via goal reachability and trajectory length under a base policy. Notably, domain realism and text-level similarity are not the primary factors; for instance, the simple grid-world domain Sokoban leads to even stronger generalization in SciWorld than the more realistic ALFWorld. Motivated by these findings, we further show that increasing state information richness alone can already effectively improve cross-domain robustness. We propose a randomization technique, which is low-overhead and broadly applicable: add small amounts of distractive goal-irrelevant features to the state to make it richer without altering the task. Beyond environment-side properties, we also examine several modeling choices: (a) SFT warmup or mid-training helps prevent catastrophic forgetting during RL but undermines generalization to domains that are not included in the mid-training datamix; and (b) turning on step-by-step thinking during RL, while not always improving in-domain performance, plays a crucial role in preserving generalization.
ROICtrl: Boosting Instance Control for Visual Generation
Nov 27, 2024



Natural language often struggles to accurately associate positional and attribute information with multiple instances, which limits current text-based visual generation models to simpler compositions featuring only a few dominant instances. To address this limitation, this work enhances diffusion models by introducing regional instance control, where each instance is governed by a bounding box paired with a free-form caption. Previous methods in this area typically rely on implicit position encoding or explicit attention masks to separate regions of interest (ROIs), resulting in either inaccurate coordinate injection or large computational overhead. Inspired by ROI-Align in object detection, we introduce a complementary operation called ROI-Unpool. Together, ROI-Align and ROI-Unpool enable explicit, efficient, and accurate ROI manipulation on high-resolution feature maps for visual generation. Building on ROI-Unpool, we propose ROICtrl, an adapter for pretrained diffusion models that enables precise regional instance control. ROICtrl is compatible with community-finetuned diffusion models, as well as with existing spatial-based add-ons (\eg, ControlNet, T2I-Adapter) and embedding-based add-ons (\eg, IP-Adapter, ED-LoRA), extending their applications to multi-instance generation. Experiments show that ROICtrl achieves superior performance in regional instance control while significantly reducing computational costs.
Scene-LLM: Extending Language Model for 3D Visual Understanding and Reasoning
Mar 22, 2024



This paper introduces Scene-LLM, a 3D-visual-language model that enhances embodied agents' abilities in interactive 3D indoor environments by integrating the reasoning strengths of Large Language Models (LLMs). Scene-LLM adopts a hybrid 3D visual feature representation, that incorporates dense spatial information and supports scene state updates. The model employs a projection layer to efficiently project these features in the pre-trained textual embedding space, enabling effective interpretation of 3D visual information. Unique to our approach is the integration of both scene-level and ego-centric 3D information. This combination is pivotal for interactive planning, where scene-level data supports global planning and ego-centric data is important for localization. Notably, we use ego-centric 3D frame features for feature alignment, an efficient technique that enhances the model's ability to align features of small objects within the scene. Our experiments with Scene-LLM demonstrate its strong capabilities in dense captioning, question answering, and interactive planning. We believe Scene-LLM advances the field of 3D visual understanding and reasoning, offering new possibilities for sophisticated agent interactions in indoor settings.
The Role of Chain-of-Thought in Complex Vision-Language Reasoning Task
Nov 15, 2023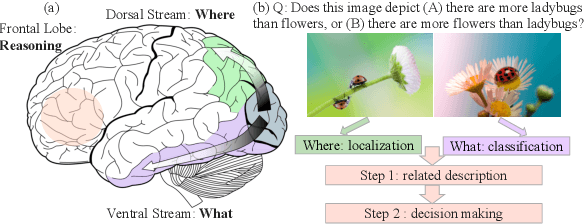



The study explores the effectiveness of the Chain-of-Thought approach, known for its proficiency in language tasks by breaking them down into sub-tasks and intermediate steps, in improving vision-language tasks that demand sophisticated perception and reasoning. We present the "Description then Decision" strategy, which is inspired by how humans process signals. This strategy significantly improves probing task performance by 50%, establishing the groundwork for future research on reasoning paradigms in complex vision-language tasks.
Jointly Training Large Autoregressive Multimodal Models
Sep 28, 2023
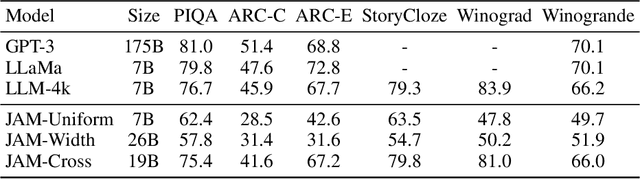
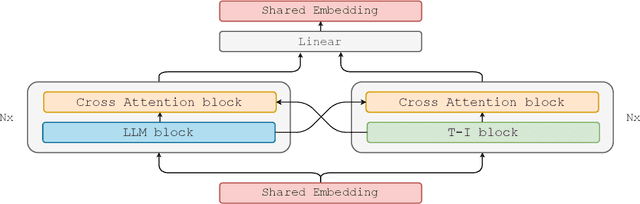
In recent years, advances in the large-scale pretraining of language and text-to-image models have revolutionized the field of machine learning. Yet, integrating these two modalities into a single, robust model capable of generating seamless multimodal outputs remains a significant challenge. To address this gap, we present the Joint Autoregressive Mixture (JAM) framework, a modular approach that systematically fuses existing text and image generation models. We also introduce a specialized, data-efficient instruction-tuning strategy, tailored for mixed-modal generation tasks. Our final instruct-tuned model demonstrates unparalleled performance in generating high-quality multimodal outputs and represents the first model explicitly designed for this purpose.
Llama 2: Open Foundation and Fine-Tuned Chat Models
Jul 19, 2023



In this work, we develop and release Llama 2, a collection of pretrained and fine-tuned large language models (LLMs) ranging in scale from 7 billion to 70 billion parameters. Our fine-tuned LLMs, called Llama 2-Chat, are optimized for dialogue use cases. Our models outperform open-source chat models on most benchmarks we tested, and based on our human evaluations for helpfulness and safety, may be a suitable substitute for closed-source models. We provide a detailed description of our approach to fine-tuning and safety improvements of Llama 2-Chat in order to enable the community to build on our work and contribute to the responsible development of LLMs.
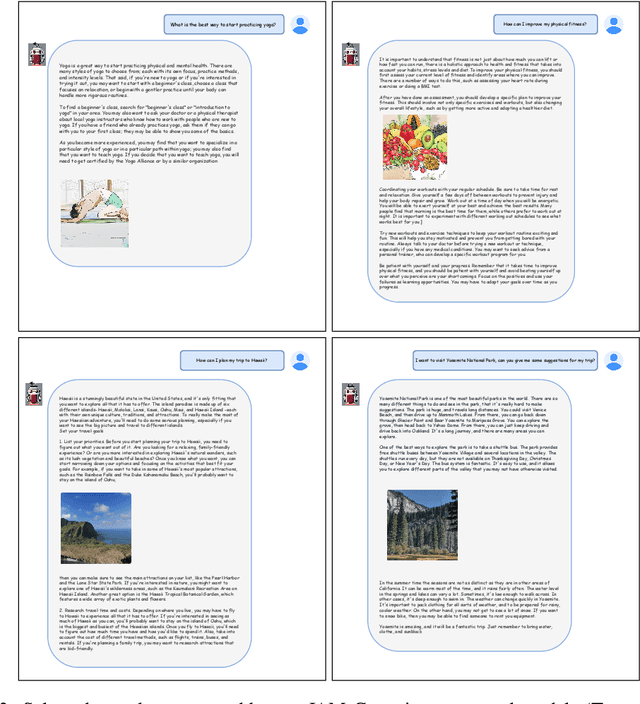
Text-guided 3D Human Generation from 2D Collections
May 23, 2023
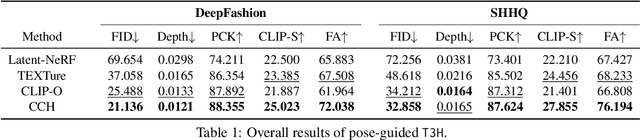
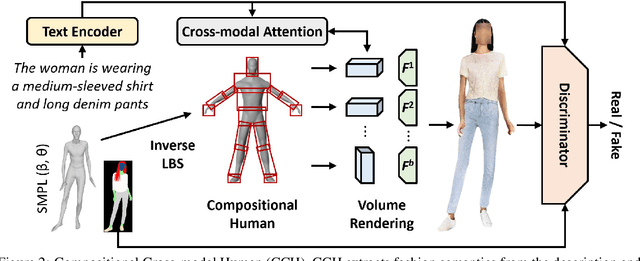
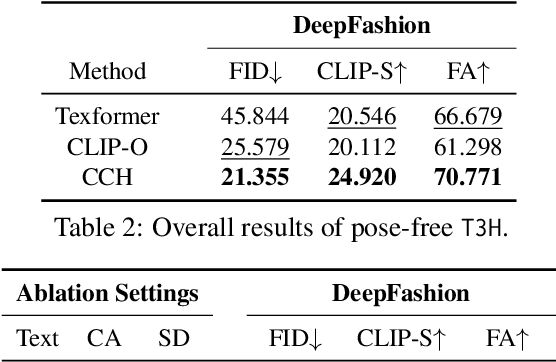
3D human modeling has been widely used for engaging interaction in gaming, film, and animation. The customization of these characters is crucial for creativity and scalability, which highlights the importance of controllability. In this work, we introduce Text-guided 3D Human Generation (\texttt{T3H}), where a model is to generate a 3D human, guided by the fashion description. There are two goals: 1) the 3D human should render articulately, and 2) its outfit is controlled by the given text. To address this \texttt{T3H} task, we propose Compositional Cross-modal Human (CCH). CCH adopts cross-modal attention to fuse compositional human rendering with the extracted fashion semantics. Each human body part perceives relevant textual guidance as its visual patterns. We incorporate the human prior and semantic discrimination to enhance 3D geometry transformation and fine-grained consistency, enabling it to learn from 2D collections for data efficiency. We conduct evaluations on DeepFashion and SHHQ with diverse fashion attributes covering the shape, fabric, and color of upper and lower clothing. Extensive experiments demonstrate that CCH achieves superior results for \texttt{T3H} with high efficiency.
TTIDA: Controllable Generative Data Augmentation via Text-to-Text and Text-to-Image Models
Apr 18, 2023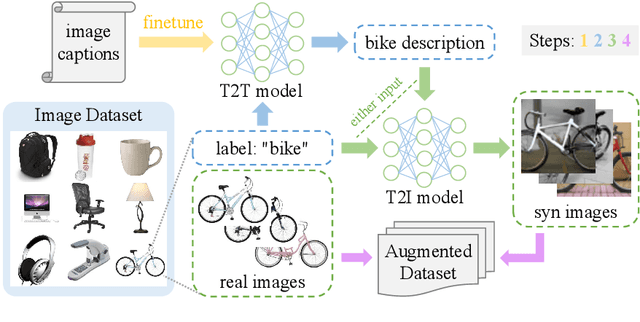
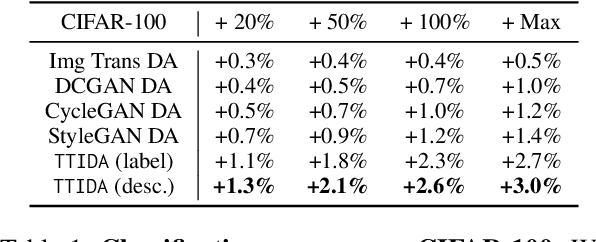
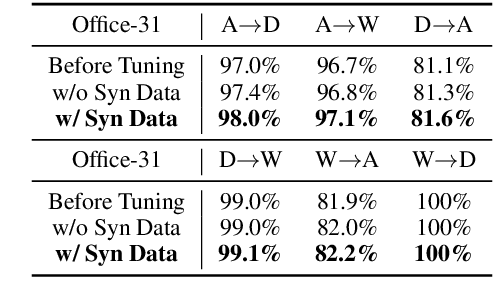
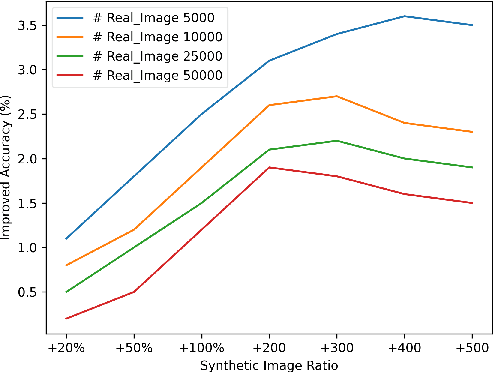
Data augmentation has been established as an efficacious approach to supplement useful information for low-resource datasets. Traditional augmentation techniques such as noise injection and image transformations have been widely used. In addition, generative data augmentation (GDA) has been shown to produce more diverse and flexible data. While generative adversarial networks (GANs) have been frequently used for GDA, they lack diversity and controllability compared to text-to-image diffusion models. In this paper, we propose TTIDA (Text-to-Text-to-Image Data Augmentation) to leverage the capabilities of large-scale pre-trained Text-to-Text (T2T) and Text-to-Image (T2I) generative models for data augmentation. By conditioning the T2I model on detailed descriptions produced by T2T models, we are able to generate photo-realistic labeled images in a flexible and controllable manner. Experiments on in-domain classification, cross-domain classification, and image captioning tasks show consistent improvements over other data augmentation baselines. Analytical studies in varied settings, including few-shot, long-tail, and adversarial, further reinforce the effectiveness of TTIDA in enhancing performance and increasing robustness.
3DGen: Triplane Latent Diffusion for Textured Mesh Generation
Mar 09, 2023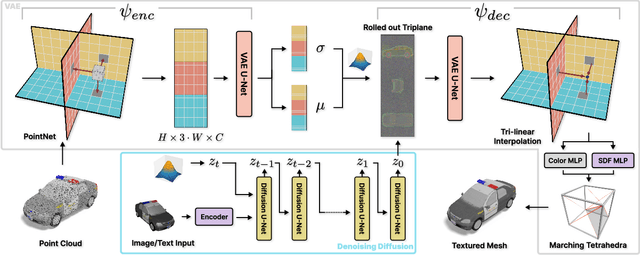
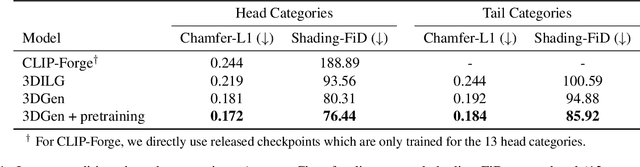

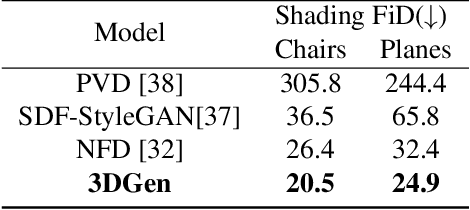
Latent diffusion models for image generation have crossed a quality threshold which enabled them to achieve mass adoption. Recently, a series of works have made advancements towards replicating this success in the 3D domain, introducing techniques such as point cloud VAE, triplane representation, neural implicit surfaces and differentiable rendering based training. We take another step along this direction, combining these developments in a two-step pipeline consisting of 1) a triplane VAE which can learn latent representations of textured meshes and 2) a conditional diffusion model which generates the triplane features. For the first time this architecture allows conditional and unconditional generation of high quality textured or untextured 3D meshes across multiple diverse categories in a few seconds on a single GPU. It outperforms previous work substantially on image-conditioned and unconditional generation on mesh quality as well as texture generation. Furthermore, we demonstrate the scalability of our model to large datasets for increased quality and diversity. We will release our code and trained models.
CLIP-Layout: Style-Consistent Indoor Scene Synthesis with Semantic Furniture Embedding
Mar 07, 2023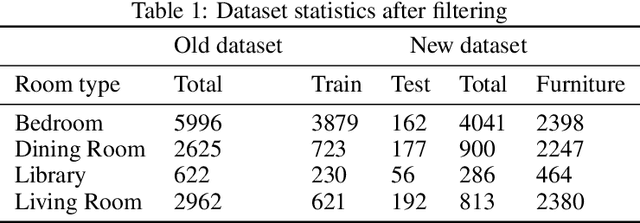



Indoor scene synthesis involves automatically picking and placing furniture appropriately on a floor plan, so that the scene looks realistic and is functionally plausible. Such scenes can serve as a home for immersive 3D experiences, or be used to train embodied agents. Existing methods for this task rely on labeled categories of furniture, e.g. bed, chair or table, to generate contextually relevant combinations of furniture. Whether heuristic or learned, these methods ignore instance-level attributes of objects such as color and style, and as a result may produce visually less coherent scenes. In this paper, we introduce an auto-regressive scene model which can output instance-level predictions, making use of general purpose image embedding based on CLIP. This allows us to learn visual correspondences such as matching color and style, and produce more plausible and aesthetically pleasing scenes. Evaluated on the 3D-FRONT dataset, our model achieves SOTA results in scene generation and improves auto-completion metrics by over 50%. Moreover, our embedding-based approach enables zero-shot text-guided scene generation and editing, which easily generalizes to furniture not seen at training time.